 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQoS-Aware Hierarchical Reinforcement Learning for Joint Link Selection and Trajectory Optimization in SAGIN-Supported UAV Mobility Management
Dec 17, 2025Due to the significant variations in unmanned aerial vehicle (UAV) altitude and horizontal mobility, it becomes difficult for any single network to ensure continuous and reliable threedimensional coverage. Towards that end, the space-air-ground integrated network (SAGIN) has emerged as an essential architecture for enabling ubiquitous UAV connectivity. To address the pronounced disparities in coverage and signal characteristics across heterogeneous networks, this paper formulates UAV mobility management in SAGIN as a constrained multi-objective joint optimization problem. The formulation couples discrete link selection with continuous trajectory optimization. Building on this, we propose a two-level multi-agent hierarchical deep reinforcement learning (HDRL) framework that decomposes the problem into two alternately solvable subproblems. To map complex link selection decisions into a compact discrete action space, we conceive a double deep Q-network (DDQN) algorithm in the top-level, which achieves stable and high-quality policy learning through double Q-value estimation. To handle the continuous trajectory action space while satisfying quality of service (QoS) constraints, we integrate the maximum-entropy mechanism of the soft actor-critic (SAC) and employ a Lagrangian-based constrained SAC (CSAC) algorithm in the lower-level that dynamically adjusts the Lagrange multipliers to balance constraint satisfaction and policy optimization. Moreover, the proposed algorithm can be extended to multi-UAV scenarios under the centralized training and decentralized execution (CTDE) paradigm, which enables more generalizable policies. Simulation results demonstrate that the proposed scheme substantially outperforms existing benchmarks in throughput, link switching frequency and QoS satisfaction.
Asynchronous Risk-Aware Multi-Agent Packet Routing for Ultra-Dense LEO Satellite Networks
Oct 31, 2025The rise of ultra-dense LEO constellations creates a complex and asynchronous network environment, driven by their massive scale, dynamic topologies, and significant delays. This unique complexity demands an adaptive packet routing algorithm that is asynchronous, risk-aware, and capable of balancing diverse and often conflicting QoS objectives in a decentralized manner. However, existing methods fail to address this need, as they typically rely on impractical synchronous decision-making and/or risk-oblivious approaches. To tackle this gap, we introduce PRIMAL, an event-driven multi-agent routing framework designed specifically to allow each satellite to act independently on its own event-driven timeline, while managing the risk of worst-case performance degradation via a principled primal-dual approach. This is achieved by enabling agents to learn the full cost distribution of the targeted QoS objectives and constrain tail-end risks. Extensive simulations on a LEO constellation with 1584 satellites validate its superiority in effectively optimizing latency and balancing load. Compared to a recent risk-oblivious baseline, it reduces queuing delay by over 70%, and achieves a nearly 12 ms end-to-end delay reduction in loaded scenarios. This is accomplished by resolving the core conflict between naive shortest-path finding and congestion avoidance, highlighting such autonomous risk-awareness as a key to robust routing.
SCA-LLM: Spectral-Attentive Channel Prediction with Large Language Models in MIMO-OFDM
Sep 09, 2025

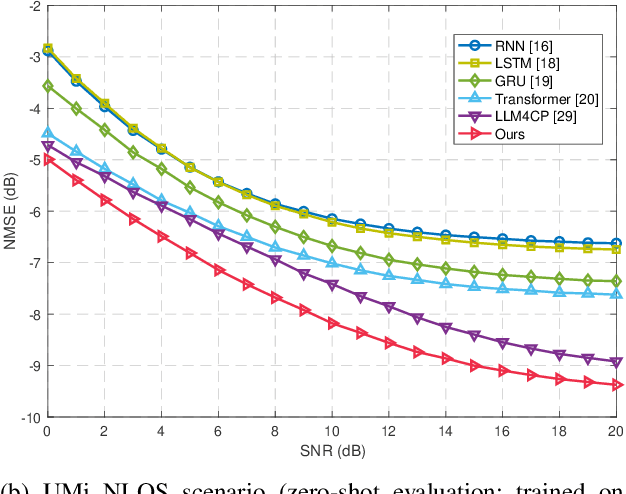

In recent years, the success of large language models (LLMs) has inspired growing interest in exploring their potential applications in wireless communications, especially for channel prediction tasks. However, directly applying LLMs to channel prediction faces a domain mismatch issue stemming from their text-based pre-training. To mitigate this, the ``adapter + LLM" paradigm has emerged, where an adapter is designed to bridge the domain gap between the channel state information (CSI) data and LLMs. While showing initial success, existing adapters may not fully exploit the potential of this paradigm. To address this limitation, this work provides a key insight that learning representations from the spectral components of CSI features can more effectively help bridge the domain gap. Accordingly, we propose a spectral-attentive framework, named SCA-LLM, for channel prediction in multiple-input multiple-output orthogonal frequency division multiplexing (MIMO-OFDM) systems. Specifically, its novel adapter can capture finer spectral details and better adapt the LLM for channel prediction than previous methods. Extensive simulations show that SCA-LLM achieves state-of-the-art prediction performance and strong generalization, yielding up to $-2.4~\text{dB}$ normalized mean squared error (NMSE) advantage over the previous LLM based method. Ablation studies further confirm the superiority of SCA-LLM in mitigating domain mismatch.
