 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Code Review as a Scaffold for Code Quality and Self-Regulated Learning: An Experience Report
Apr 25, 2026Code review is central to software engineering education but hard to scale in capstone projects due to tight deadlines, uneven peer feedback, and limited prior experience. We investigate an LLM-as-reviewer integrated directly into GitHub pull requests (human-in-the-loop) across two cohorts (more than 100 students, 2023--2024). Using a mixed-methods design -- GitHub data, reflective reports, and a targeted survey -- we examine engagement and responsiveness as behavioral indicators of self-regulated learning processes. Quantitatively, the 2024 cohort produced more iterative activity (1176 vs. 581 PRs), while technical issues observed in 2023 (227 failed AI attempts) dropped to zero after tool and instructional refinements. Despite different adoption levels (93\% vs. 50\% of teams using the tool), responsiveness was stable: 32\% (2023) and 33\% (2024) of successfully AI-reviewed PRs were followed by subsequent commits on the same PR. Qualitatively, students used the LLM's structured comments to focus reviews and discuss code quality, while guidance reduced over-reliance. We contribute: (i) an in-workflow design for an AI reviewer that scaffolds learning while mitigating cognitive offloading; (ii) a repeated cross sectional comparison across two cohorts in authentic settings; (iii) a mixed-methods analysis combining objective GitHub metrics with student self-reports; and (iv) evidence-based pedagogical recommendations for responsible, student-led AI-assisted review.
IntelliSA: An Intelligent Static Analyzer for IaC Security Smell Detection Using Symbolic Rules and Neural Inference
Jan 21, 2026Infrastructure as Code (IaC) enables automated provisioning of large-scale cloud and on-premise environments, reducing the need for repetitive manual setup. However, this automation is a double-edged sword: a single misconfiguration in IaC scripts can propagate widely, leading to severe system downtime and security risks. Prior studies have shown that IaC scripts often contain security smells--bad coding patterns that may introduce vulnerabilities--and have proposed static analyzers based on symbolic rules to detect them. Yet, our preliminary analysis reveals that rule-based detection alone tends to over-approximate, producing excessive false positives and increasing the burden of manual inspection. In this paper, we present IntelliSA, an intelligent static analyzer for IaC security smell detection that integrates symbolic rules with neural inference. IntelliSA applies symbolic rules to over-approximate potential smells for broad coverage, then employs neural inference to filter false positives. While an LLM can effectively perform this filtering, reliance on LLM APIs introduces high cost and latency, raises data governance concerns, and limits reproducibility and offline deployment. To address the challenges, we adopt a knowledge distillation approach: an LLM teacher generates pseudo-labels to train a compact student model--over 500x smaller--that learns from the teacher's knowledge and efficiently classifies false positives. We evaluate IntelliSA against two static analyzers and three LLM baselines (Claude-4, Grok-4, and GPT-5) using a human-labeled dataset including 241 security smells across 11,814 lines of real-world IaC code. Experimental results show that IntelliSA achieves the highest F1 score (83%), outperforming baselines by 7-42%. Moreover, IntelliSA demonstrates the best cost-effectiveness, detecting 60% of security smells while inspecting less than 2% of the codebase.
AI for DevSecOps: A Landscape and Future Opportunities
Apr 07, 2024



DevOps has emerged as one of the most rapidly evolving software development paradigms. With the growing concerns surrounding security in software systems, the DevSecOps paradigm has gained prominence, urging practitioners to incorporate security practices seamlessly into the DevOps workflow. However, integrating security into the DevOps workflow can impact agility and impede delivery speed. Recently, the advancement of artificial intelligence (AI) has revolutionized automation in various software domains, including software security. AI-driven security approaches, particularly those leveraging machine learning or deep learning, hold promise in automating security workflows. They reduce manual efforts, which can be integrated into DevOps to ensure uninterrupted delivery speed and align with the DevSecOps paradigm simultaneously. This paper seeks to contribute to the critical intersection of AI and DevSecOps by presenting a comprehensive landscape of AI-driven security techniques applicable to DevOps and identifying avenues for enhancing security, trust, and efficiency in software development processes. We analyzed 99 research papers spanning from 2017 to 2023. Specifically, we address two key research questions (RQs). In RQ1, we identified 12 security tasks associated with the DevOps process and reviewed existing AI-driven security approaches. In RQ2, we discovered 15 challenges encountered by existing AI-driven security approaches and derived future research opportunities. Drawing insights from our findings, we discussed the state-of-the-art AI-driven security approaches, highlighted challenges in existing research, and proposed avenues for future opportunities.
