 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMI-IRL: Contrastive Multi-Intention Inverse Reinforcement Learning
Feb 07, 2026Inverse Reinforcement Learning (IRL) seeks to infer reward functions from expert demonstrations. When demonstrations originate from multiple experts with different intentions, the problem is known as Multi-Intention IRL (MI-IRL). Recent deep generative MI-IRL approaches couple behavior clustering and reward learning, but typically require prior knowledge of the number of true behavioral modes $K^*$. This reliance on expert knowledge limits their adaptability to new behaviors, and only enables analysis related to the learned rewards, and not across the behavior modes used to train them. We propose Contrastive Multi-Intention IRL (CoMI-IRL), a transformer-based unsupervised framework that decouples behavior representation and clustering from downstream reward learning. Our experiments show that CoMI-IRL outperforms existing approaches without a priori knowledge of $K^*$ or labels, while allowing for visual interpretation of behavior relationships and adaptation to unseen behavior without full retraining.
Taking a SEAT: Predicting Value Interpretations from Sentiment, Emotion, Argument, and Topic Annotations
Oct 02, 2025Our interpretation of value concepts is shaped by our sociocultural background and lived experiences, and is thus subjective. Recognizing individual value interpretations is important for developing AI systems that can align with diverse human perspectives and avoid bias toward majority viewpoints. To this end, we investigate whether a language model can predict individual value interpretations by leveraging multi-dimensional subjective annotations as a proxy for their interpretive lens. That is, we evaluate whether providing examples of how an individual annotates Sentiment, Emotion, Argument, and Topics (SEAT dimensions) helps a language model in predicting their value interpretations. Our experiment across different zero- and few-shot settings demonstrates that providing all SEAT dimensions simultaneously yields superior performance compared to individual dimensions and a baseline where no information about the individual is provided. Furthermore, individual variations across annotators highlight the importance of accounting for the incorporation of individual subjective annotators. To the best of our knowledge, this controlled setting, although small in size, is the first attempt to go beyond demographics and investigate the impact of annotation behavior on value prediction, providing a solid foundation for future large-scale validation.
Feasible Action Space Reduction for Quantifying Causal Responsibility in Continuous Spatial Interactions
May 23, 2025Understanding the causal influence of one agent on another agent is crucial for safely deploying artificially intelligent systems such as automated vehicles and mobile robots into human-inhabited environments. Existing models of causal responsibility deal with simplified abstractions of scenarios with discrete actions, thus, limiting real-world use when understanding responsibility in spatial interactions. Based on the assumption that spatially interacting agents are embedded in a scene and must follow an action at each instant, Feasible Action-Space Reduction (FeAR) was proposed as a metric for causal responsibility in a grid-world setting with discrete actions. Since real-world interactions involve continuous action spaces, this paper proposes a formulation of the FeAR metric for measuring causal responsibility in space-continuous interactions. We illustrate the utility of the metric in prototypical space-sharing conflicts, and showcase its applications for analysing backward-looking responsibility and in estimating forward-looking responsibility to guide agent decision making. Our results highlight the potential of the FeAR metric for designing and engineering artificial agents, as well as for assessing the responsibility of agents around humans.
ARMCHAIR: integrated inverse reinforcement learning and model predictive control for human-robot collaboration
Feb 29, 2024



One of the key issues in human-robot collaboration is the development of computational models that allow robots to predict and adapt to human behavior. Much progress has been achieved in developing such models, as well as control techniques that address the autonomy problems of motion planning and decision-making in robotics. However, the integration of computational models of human behavior with such control techniques still poses a major challenge, resulting in a bottleneck for efficient collaborative human-robot teams. In this context, we present a novel architecture for human-robot collaboration: Adaptive Robot Motion for Collaboration with Humans using Adversarial Inverse Reinforcement learning (ARMCHAIR). Our solution leverages adversarial inverse reinforcement learning and model predictive control to compute optimal trajectories and decisions for a mobile multi-robot system that collaborates with a human in an exploration task. During the mission, ARMCHAIR operates without human intervention, autonomously identifying the necessity to support and acting accordingly. Our approach also explicitly addresses the network connectivity requirement of the human-robot team. Extensive simulation-based evaluations demonstrate that ARMCHAIR allows a group of robots to safely support a simulated human in an exploration scenario, preventing collisions and network disconnections, and improving the overall performance of the task.