WARDEN: Multi-Directional Backdoor Watermarks for Embedding-as-a-Service Copyright Protection
Mar 03, 2024Embedding as a Service (EaaS) has become a widely adopted solution, which offers feature extraction capabilities for addressing various downstream tasks in Natural Language Processing (NLP). Prior studies have shown that EaaS can be prone to model extraction attacks; nevertheless, this concern could be mitigated by adding backdoor watermarks to the text embeddings and subsequently verifying the attack models post-publication. Through the analysis of the recent watermarking strategy for EaaS, EmbMarker, we design a novel CSE (Clustering, Selection, Elimination) attack that removes the backdoor watermark while maintaining the high utility of embeddings, indicating that the previous watermarking approach can be breached. In response to this new threat, we propose a new protocol to make the removal of watermarks more challenging by incorporating multiple possible watermark directions. Our defense approach, WARDEN, notably increases the stealthiness of watermarks and empirically has been shown effective against CSE attack.
Learning based signal detection for MIMO systems with unknown noise statistics
Jan 21, 2021
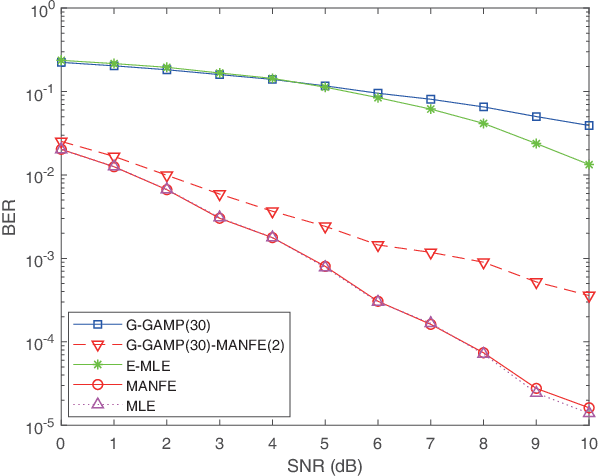
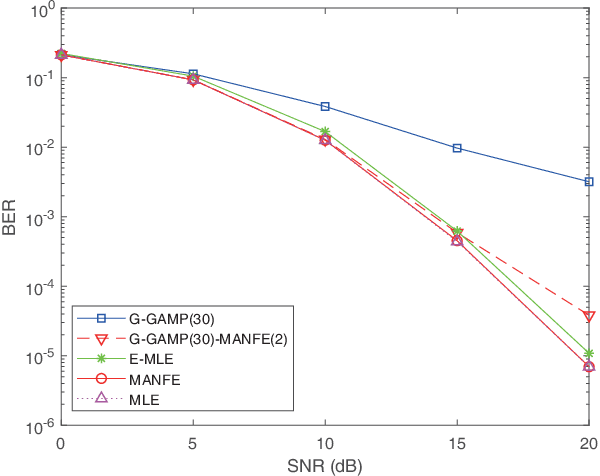
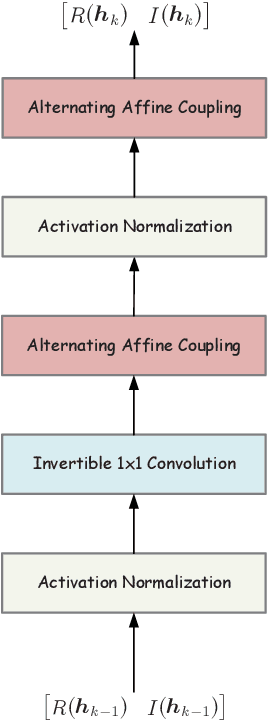
This paper aims to devise a generalized maximum likelihood (ML) estimator to robustly detect signals with unknown noise statistics in multiple-input multiple-output (MIMO) systems. In practice, there is little or even no statistical knowledge on the system noise, which in many cases is non-Gaussian, impulsive and not analyzable. Existing detection methods have mainly focused on specific noise models, which are not robust enough with unknown noise statistics. To tackle this issue, we propose a novel ML detection framework to effectively recover the desired signal. Our framework is a fully probabilistic one that can efficiently approximate the unknown noise distribution through a normalizing flow. Importantly, this framework is driven by an unsupervised learning approach, where only the noise samples are required. To reduce the computational complexity, we further present a low-complexity version of the framework, by utilizing an initial estimation to reduce the search space. Simulation results show that our framework outperforms other existing algorithms in terms of bit error rate (BER) in non-analytical noise environments, while it can reach the ML performance bound in analytical noise environments. The code of this paper is available at https://github.com/skypitcher/manfe.
