 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Vino Veritas and Vulnerabilities: Examining LLM Safety via Drunk Language Inducement
Jan 19, 2026Humans are susceptible to undesirable behaviours and privacy leaks under the influence of alcohol. This paper investigates drunk language, i.e., text written under the influence of alcohol, as a driver for safety failures in large language models (LLMs). We investigate three mechanisms for inducing drunk language in LLMs: persona-based prompting, causal fine-tuning, and reinforcement-based post-training. When evaluated on 5 LLMs, we observe a higher susceptibility to jailbreaking on JailbreakBench (even in the presence of defences) and privacy leaks on ConfAIde, where both benchmarks are in English, as compared to the base LLMs as well as previously reported approaches. Via a robust combination of manual evaluation and LLM-based evaluators and analysis of error categories, our findings highlight a correspondence between human-intoxicated behaviour, and anthropomorphism in LLMs induced with drunk language. The simplicity and efficiency of our drunk language inducement approaches position them as potential counters for LLM safety tuning, highlighting significant risks to LLM safety.
VISPA: Pluralistic Alignment via Automatic Value Selection and Activation
Jan 19, 2026As large language models are increasingly used in high-stakes domains, it is essential that their outputs reflect not average} human preference, rather range of varying perspectives. Achieving such pluralism, however, remains challenging. Existing approaches consider limited values or rely on prompt-level interventions, lacking value control and representation. To address this, we introduce VISPA, a training-free pluralistic alignment framework, that enables direct control over value expression by dynamic selection and internal model activation steering. Across extensive empirical studies spanning multiple models and evaluation settings, we show VISPA is performant across all pluralistic alignment modes in healthcare and beyond. Further analysis reveals VISPA is adaptable with different steering initiations, model, and/or values. These results suggest that pluralistic alignment can be achieved through internal activation mechanisms, offering a scalable path toward language models that serves all.
VITAL: A New Dataset for Benchmarking Pluralistic Alignment in Healthcare
Feb 19, 2025

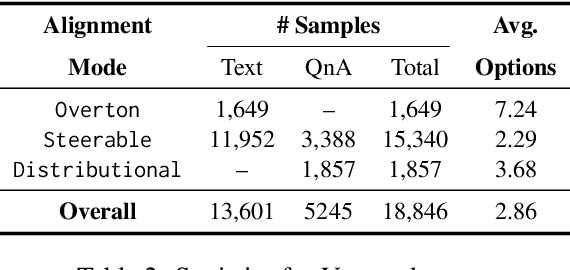

Alignment techniques have become central to ensuring that Large Language Models (LLMs) generate outputs consistent with human values. However, existing alignment paradigms often model an averaged or monolithic preference, failing to account for the diversity of perspectives across cultures, demographics, and communities. This limitation is particularly critical in health-related scenarios, where plurality is essential due to the influence of culture, religion, personal values, and conflicting opinions. Despite progress in pluralistic alignment, no prior work has focused on health, likely due to the unavailability of publicly available datasets. To address this gap, we introduce VITAL, a new benchmark dataset comprising 13.1K value-laden situations and 5.4K multiple-choice questions focused on health, designed to assess and benchmark pluralistic alignment methodologies. Through extensive evaluation of eight LLMs of varying sizes, we demonstrate that existing pluralistic alignment techniques fall short in effectively accommodating diverse healthcare beliefs, underscoring the need for tailored AI alignment in specific domains. This work highlights the limitations of current approaches and lays the groundwork for developing health-specific alignment solutions.
WET: Overcoming Paraphrasing Vulnerabilities in Embeddings-as-a-Service with Linear Transformation Watermarks
Aug 29, 2024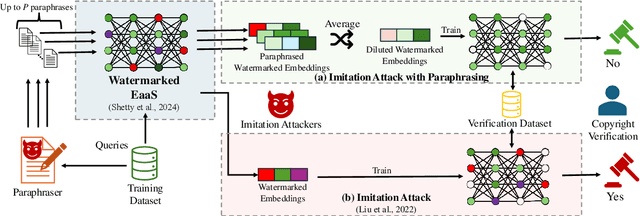
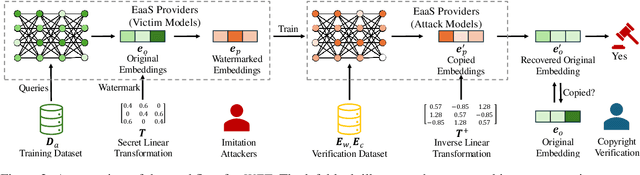
Embeddings-as-a-Service (EaaS) is a service offered by large language model (LLM) developers to supply embeddings generated by LLMs. Previous research suggests that EaaS is prone to imitation attacks -- attacks that clone the underlying EaaS model by training another model on the queried embeddings. As a result, EaaS watermarks are introduced to protect the intellectual property of EaaS providers. In this paper, we first show that existing EaaS watermarks can be removed by paraphrasing when attackers clone the model. Subsequently, we propose a novel watermarking technique that involves linearly transforming the embeddings, and show that it is empirically and theoretically robust against paraphrasing.
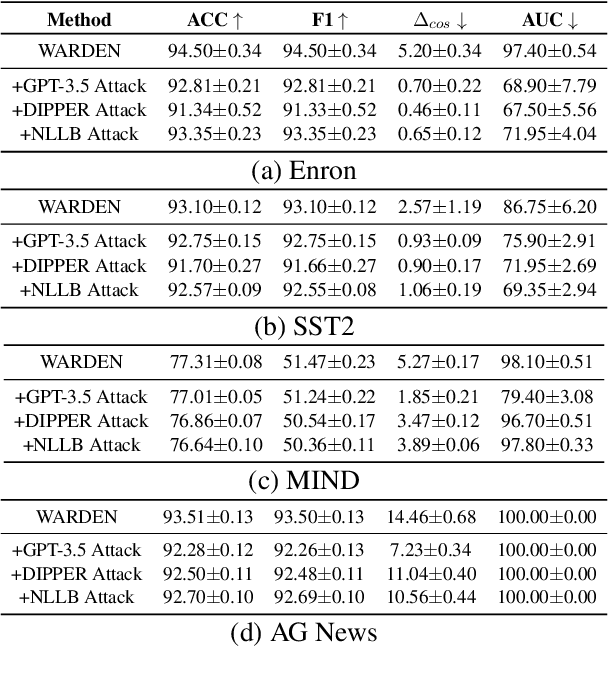
WARDEN: Multi-Directional Backdoor Watermarks for Embedding-as-a-Service Copyright Protection
Mar 03, 2024Embedding as a Service (EaaS) has become a widely adopted solution, which offers feature extraction capabilities for addressing various downstream tasks in Natural Language Processing (NLP). Prior studies have shown that EaaS can be prone to model extraction attacks; nevertheless, this concern could be mitigated by adding backdoor watermarks to the text embeddings and subsequently verifying the attack models post-publication. Through the analysis of the recent watermarking strategy for EaaS, EmbMarker, we design a novel CSE (Clustering, Selection, Elimination) attack that removes the backdoor watermark while maintaining the high utility of embeddings, indicating that the previous watermarking approach can be breached. In response to this new threat, we propose a new protocol to make the removal of watermarks more challenging by incorporating multiple possible watermark directions. Our defense approach, WARDEN, notably increases the stealthiness of watermarks and empirically has been shown effective against CSE attack.