Explaining Learned Reward Functions with Counterfactual Trajectories
Feb 07, 2024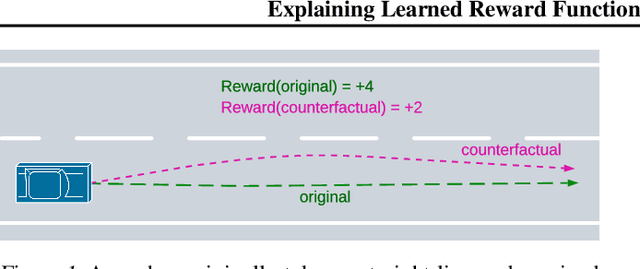
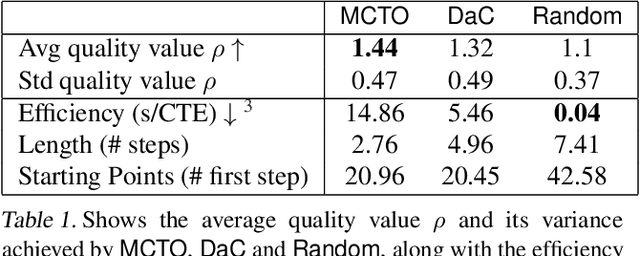


Learning rewards from human behaviour or feedback is a promising approach to aligning AI systems with human values but fails to consistently extract correct reward functions. Interpretability tools could enable users to understand and evaluate possible flaws in learned reward functions. We propose Counterfactual Trajectory Explanations (CTEs) to interpret reward functions in reinforcement learning by contrasting an original with a counterfactual partial trajectory and the rewards they each receive. We derive six quality criteria for CTEs and propose a novel Monte-Carlo-based algorithm for generating CTEs that optimises these quality criteria. Finally, we measure how informative the generated explanations are to a proxy-human model by training it on CTEs. CTEs are demonstrably informative for the proxy-human model, increasing the similarity between its predictions and the reward function on unseen trajectories. Further, it learns to accurately judge differences in rewards between trajectories and generalises to out-of-distribution examples. Although CTEs do not lead to a perfect understanding of the reward, our method, and more generally the adaptation of XAI methods, are presented as a fruitful approach for interpreting learned reward functions.
Reflective Hybrid Intelligence for Meaningful Human Control in Decision-Support Systems
Jul 12, 2023



With the growing capabilities and pervasiveness of AI systems, societies must collectively choose between reduced human autonomy, endangered democracies and limited human rights, and AI that is aligned to human and social values, nurturing collaboration, resilience, knowledge and ethical behaviour. In this chapter, we introduce the notion of self-reflective AI systems for meaningful human control over AI systems. Focusing on decision support systems, we propose a framework that integrates knowledge from psychology and philosophy with formal reasoning methods and machine learning approaches to create AI systems responsive to human values and social norms. We also propose a possible research approach to design and develop self-reflective capability in AI systems. Finally, we argue that self-reflective AI systems can lead to self-reflective hybrid systems (human + AI), thus increasing meaningful human control and empowering human moral reasoning by providing comprehensible information and insights on possible human moral blind spots.
