 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVGS: Single-View to 3D Object Editing via Gaussian Splatting
Mar 30, 2026Text-driven 3D scene editing has attracted considerable interest due to its convenience and user-friendliness. However, methods that rely on implicit 3D representations, such as Neural Radiance Fields (NeRF), while effective in rendering complex scenes, are hindered by slow processing speeds and limited control over specific regions of the scene. Moreover, existing approaches, including Instruct-NeRF2NeRF and GaussianEditor, which utilize multi-view editing strategies, frequently produce inconsistent results across different views when executing text instructions. This inconsistency can adversely affect the overall performance of the model, complicating the task of balancing the consistency of editing results with editing efficiency. To address these challenges, we propose a novel method termed Single-View to 3D Object Editing via Gaussian Splatting (SVGS), which is a single-view text-driven editing technique based on 3D Gaussian Splatting (3DGS). Specifically, in response to text instructions, we introduce a single-view editing strategy grounded in multi-view diffusion models, which reconstructs 3D scenes by leveraging only those views that yield consistent editing results. Additionally, we employ sparse 3D Gaussian Splatting as the 3D representation, which significantly enhances editing efficiency. We conducted a comparative analysis of SVGS against existing baseline methods across various scene settings, and the results indicate that SVGS outperforms its counterparts in both editing capability and processing speed, representing a significant advancement in 3D editing technology. For further details, please visit our project page at: https://amateurc.github.io/svgs.github.io.
DM-CFO: A Diffusion Model for Compositional 3D Tooth Generation with Collision-Free Optimization
Mar 04, 2026The automatic design of a 3D tooth model plays a crucial role in dental digitization. However, current approaches face challenges in compositional 3D tooth generation because both the layouts and shapes of missing teeth need to be optimized.In addition, collision conflicts are often omitted in 3D Gaussian-based compositional 3D generation, where objects may intersect with each other due to the absence of explicit geometric information on the object surfaces. Motivated by graph generation through diffusion models and collision detection using 3D Gaussians, we propose an approach named DM-CFO for compositional tooth generation, where the layout of missing teeth is progressively restored during the denoising phase under both text and graph constraints. Then, the Gaussian parameters of each layout-guided tooth and the entire jaw are alternately updated using score distillation sampling (SDS). Furthermore, a regularization term based on the distances between the 3D Gaussians of neighboring teeth and the anchor tooth is introduced to penalize tooth intersections. Experimental results on three tooth-design datasets demonstrate that our approach significantly improves the multiview consistency and realism of the generated teeth compared with existing methods. Project page: https://amateurc.github.io/CF-3DTeeth/.
RGB-Event HyperGraph Prompt for Kilometer Marker Recognition based on Pre-trained Foundation Models
Feb 25, 2026Metro trains often operate in highly complex environments, characterized by illumination variations, high-speed motion, and adverse weather conditions. These factors pose significant challenges for visual perception systems, especially those relying solely on conventional RGB cameras. To tackle these difficulties, we explore the integration of event cameras into the perception system, leveraging their advantages in low-light conditions, high-speed scenarios, and low power consumption. Specifically, we focus on Kilometer Marker Recognition (KMR), a critical task for autonomous metro localization under GNSS-denied conditions. In this context, we propose a robust baseline method based on a pre-trained RGB OCR foundation model, enhanced through multi-modal adaptation. Furthermore, we construct the first large-scale RGB-Event dataset, EvMetro5K, containing 5,599 pairs of synchronized RGB-Event samples, split into 4,479 training and 1,120 testing samples. Extensive experiments on EvMetro5K and other widely used benchmarks demonstrate the effectiveness of our approach for KMR. Both the dataset and source code will be released on https://github.com/Event-AHU/EvMetro5K_benchmark
Innovative Tooth Segmentation Using Hierarchical Features and Bidirectional Sequence Modeling
Feb 25, 2026Tooth image segmentation is a cornerstone of dental digitization. However, traditional image encoders relying on fixed-resolution feature maps often lead to discontinuous segmentation and poor discrimination between target regions and background, due to insufficient modeling of environmental and global context. Moreover, transformer-based self-attention introduces substantial computational overhead because of its quadratic complexity (O(n^2)), making it inefficient for high-resolution dental images. To address these challenges, we introduce a three-stage encoder with hierarchical feature representation to capture scale-adaptive information in dental images. By jointly leveraging low-level details and high-level semantics through cross-scale feature fusion, the model effectively preserves fine structural information while maintaining strong contextual awareness. Furthermore, a bidirectional sequence modeling strategy is incorporated to enhance global spatial context understanding without incurring high computational cost. We validate our method on two dental datasets, with experimental results demonstrating its superiority over existing approaches. On the OralVision dataset, our model achieves a 1.1% improvement in mean intersection over union (mIoU).
