 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECOR: Explainable CLIP for Object Recognition
Apr 19, 2024
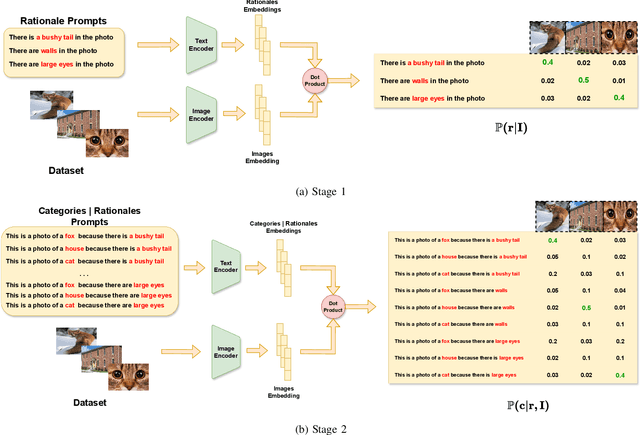
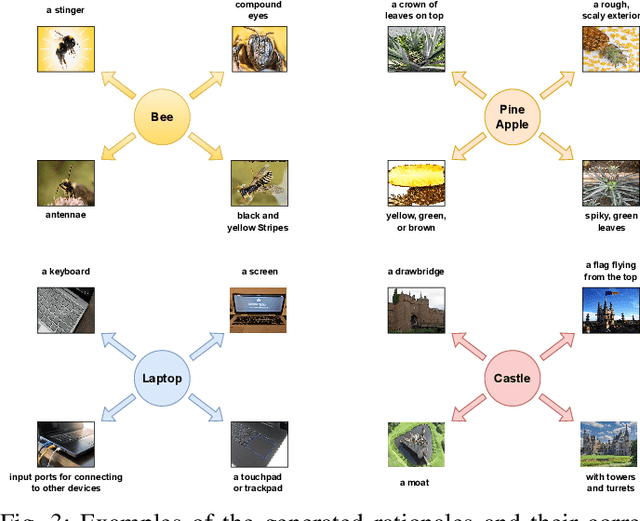

Large Vision Language Models (VLMs), such as CLIP, have significantly contributed to various computer vision tasks, including object recognition and object detection. Their open vocabulary feature enhances their value. However, their black-box nature and lack of explainability in predictions make them less trustworthy in critical domains. Recently, some work has been done to force VLMs to provide reasonable rationales for object recognition, but this often comes at the expense of classification accuracy. In this paper, we first propose a mathematical definition of explainability in the object recognition task based on the joint probability distribution of categories and rationales, then leverage this definition to fine-tune CLIP in an explainable manner. Through evaluations of different datasets, our method demonstrates state-of-the-art performance in explainable classification. Notably, it excels in zero-shot settings, showcasing its adaptability. This advancement improves explainable object recognition, enhancing trust across diverse applications. The code will be made available online upon publication.