 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Multimodal MRI-Based Foundation Model for Multi-Level Feature Exploration in Segmentation, Molecular Subtyping, and Grading of Glioma
Mar 10, 2025Accurate, noninvasive glioma characterization is crucial for effective clinical management. Traditional methods, dependent on invasive tissue sampling, often fail to capture the spatial heterogeneity of the tumor. While deep learning has improved segmentation and molecular profiling, few approaches simultaneously integrate tumor morphology and molecular features. Foundation deep learning models, which learn robust, task-agnostic representations from large-scale datasets, hold great promise but remain underutilized in glioma imaging biomarkers. We propose the Multi-Task SWIN-UNETR (MTS-UNET) model, a novel foundation-based framework built on the BrainSegFounder model, pretrained on large-scale neuroimaging data. MTS-UNET simultaneously performs glioma segmentation, histological grading, and molecular subtyping (IDH mutation and 1p/19q co-deletion). It incorporates two key modules: Tumor-Aware Feature Encoding (TAFE) for multi-scale, tumor-focused feature extraction and Cross-Modality Differential (CMD) for highlighting subtle T2-FLAIR mismatch signals associated with IDH mutation. The model was trained and validated on a diverse, multi-center cohort of 2,249 glioma patients from seven public datasets. MTS-UNET achieved a mean Dice score of 84% for segmentation, along with AUCs of 90.58% for IDH mutation, 69.22% for 1p/19q co-deletion prediction, and 87.54% for grading, significantly outperforming baseline models (p<=0.05). Ablation studies validated the essential contributions of the TAFE and CMD modules and demonstrated the robustness of the framework. The foundation-based MTS-UNET model effectively integrates tumor segmentation with multi-level classification, exhibiting strong generalizability across diverse MRI datasets. This framework shows significant potential for advancing noninvasive, personalized glioma management by improving predictive accuracy and interpretability.
Comparative Analysis of nnUNet and MedNeXt for Head and Neck Tumor Segmentation in MRI-guided Radiotherapy
Nov 22, 2024Radiation therapy (RT) is essential in treating head and neck cancer (HNC), with magnetic resonance imaging(MRI)-guided RT offering superior soft tissue contrast and functional imaging. However, manual tumor segmentation is time-consuming and complex, and therfore remains a challenge. In this study, we present our solution as team TUMOR to the HNTS-MRG24 MICCAI Challenge which is focused on automated segmentation of primary gross tumor volumes (GTVp) and metastatic lymph node gross tumor volume (GTVn) in pre-RT and mid-RT MRI images. We utilized the HNTS-MRG2024 dataset, which consists of 150 MRI scans from patients diagnosed with HNC, including original and registered pre-RT and mid-RT T2-weighted images with corresponding segmentation masks for GTVp and GTVn. We employed two state-of-the-art models in deep learning, nnUNet and MedNeXt. For Task 1, we pretrained models on pre-RT registered and mid-RT images, followed by fine-tuning on original pre-RT images. For Task 2, we combined registered pre-RT images, registered pre-RT segmentation masks, and mid-RT data as a multi-channel input for training. Our solution for Task 1 achieved 1st place in the final test phase with an aggregated Dice Similarity Coefficient of 0.8254, and our solution for Task 2 ranked 8th with a score of 0.7005. The proposed solution is publicly available at Github Repository.
ExIQA: Explainable Image Quality Assessment Using Distortion Attributes
Sep 10, 2024



Blind Image Quality Assessment (BIQA) aims to develop methods that estimate the quality scores of images in the absence of a reference image. In this paper, we approach BIQA from a distortion identification perspective, where our primary goal is to predict distortion types and strengths using Vision-Language Models (VLMs), such as CLIP, due to their extensive knowledge and generalizability. Based on these predicted distortions, we then estimate the quality score of the image. To achieve this, we propose an explainable approach for distortion identification based on attribute learning. Instead of prompting VLMs with the names of distortions, we prompt them with the attributes or effects of distortions and aggregate this information to infer the distortion strength. Additionally, we consider multiple distortions per image, making our method more scalable. To support this, we generate a dataset consisting of 100,000 images for efficient training. Finally, attribute probabilities are retrieved and fed into a regressor to predict the image quality score. The results show that our approach, besides its explainability and transparency, achieves state-of-the-art (SOTA) performance across multiple datasets in both PLCC and SRCC metrics. Moreover, the zero-shot results demonstrate the generalizability of the proposed approach.