* Accepted by Pattern Recognition
IA-MVS: Instance-Focused Adaptive Depth Sampling for Multi-View Stereo
May 19, 2025Multi-view stereo (MVS) models based on progressive depth hypothesis narrowing have made remarkable advancements. However, existing methods haven't fully utilized the potential that the depth coverage of individual instances is smaller than that of the entire scene, which restricts further improvements in depth estimation precision. Moreover, inevitable deviations in the initial stage accumulate as the process advances. In this paper, we propose Instance-Adaptive MVS (IA-MVS). It enhances the precision of depth estimation by narrowing the depth hypothesis range and conducting refinement on each instance. Additionally, a filtering mechanism based on intra-instance depth continuity priors is incorporated to boost robustness. Furthermore, recognizing that existing confidence estimation can degrade IA-MVS performance on point clouds. We have developed a detailed mathematical model for confidence estimation based on conditional probability. The proposed method can be widely applied in models based on MVSNet without imposing extra training burdens. Our method achieves state-of-the-art performance on the DTU benchmark. The source code is available at https://github.com/KevinWang73106/IA-MVS.
Survey on deep learning in multimodal medical imaging for cancer detection
Dec 04, 2023The task of multimodal cancer detection is to determine the locations and categories of lesions by using different imaging techniques, which is one of the key research methods for cancer diagnosis. Recently, deep learning-based object detection has made significant developments due to its strength in semantic feature extraction and nonlinear function fitting. However, multimodal cancer detection remains challenging due to morphological differences in lesions, interpatient variability, difficulty in annotation, and imaging artifacts. In this survey, we mainly investigate over 150 papers in recent years with respect to multimodal cancer detection using deep learning, with a focus on datasets and solutions to various challenges such as data annotation, variance between classes, small-scale lesions, and occlusion. We also provide an overview of the advantages and drawbacks of each approach. Finally, we discuss the current scope of work and provide directions for the future development of multimodal cancer detection.
Limited Gradient Descent: Learning With Noisy Labels
Dec 06, 2018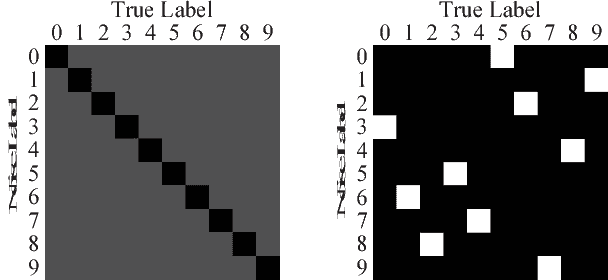

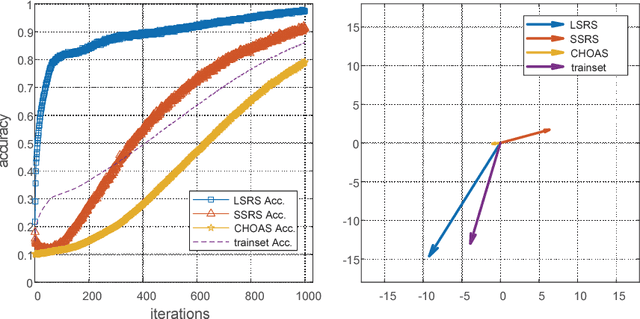
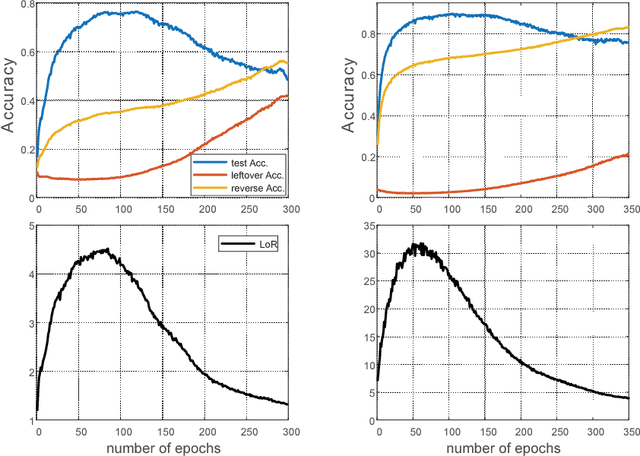
Label noise may handicap the generalization of classifiers, and the effective learning of the main pattern from samples with noisy labels is an important issue. Recent studies have shown that deep neural networks tend to prioritize the learning of simple patterns over the memorization of noise patterns. This suggests the need for a method to search for the best generalization that learns the main pattern until noise begins to be memorized. An intuitive idea is to use a supervised approach to find the stop timing of learning by, for example, employing a clean verification set. In practice, however, a clean verification set is sometimes difficult to obtain. To solve this problem, we propose an unsupervised method called limited gradient descent to estimate the best stop timing. We modified the labels of a few samples in a noisy dataset to be almost false labels, creating a reverse pattern. By monitoring the learning progresses of the noisy samples and the reverse samples, we could determine the stop timing of learning. In this paper, we also provide some sufficient conditions on learning with noisy labels. Experimental results on CIFAR-10 demonstrate that our approach has a similar generalization performance to supervised methods. For uncomplicated datasets, such as MNIST, we add a relabeling strategy to further improve generalization and achieve state-of-the-art performance.