Towards Optimally Efficient Tree Search with Deep Temporal Difference Learning
Jan 21, 2021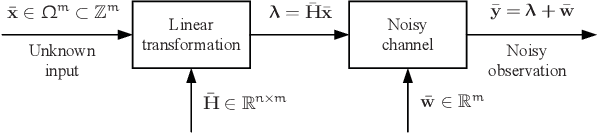
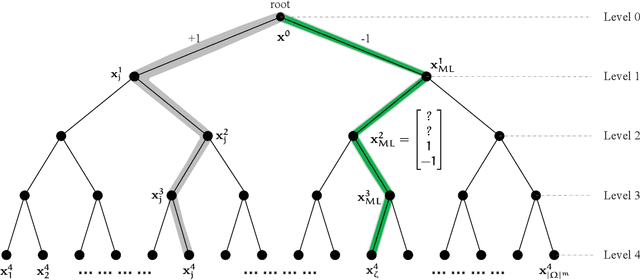
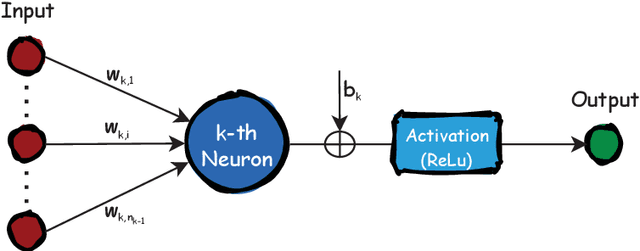
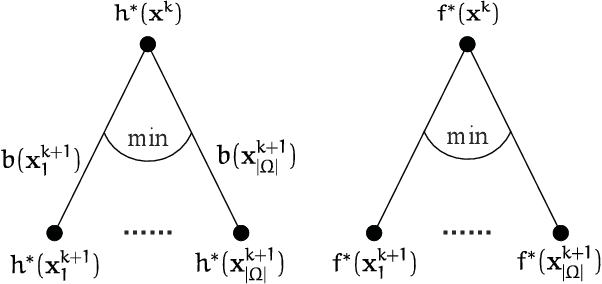
This paper investigates the classical integer least-squares problem which estimates integer signals from linear models. The problem is NP-hard and often arises in diverse applications such as signal processing, bioinformatics, communications and machine learning, to name a few. Since the existing optimal search strategies involve prohibitive complexities, they are hard to be adopted in large-scale problems. To address this issue, we propose a general hyper-accelerated tree search (HATS) algorithm by employing a deep neural network to estimate the optimal heuristic for the underlying simplified memory-bounded A* algorithm, and the proposed algorithm can be easily generalized with other heuristic search algorithms. Inspired by the temporal difference learning, we further propose a training strategy which enables the network to approach the optimal heuristic precisely and consistently, thus the proposed algorithm can reach nearly the optimal efficiency when the estimation error is small enough. Experiments show that the proposed algorithm can reach almost the optimal maximum likelihood estimate performance in large-scale problems, with a very low complexity in both time and space. The code of this paper is avaliable at https://github.com/skypitcher/hats.