Learning to Quantize Vulnerability Patterns and Match to Locate Statement-Level Vulnerabilities
May 26, 2023



Deep learning (DL) models have become increasingly popular in identifying software vulnerabilities. Prior studies found that vulnerabilities across different vulnerable programs may exhibit similar vulnerable scopes, implicitly forming discernible vulnerability patterns that can be learned by DL models through supervised training. However, vulnerable scopes still manifest in various spatial locations and formats within a program, posing challenges for models to accurately identify vulnerable statements. Despite this challenge, state-of-the-art vulnerability detection approaches fail to exploit the vulnerability patterns that arise in vulnerable programs. To take full advantage of vulnerability patterns and unleash the ability of DL models, we propose a novel vulnerability-matching approach in this paper, drawing inspiration from program analysis tools that locate vulnerabilities based on pre-defined patterns. Specifically, a vulnerability codebook is learned, which consists of quantized vectors representing various vulnerability patterns. During inference, the codebook is iterated to match all learned patterns and predict the presence of potential vulnerabilities within a given program. Our approach was extensively evaluated on a real-world dataset comprising more than 188,000 C/C++ functions. The evaluation results show that our approach achieves an F1-score of 94% (6% higher than the previous best) and 82% (19% higher than the previous best) for function and statement-level vulnerability identification, respectively. These substantial enhancements highlight the effectiveness of our approach to identifying vulnerabilities. The training code and pre-trained models are available at https://github.com/optimatch/optimatch.
FeatherNets: Convolutional Neural Networks as Light as Feather for Face Anti-spoofing
Apr 22, 2019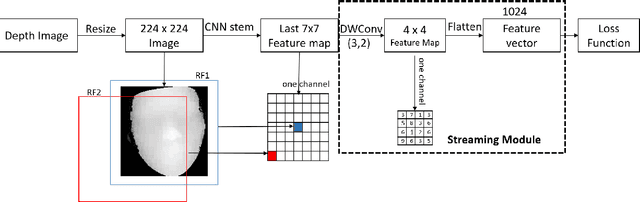
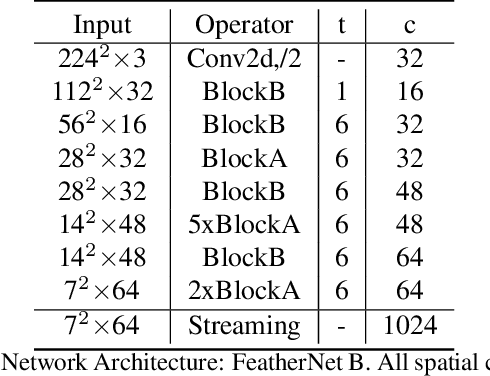
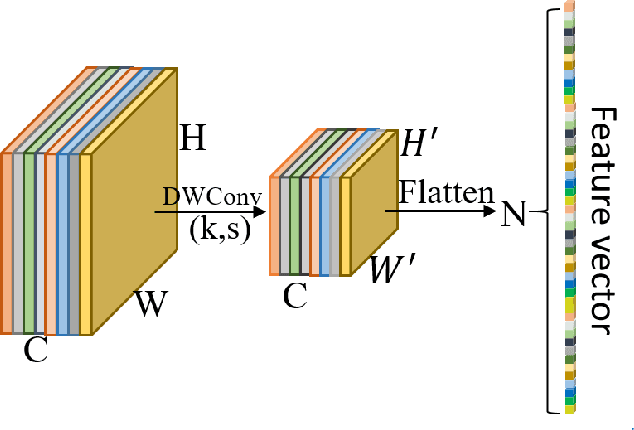

Face Anti-spoofing gains increased attentions recently in both academic and industrial fields. With the emergence of various CNN based solutions, the multi-modal(RGB, depth and IR) methods based CNN showed better performance than single modal classifiers. However, there is a need for improving the performance and reducing the complexity. Therefore, an extreme light network architecture(FeatherNet A/B) is proposed with a streaming module which fixes the weakness of Global Average Pooling and uses less parameters. Our single FeatherNet trained by depth image only, provides a higher baseline with 0.00168 ACER, 0.35M parameters and 83M FLOPS. Furthermore, a novel fusion procedure with ``ensemble + cascade'' structure is presented to satisfy the performance preferred use cases. Meanwhile, the MMFD dataset is collected to provide more attacks and diversity to gain better generalization. We use the fusion method in the Face Anti-spoofing Attack Detection Challenge@CVPR2019 and got the result of 0.0013(ACER), 0.999(TPR@FPR=10e-2), 0.998(TPR@FPR=10e-3) and 0.9814(TPR@FPR=10e-4).
