 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMO-CTranS: A unified multi-organ segmentation model learning from multiple heterogeneously labelled datasets
Mar 28, 2025


Multi-organ segmentation holds paramount significance in many clinical tasks. In practice, compared to large fully annotated datasets, multiple small datasets are often more accessible and organs are not labelled consistently. Normally, an individual model is trained for each of these datasets, which is not an effective way of using data for model learning. It remains challenging to train a single model that can robustly learn from several partially labelled datasets due to label conflict and data imbalance problems. We propose MO-CTranS: a single model that can overcome such problems. MO-CTranS contains a CNN-based encoder and a Transformer-based decoder, which are connected in a multi-resolution manner. Task-specific tokens are introduced in the decoder to help differentiate label discrepancies. Our method was evaluated and compared to several baseline models and state-of-the-art (SOTA) solutions on abdominal MRI datasets that were acquired in different views (i.e. axial and coronal) and annotated for different organs (i.e. liver, kidney, spleen). Our method achieved better performance (most were statistically significant) than the compared methods. Github link: https://github.com/naisops/MO-CTranS.
FU-net: Multi-class Image Segmentation Using Feedback Weighted U-net
Apr 28, 2020
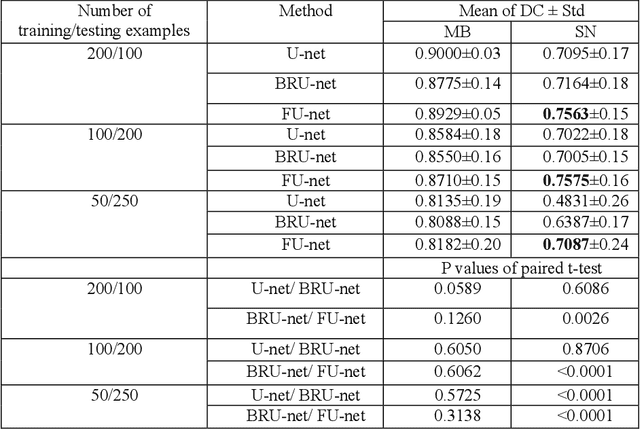

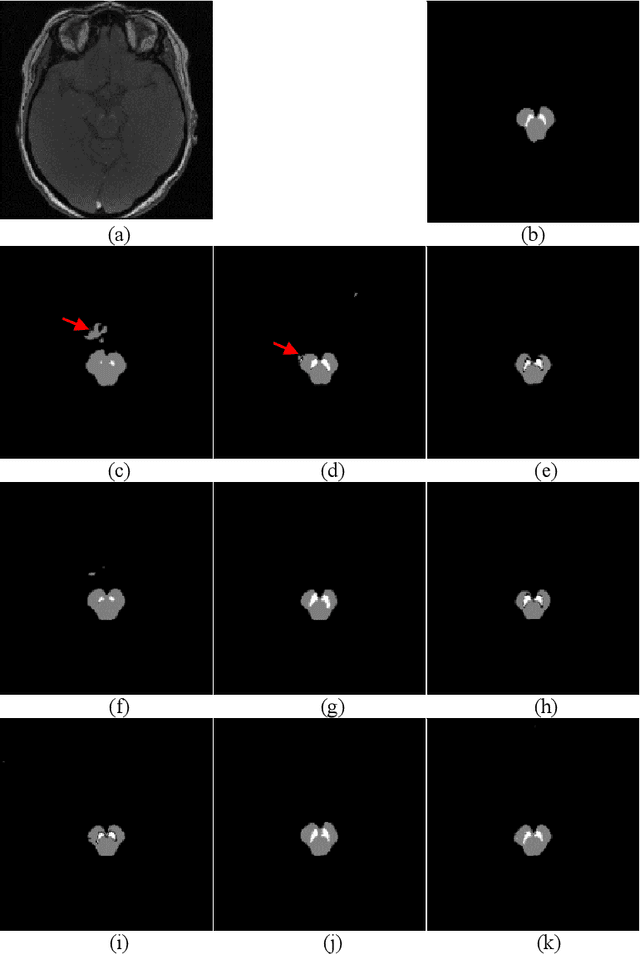
In this paper, we present a generic deep convolutional neural network (DCNN) for multi-class image segmentation. It is based on a well-established supervised end-to-end DCNN model, known as U-net. U-net is firstly modified by adding widely used batch normalization and residual block (named as BRU-net) to improve the efficiency of model training. Based on BRU-net, we further introduce a dynamically weighted cross-entropy loss function. The weighting scheme is calculated based on the pixel-wise prediction accuracy during the training process. Assigning higher weights to pixels with lower segmentation accuracies enables the network to learn more from poorly predicted image regions. Our method is named as feedback weighted U-net (FU-net). We have evaluated our method based on T1- weighted brain MRI for the segmentation of midbrain and substantia nigra, where the number of pixels in each class is extremely unbalanced to each other. Based on the dice coefficient measurement, our proposed FU-net has outperformed BRU-net and U-net with statistical significance, especially when only a small number of training examples are available. The code is publicly available in GitHub (GitHub link: https://github.com/MinaJf/FU-net).
* Accepted for publication at International Conference on Image and Graphics (ICIG 2019)
DRU-net: An Efficient Deep Convolutional Neural Network for Medical Image Segmentation
Apr 28, 2020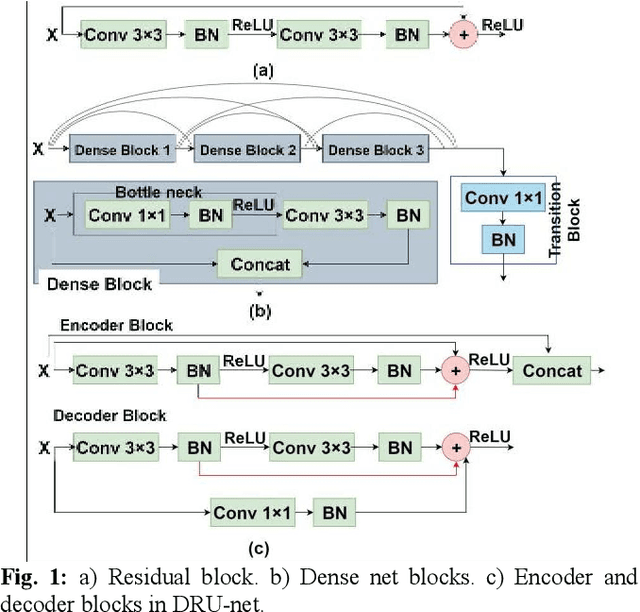
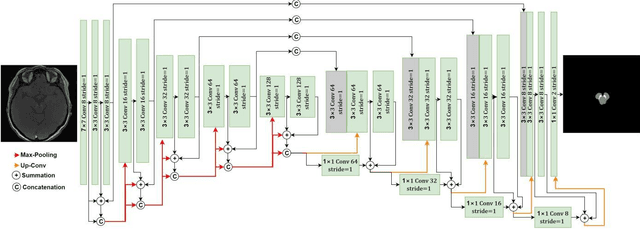
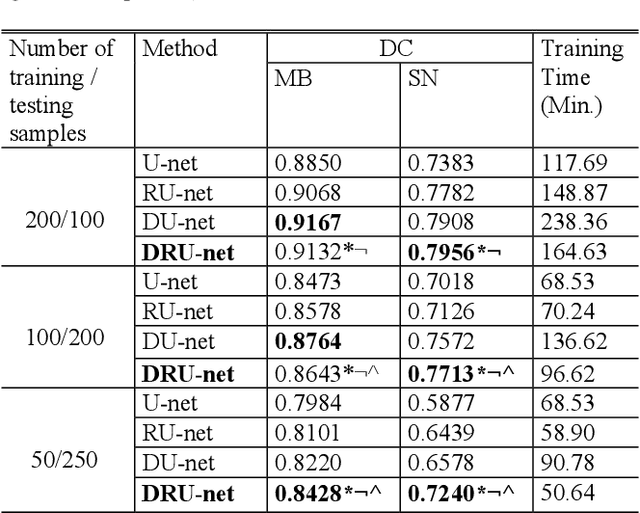