IBO: Inpainting-Based Occlusion to Enhance Explainable Artificial Intelligence Evaluation in Histopathology
Sep 03, 2024Histopathological image analysis is crucial for accurate cancer diagnosis and treatment planning. While deep learning models, especially convolutional neural networks, have advanced this field, their "black-box" nature raises concerns about interpretability and trustworthiness. Explainable Artificial Intelligence (XAI) techniques aim to address these concerns, but evaluating their effectiveness remains challenging. A significant issue with current occlusion-based XAI methods is that they often generate Out-of-Distribution (OoD) samples, leading to inaccurate evaluations. In this paper, we introduce Inpainting-Based Occlusion (IBO), a novel occlusion strategy that utilizes a Denoising Diffusion Probabilistic Model to inpaint occluded regions in histopathological images. By replacing cancerous areas with realistic, non-cancerous tissue, IBO minimizes OoD artifacts and preserves data integrity. We evaluate our method on the CAMELYON16 dataset through two phases: first, by assessing perceptual similarity using the Learned Perceptual Image Patch Similarity (LPIPS) metric, and second, by quantifying the impact on model predictions through Area Under the Curve (AUC) analysis. Our results demonstrate that IBO significantly improves perceptual fidelity, achieving nearly twice the improvement in LPIPS scores compared to the best existing occlusion strategy. Additionally, IBO increased the precision of XAI performance prediction from 42% to 71% compared to traditional methods. These results demonstrate IBO's potential to provide more reliable evaluations of XAI techniques, benefiting histopathology and other applications. The source code for this study is available at https://github.com/a-fsh-r/IBO.
TACNET: Temporal Audio Source Counting Network
Nov 04, 2023In this paper, we introduce the Temporal Audio Source Counting Network (TaCNet), an innovative architecture that addresses limitations in audio source counting tasks. TaCNet operates directly on raw audio inputs, eliminating complex preprocessing steps and simplifying the workflow. Notably, it excels in real-time speaker counting, even with