Risk-Sensitive Reinforcement Learning: A Constrained Optimization Viewpoint
Oct 22, 2018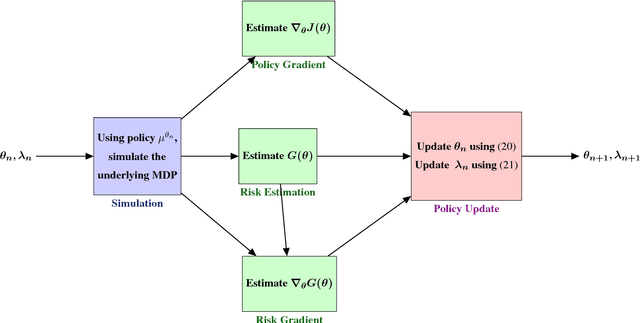
The classic objective in a reinforcement learning (RL) problem is to find a policy that minimizes, in expectation, a long-run objective such as the infinite-horizon discounted or long-run average cost. In many practical applications, optimizing the expected value alone is not sufficient, and it may be necessary to include a risk measure in the optimization process, either as the objective or as a constraint. Various risk measures have been proposed in the literature, e.g., mean-variance tradeoff, exponential utility, the percentile performance, value at risk, conditional value at risk, prospect theory and its later enhancement, cumulative prospect theory. In this article, we focus on the combination of risk criteria and reinforcement learning in a constrained optimization framework, i.e., a setting where the goal to find a policy that optimizes the usual objective of infinite-horizon discounted/average cost, while ensuring that an explicit risk constraint is satisfied. We introduce the risk-constrained RL framework, cover popular risk measures based on variance, conditional value-at-risk and cumulative prospect theory, and present a template for a risk-sensitive RL algorithm. We survey some of our recent work on this topic, covering problems encompassing discounted cost, average cost, and stochastic shortest path settings, together with the aforementioned risk measures in a constrained framework. This non-exhaustive survey is aimed at giving a flavor of the challenges involved in solving a risk-sensitive RL problem, and outlining some potential future research directions.
Random directions stochastic approximation with deterministic perturbations
Aug 08, 2018



We introduce deterministic perturbation schemes for the recently proposed random directions stochastic approximation (RDSA) [17], and propose new first-order and second-order algorithms. In the latter case, these are the first second-order algorithms to incorporate deterministic perturbations. We show that the gradient and/or Hessian estimates in the resulting algorithms with deterministic perturbations are asymptotically unbiased, so that the algorithms are provably convergent. Furthermore, we derive convergence rates to establish the superiority of the first-order and second-order algorithms, for the special case of a convex and quadratic optimization problem, respectively. Numerical experiments are used to validate the theoretical results.
