 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpaceVLM: Sub-Space Modeling of Negation in Vision-Language Models
Nov 15, 2025Vision-Language Models (VLMs) struggle with negation. Given a prompt like "retrieve (or generate) a street scene without pedestrians," they often fail to respect the "not." Existing methods address this limitation by fine-tuning on large negation datasets, but such retraining often compromises the model's zero-shot performance on affirmative prompts. We show that the embedding space of VLMs, such as CLIP, can be divided into semantically consistent subspaces. Based on this property, we propose a training-free framework that models negation as a subspace in the joint embedding space rather than a single point (Figure 1). To find the matching image for a caption such as "A but not N," we construct two spherical caps around the embeddings of A and N, and we score images by the central direction of the region that is close to A and far from N. Across retrieval, MCQ, and text-to-image tasks, our method improves negation understanding by about 30% on average over prior methods. It closes the gap between affirmative and negated prompts while preserving the zero-shot performance that fine-tuned models fail to maintain. Code will be released upon publication.
Multi-Rationale Explainable Object Recognition via Contrastive Conditional Inference
Aug 19, 2025Explainable object recognition using vision-language models such as CLIP involves predicting accurate category labels supported by rationales that justify the decision-making process. Existing methods typically rely on prompt-based conditioning, which suffers from limitations in CLIP's text encoder and provides weak conditioning on explanatory structures. Additionally, prior datasets are often restricted to single, and frequently noisy, rationales that fail to capture the full diversity of discriminative image features. In this work, we introduce a multi-rationale explainable object recognition benchmark comprising datasets in which each image is annotated with multiple ground-truth rationales, along with evaluation metrics designed to offer a more comprehensive representation of the task. To overcome the limitations of previous approaches, we propose a contrastive conditional inference (CCI) framework that explicitly models the probabilistic relationships among image embeddings, category labels, and rationales. Without requiring any training, our framework enables more effective conditioning on rationales to predict accurate object categories. Our approach achieves state-of-the-art results on the multi-rationale explainable object recognition benchmark, including strong zero-shot performance, and sets a new standard for both classification accuracy and rationale quality. Together with the benchmark, this work provides a more complete framework for evaluating future models in explainable object recognition. The code will be made available online.
ExIQA: Explainable Image Quality Assessment Using Distortion Attributes
Sep 10, 2024



Blind Image Quality Assessment (BIQA) aims to develop methods that estimate the quality scores of images in the absence of a reference image. In this paper, we approach BIQA from a distortion identification perspective, where our primary goal is to predict distortion types and strengths using Vision-Language Models (VLMs), such as CLIP, due to their extensive knowledge and generalizability. Based on these predicted distortions, we then estimate the quality score of the image. To achieve this, we propose an explainable approach for distortion identification based on attribute learning. Instead of prompting VLMs with the names of distortions, we prompt them with the attributes or effects of distortions and aggregate this information to infer the distortion strength. Additionally, we consider multiple distortions per image, making our method more scalable. To support this, we generate a dataset consisting of 100,000 images for efficient training. Finally, attribute probabilities are retrieved and fed into a regressor to predict the image quality score. The results show that our approach, besides its explainability and transparency, achieves state-of-the-art (SOTA) performance across multiple datasets in both PLCC and SRCC metrics. Moreover, the zero-shot results demonstrate the generalizability of the proposed approach.
ECOR: Explainable CLIP for Object Recognition
Apr 19, 2024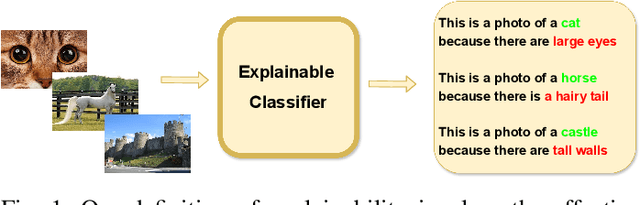
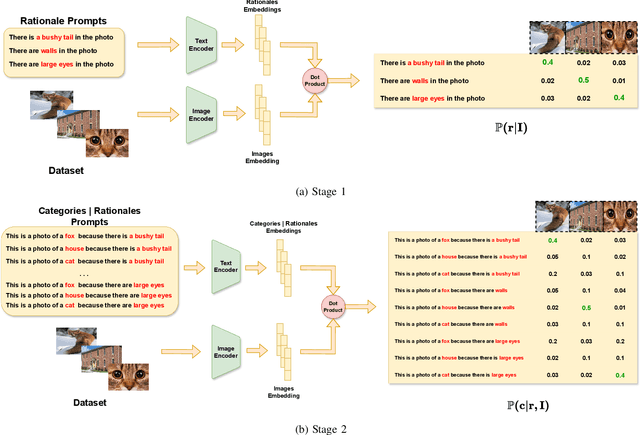
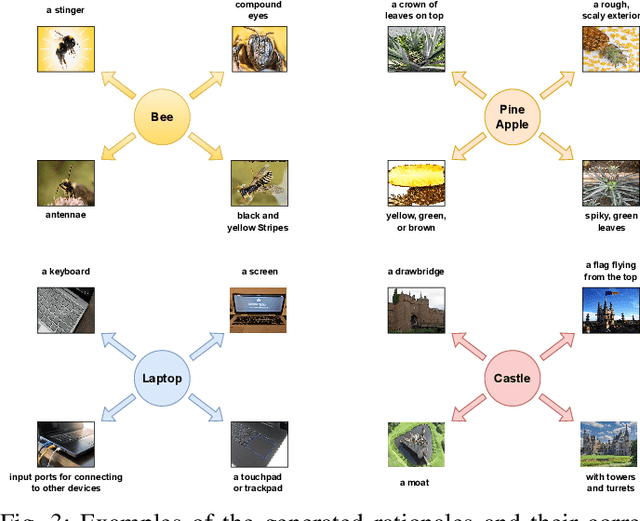

Large Vision Language Models (VLMs), such as CLIP, have significantly contributed to various computer vision tasks, including object recognition and object detection. Their open vocabulary feature enhances their value. However, their black-box nature and lack of explainability in predictions make them less trustworthy in critical domains. Recently, some work has been done to force VLMs to provide reasonable rationales for object recognition, but this often comes at the expense of classification accuracy. In this paper, we first propose a mathematical definition of explainability in the object recognition task based on the joint probability distribution of categories and rationales, then leverage this definition to fine-tune CLIP in an explainable manner. Through evaluations of different datasets, our method demonstrates state-of-the-art performance in explainable classification. Notably, it excels in zero-shot settings, showcasing its adaptability. This advancement improves explainable object recognition, enhancing trust across diverse applications. The code will be made available online upon publication.