truncated input windows. Our extensive evaluation, conducted using the LibriCount dataset, underscores TaCNet's exceptional performance, positioning it as a state-of-the-art solution for audio source counting tasks. With an average accuracy of 74.18 percentage over 11 classes, TaCNet demonstrates its effectiveness across diverse scenarios, including applications involving Chinese and Persian languages. This cross-lingual adaptability highlights its versatility and potential impact.
A novel shape-based loss function for machine learning-based seminal organ segmentation in medical imaging
Mar 07, 2022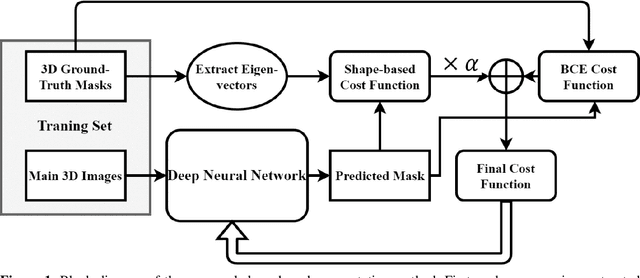

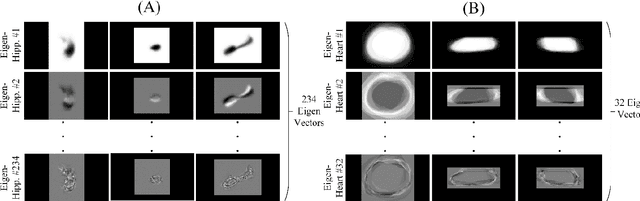
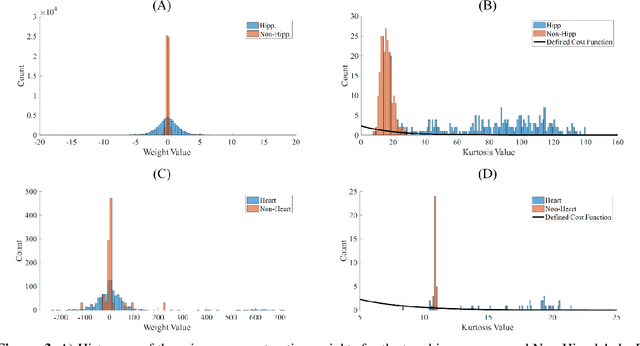
Automated medical image segmentation is an essential task to aid/speed up diagnosis and treatment procedures in clinical practices. Deep convolutional neural networks have exhibited promising performance in accurate and automatic seminal segmentation. For segmentation tasks, these methods normally rely on minimizing a cost/loss function that is designed to maximize the overlap between the estimated target and the ground-truth mask delineated by the experts. A simple loss function based on the degrees of overlap (i.e., Dice metric) would not take into account the underlying shape and morphology of the target subject, as well as its realistic/natural variations; therefore, suboptimal segmentation results would be observed in the form of islands of voxels, holes, and unrealistic shapes or deformations. In this light, many studies have been conducted to refine/post-process the segmentation outcome and consider an initial guess as prior knowledge to avoid outliers and/or unrealistic estimations. In this study, a novel shape-based cost function is proposed which encourages/constrains the network to learn/capture the underlying shape features in order to generate a valid/realistic estimation of the target structure. To this end, the Principal Component Analysis (PCA) was performed on a vectorized training dataset to extract eigenvalues and eigenvectors of the target subjects. The key idea was to use the reconstruction weights to discriminate valid outcomes from outliers/erroneous estimations.