Weighted bandits or: How bandits learn distorted values that are not expected
Nov 30, 2016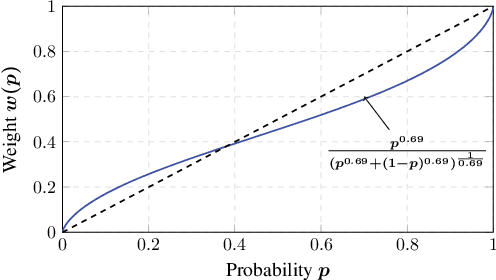
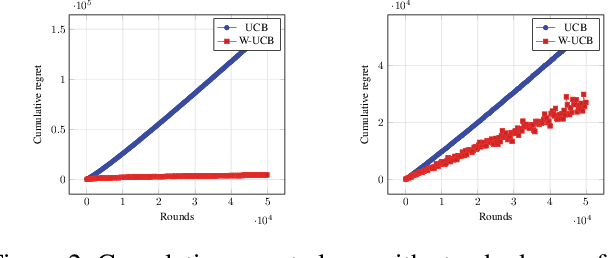

Motivated by models of human decision making proposed to explain commonly observed deviations from conventional expected value preferences, we formulate two stochastic multi-armed bandit problems with distorted probabilities on the cost distributions: the classic $K$-armed bandit and the linearly parameterized bandit. In both settings, we propose algorithms that are inspired by Upper Confidence Bound (UCB), incorporate cost distortions, and exhibit sublinear regret assuming \holder continuous weight distortion functions. For the $K$-armed setting, we show that the algorithm, called W-UCB, achieves problem-dependent regret $O(L^2 M^2 \log n/ \Delta^{\frac{2}{\alpha}-1})$, where $n$ is the number of plays, $\Delta$ is the gap in distorted expected value between the best and next best arm, $L$ and $\alpha$ are the H\"{o}lder constants for the distortion function, and $M$ is an upper bound on costs, and a problem-independent regret bound of $O((KL^2M^2)^{\alpha/2}n^{(2-\alpha)/2})$. We also present a matching lower bound on the regret, showing that the regret of W-UCB is essentially unimprovable over the class of H\"{o}lder-continuous weight distortions. For the linearly parameterized setting, we develop a new algorithm, a variant of the Optimism in the Face of Uncertainty Linear bandit (OFUL) algorithm called WOFUL (Weight-distorted OFUL), and show that it has regret $O(d\sqrt{n} \; \mbox{polylog}(n))$ with high probability, for sub-Gaussian cost distributions. Finally, numerical examples demonstrate the advantages resulting from using distortion-aware learning algorithms.