FeCaffe: FPGA-enabled Caffe with OpenCL for Deep Learning Training and Inference on Intel Stratix 10
Nov 18, 2019
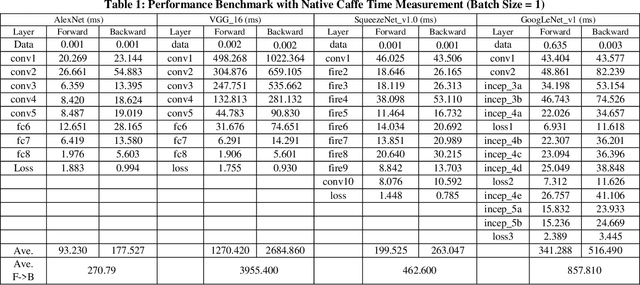
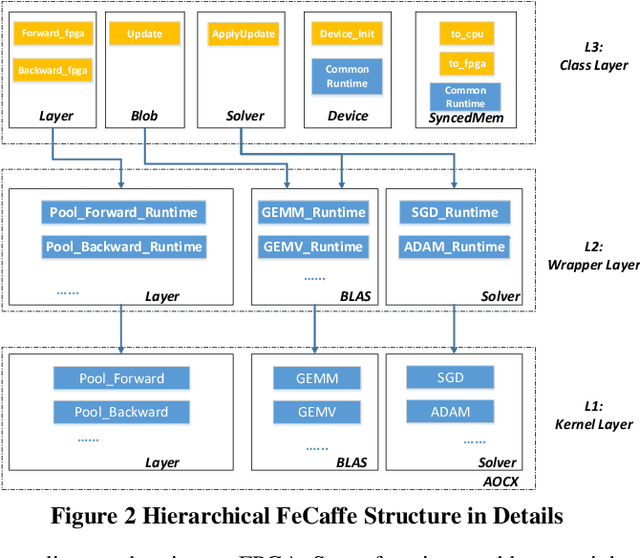
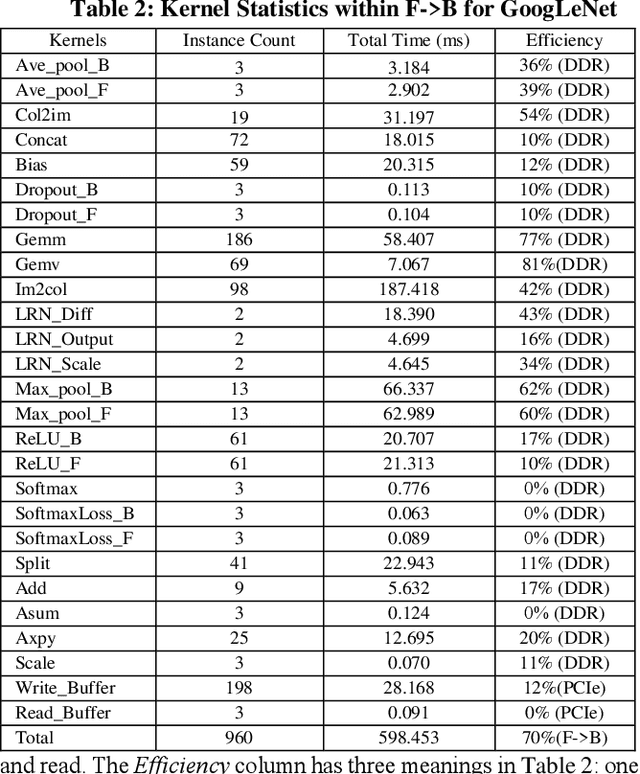
Deep learning and Convolutional Neural Network (CNN) have becoming increasingly more popular and important in both academic and industrial areas in recent years cause they are able to provide better accuracy and result in classification, detection and recognition areas, compared to traditional approaches. Currently, there are many popular frameworks in the market for deep learning development, such as Caffe, TensorFlow, Pytorch, and most of frameworks natively support CPU and consider GPU as the mainline accelerator by default. FPGA device, viewed as a potential heterogeneous platform, still cannot provide a comprehensive support for CNN development in popular frameworks, in particular to the training phase. In this paper, we firstly propose the FeCaffe, i.e. FPGA-enabled Caffe, a hierarchical software and hardware design methodology based on the Caffe to enable FPGA to support mainline deep learning development features, e.g. training and inference with Caffe. Furthermore, we provide some benchmarks with FeCaffe by taking some classical CNN networks as examples, and further analysis of kernel execution time in details accordingly. Finally, some optimization directions including FPGA kernel design, system pipeline, network architecture, user case application and heterogeneous platform levels, have been proposed gradually to improve FeCaffe performance and efficiency. The result demonstrates the proposed FeCaffe is capable of supporting almost full features during CNN network training and inference respectively with high degree of design flexibility, expansibility and reusability for deep learning development. Compared to prior studies, our architecture can support more network and training settings, and current configuration can achieve 6.4x and 8.4x average execution time improvement for forward and backward respectively for LeNet.