Laplacian Mixture Model Point Based Registration
Jun 22, 2020


Point base registration is an important part in many machine VISIOn applications, medical diagnostics, agricultural studies etc. The goal of point set registration is to find correspondences between different data sets and estimate the appropriate transformation that can map one set to another. Here we introduce a novel method for matching of different data sets based on Laplacian distribution. We consider the alignment of two point sets as probability density estimation problem. By using maximum likelihood methods we try to fit the Laplacian mixture model (LMM) centroids (source point set) to the data point set.
Ultrasound-Guided Robotic Navigation with Deep Reinforcement Learning
Apr 07, 2020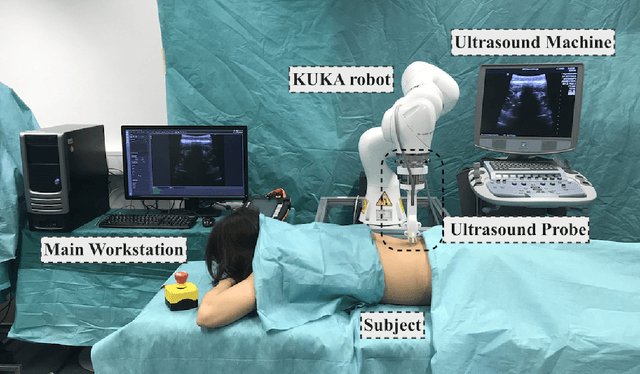
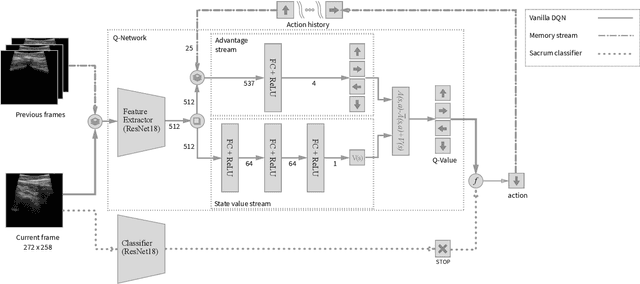
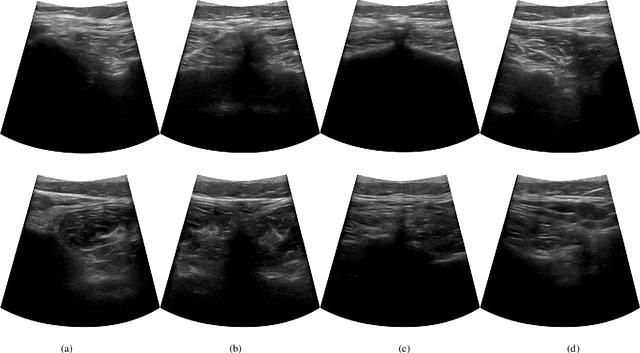
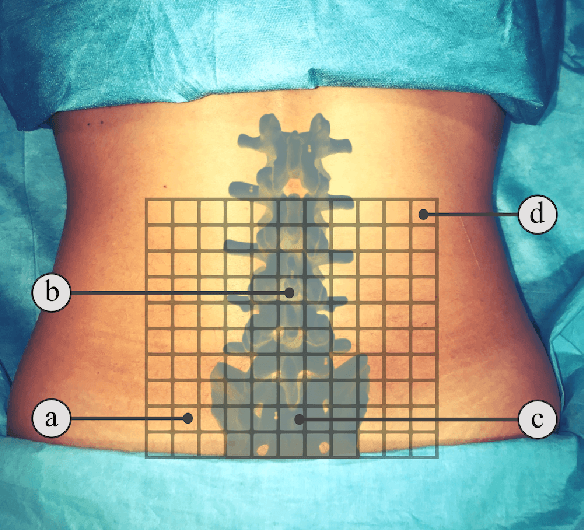
In this paper we introduce the first reinforcement learning (RL) based robotic navigation method which utilizes ultrasound (US) images as an input. Our approach combines state-of-the-art RL techniques, specifically deep Q-networks (DQN) with memory buffers and a binary classifier for deciding when to terminate the task. Our method is trained and evaluated on an in-house collected data-set of 34 volunteers and when compared to pure RL and supervised learning (SL) techniques, it performs substantially better, which highlights the suitability of RL navigation for US-guided procedures. When testing our proposed model, we obtained a 82.91% chance of navigating correctly to the sacrum from 165 different starting positions on 5 different unseen simulated environments.
Robust Image Registration via Empirical Mode Decomposition
Nov 12, 2017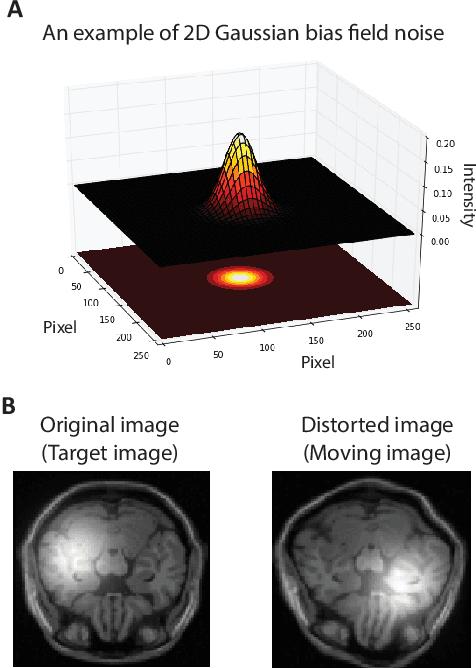
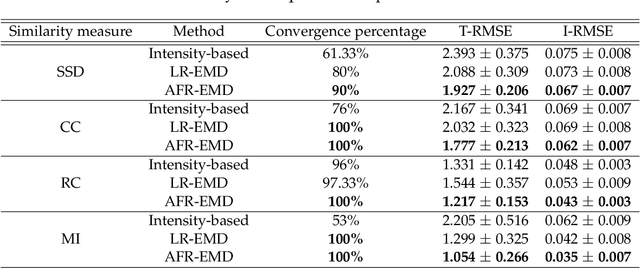
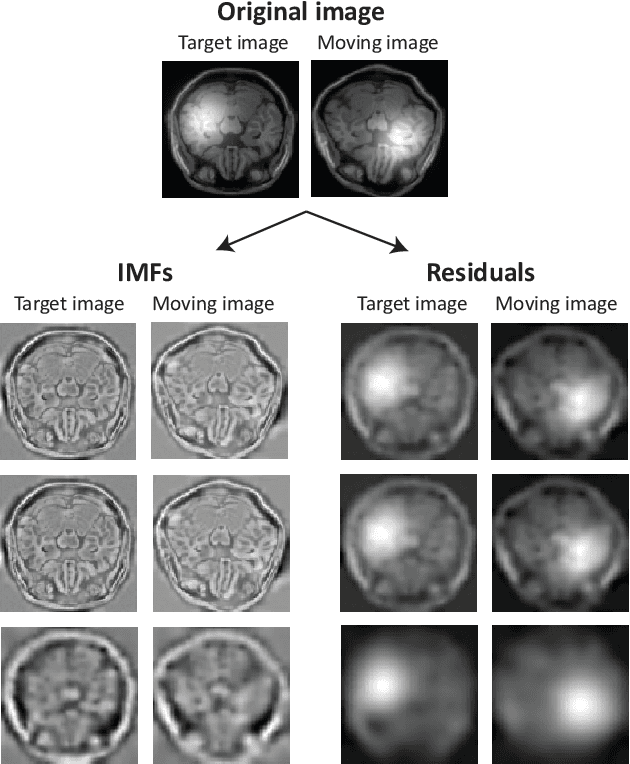
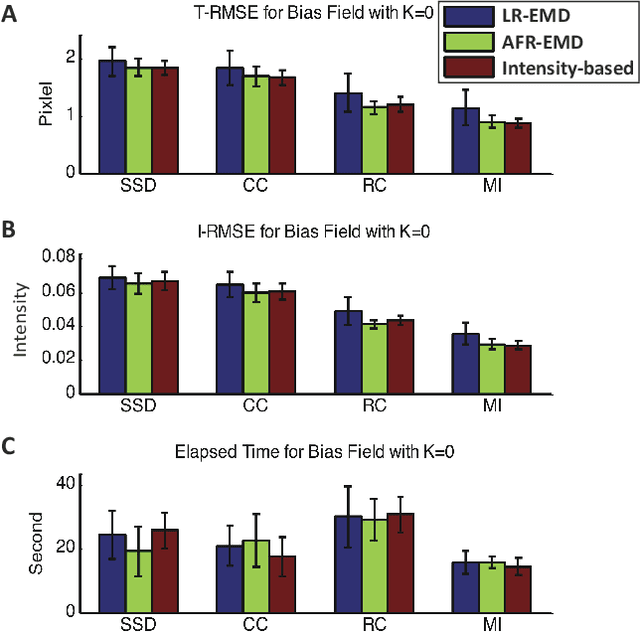
