 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted bandits or: How bandits learn distorted values that are not expected
Paper and Code
Nov 30, 2016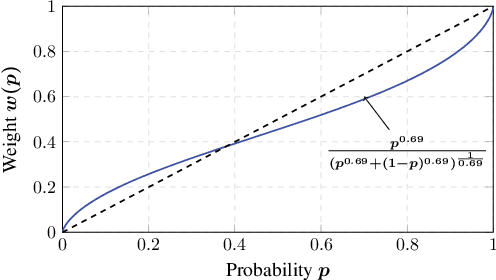
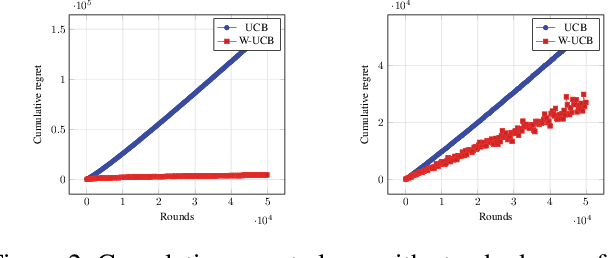

Motivated by models of human decision making proposed to explain commonly observed deviations from conventional expected value preferences, we formulate two stochastic multi-armed bandit problems with distorted probabilities on the cost distributions: the classic $K$-armed bandit and the linearly parameterized bandit. In both settings, we propose algorithms that are inspired by Upper Confidence Bound (UCB), incorporate cost distortions, and exhibit sublinear regret assuming \holder continuous weight distortion functions. For the $K$-armed setting, we show that the algorithm, called W-UCB, achieves problem-dependent regret $O(L^2 M^2 \log n/ \Delta^{\frac{2}{\alpha}-1})$, where $n$ is the number of plays, $\Delta$ is the gap in distorted expected value between the best and next best arm, $L$ and $\alpha$ are the H\"{o}lder constants for the distortion function, and $M$ is an upper bound on costs, and a problem-independent regret bound of $O((KL^2M^2)^{\alpha/2}n^{(2-\alpha)/2})$. We also present a matching lower bound on the regret, showing that the regret of W-UCB is essentially unimprovable over the class of H\"{o}lder-continuous weight distortions. For the linearly parameterized setting, we develop a new algorithm, a variant of the Optimism in the Face of Uncertainty Linear bandit (OFUL) algorithm called WOFUL (Weight-distorted OFUL), and show that it has regret $O(d\sqrt{n} \; \mbox{polylog}(n))$ with high probability, for sub-Gaussian cost distributions. Finally, numerical examples demonstrate the advantages resulting from using distortion-aware learning algorithms.