Residual network (ResNet) and densely connected network (DenseNet) have significantly improved the training efficiency and performance of deep convolutional neural networks (DCNNs) mainly for object classification tasks. In this paper, we propose an efficient network architecture by considering advantages of both networks. The proposed method is integrated into an encoder-decoder DCNN model for medical image segmentation. Our method adds additional skip connections compared to ResNet but uses significantly fewer model parameters than DenseNet. We evaluate the proposed method on a public dataset (ISIC 2018 grand-challenge) for skin lesion segmentation and a local brain MRI dataset. In comparison with ResNet-based, DenseNet-based and attention network (AttnNet) based methods within the same encoder-decoder network structure, our method achieves significantly higher segmentation accuracy with fewer number of model parameters than DenseNet and AttnNet. The code is available on GitHub (GitHub link: https://github.com/MinaJf/DRU-net).
* Accepted for publication at IEEE International Symposium on Biomedical Imaging (ISBI) 2020, 5 pages, 3 figures
A Spatially Constrained Deep Convolutional Neural Network for Nerve Fiber Segmentation in Corneal Confocal Microscopic Images using Inaccurate Annotations
Apr 20, 2020


Semantic image segmentation is one of the most important tasks in medical image analysis. Most state-of-the-art deep learning methods require a large number of accurately annotated examples for model training. However, accurate annotation is difficult to obtain especially in medical applications. In this paper, we propose a spatially constrained deep convolutional neural network (DCNN) to achieve smooth and robust image segmentation using inaccurately annotated labels for training. In our proposed method, image segmentation is formulated as a graph optimization problem that is solved by a DCNN model learning process. The cost function to be optimized consists of a unary term that is calculated by cross entropy measurement and a pairwise term that is based on enforcing a local label consistency. The proposed method has been evaluated based on corneal confocal microscopic (CCM) images for nerve fiber segmentation, where accurate annotations are extremely difficult to be obtained. Based on both the quantitative result of a synthetic dataset and qualitative assessment of a real dataset, the proposed method has achieved superior performance in producing high quality segmentation results even with inaccurate labels for training.
* 4 pages, accepted for publication at IEEE International Symposium on Biomedical Imaging (ISBI) 2020