Spatially varying intensity noise is a common source of distortion in images. Bias field noise is one example of such distortion that is often present in the magnetic resonance (MR) images. In this paper, we first show that empirical mode decomposition (EMD) can considerably reduce the bias field noise in the MR images. Then, we propose two hierarchical multi-resolution EMD-based algorithms for robust registration of images in the presence of spatially varying noise. One algorithm (LR-EMD) is based on registering EMD feature-maps of both floating and reference images in various resolution levels. In the second algorithm (AFR-EMD), we first extract an average feature-map based on EMD from both floating and reference images. Then, we use a simple hierarchical multi-resolution algorithm based on downsampling to register the average feature-maps. Both algorithms achieve lower error rate and higher convergence percentage compared to the intensity-based hierarchical registration. Specifically, using mutual information as the similarity measure, AFR-EMD achieves 42% lower error rate in intensity and 52% lower error rate in transformation compared to intensity-based hierarchical registration. For LR-EMD, the error rate is 32% lower for the intensity and 41% lower for the transformation.
Multispectral Palmprint Recognition Using a Hybrid Feature
Dec 11, 2015
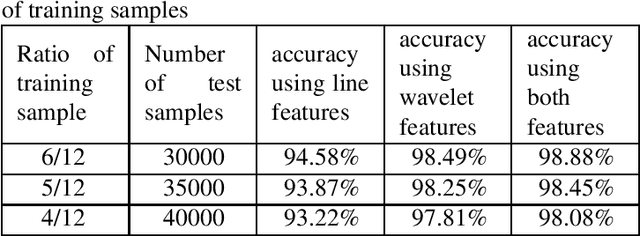


Personal identification problem has been a major field of research in recent years. Biometrics-based technologies that exploit fingerprints, iris, face, voice and palmprints, have been in the center of attention to solve this problem. Palmprints can be used instead of fingerprints that have been of the earliest of these biometrics technologies. A palm is covered with the same skin as the fingertips but has a larger surface, giving us more information than the fingertips. The major features of the palm are palm-lines, including principal lines, wrinkles and ridges. Using these lines is one of the most popular approaches towards solving the palmprint recognition problem. Another robust feature is the wavelet energy of palms. In this paper we used a hybrid feature which combines both of these features. %Moreover, multispectral analysis is applied to improve the performance of the system. At the end, minimum distance classifier is used to match test images with one of the training samples. The proposed algorithm has been tested on a well-known multispectral palmprint dataset and achieved an average accuracy of 98.8\%.