Cumulative Prospect Theory Meets Reinforcement Learning: Prediction and Control
Feb 26, 2016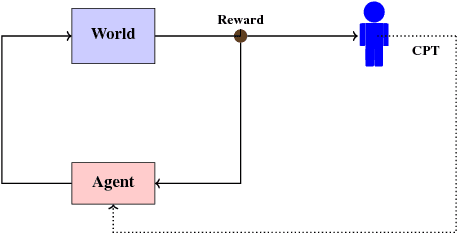
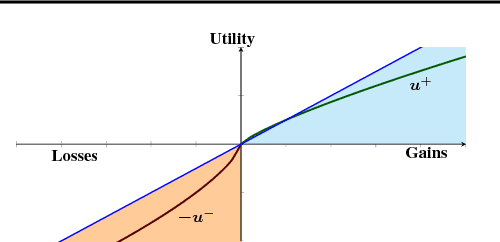
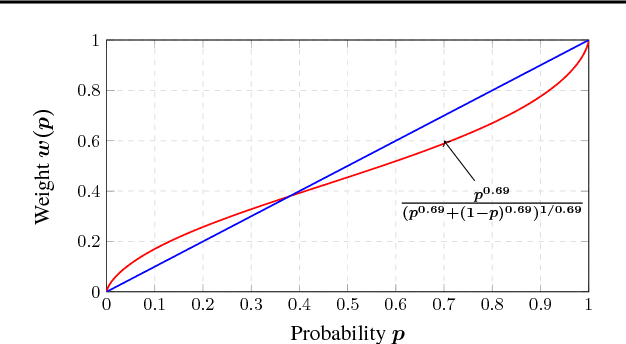
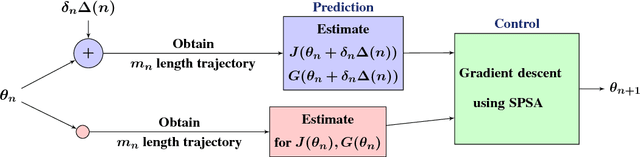
Cumulative prospect theory (CPT) is known to model human decisions well, with substantial empirical evidence supporting this claim. CPT works by distorting probabilities and is more general than the classic expected utility and coherent risk measures. We bring this idea to a risk-sensitive reinforcement learning (RL) setting and design algorithms for both estimation and control. The RL setting presents two particular challenges when CPT is applied: estimating the CPT objective requires estimations of the entire distribution of the value function and finding a randomized optimal policy. The estimation scheme that we propose uses the empirical distribution to estimate the CPT-value of a random variable. We then use this scheme in the inner loop of a CPT-value optimization procedure that is based on the well-known simulation optimization idea of simultaneous perturbation stochastic approximation (SPSA). We provide theoretical convergence guarantees for all the proposed algorithms and also illustrate the usefulness of CPT-based criteria in a traffic signal control application.
Adaptive system optimization using random directions stochastic approximation
Aug 08, 2015
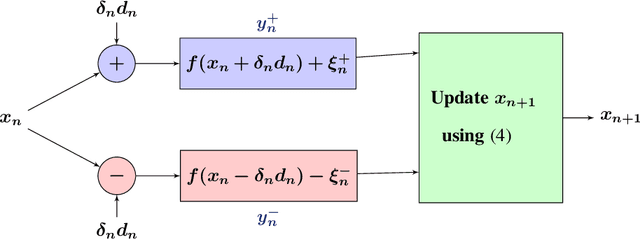
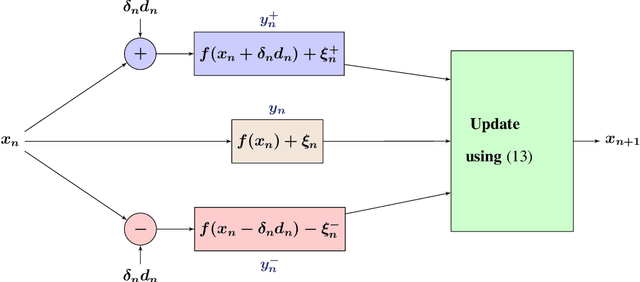

We present novel algorithms for simulation optimization using random directions stochastic approximation (RDSA). These include first-order (gradient) as well as second-order (Newton) schemes. We incorporate both continuous-valued as well as discrete-valued perturbations into both our algorithms. The former are chosen to be independent and identically distributed (i.i.d.) symmetric, uniformly distributed random variables (r.v.), while the latter are i.i.d., asymmetric, Bernoulli r.v.s. Our Newton algorithm, with a novel Hessian estimation scheme, requires N-dimensional perturbations and three loss measurements per iteration, whereas the simultaneous perturbation Newton search algorithm of [1] requires 2N-dimensional perturbations and four loss measurements per iteration. We prove the unbiasedness of both gradient and Hessian estimates and asymptotic (strong) convergence for both first-order and second-order schemes. We also provide asymptotic normality results, which in particular establish that the asymmetric Bernoulli variant of Newton RDSA method is better than 2SPSA of [1]. Numerical experiments are used to validate the theoretical results.