Meaningful human control over AI systems: beyond talking the talk
Nov 25, 2021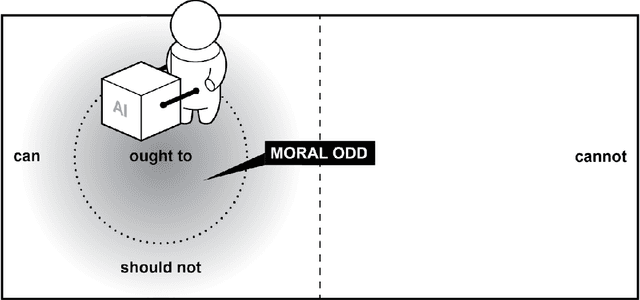
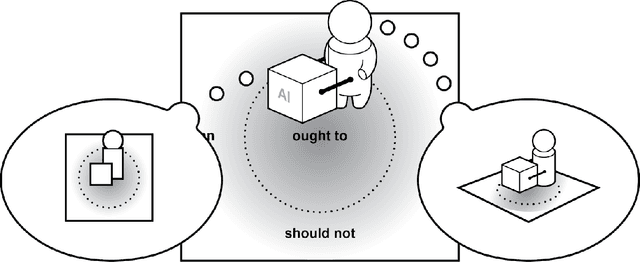
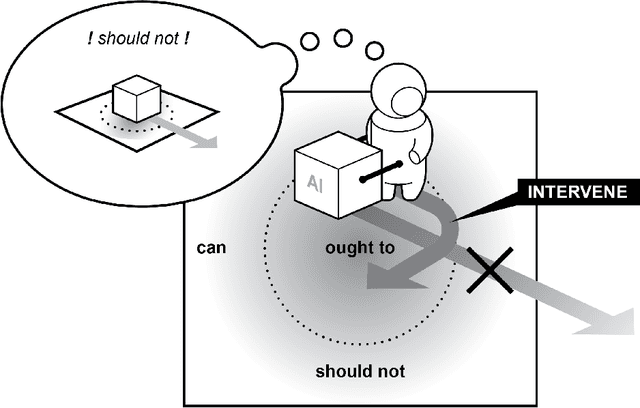
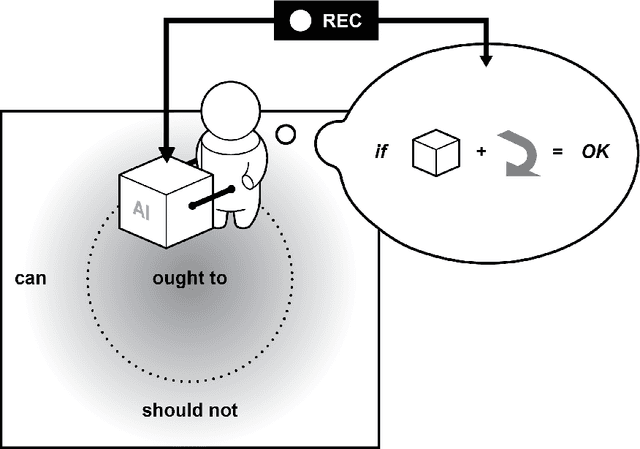
The concept of meaningful human control has been proposed to address responsibility gaps and mitigate them by establishing conditions that enable a proper attribution of responsibility for humans (e.g., users, designers and developers, manufacturers, legislators). However, the relevant discussions around meaningful human control have so far not resulted in clear requirements for researchers, designers, and engineers. As a result, there is no consensus on how to assess whether a designed AI system is under meaningful human control, making the practical development of AI-based systems that remain under meaningful human control challenging. In this paper, we address the gap between philosophical theory and engineering practice by identifying four actionable properties which AI-based systems must have to be under meaningful human control. First, a system in which humans and AI algorithms interact should have an explicitly defined domain of morally loaded situations within which the system ought to operate. Second, humans and AI agents within the system should have appropriate and mutually compatible representations. Third, responsibility attributed to a human should be commensurate with that human's ability and authority to control the system. Fourth, there should be explicit links between the actions of the AI agents and actions of humans who are aware of their moral responsibility. We argue these four properties are necessary for AI systems under meaningful human control, and provide possible directions to incorporate them into practice. We illustrate these properties with two use cases, automated vehicle and AI-based hiring. We believe these four properties will support practically-minded professionals to take concrete steps toward designing and engineering for AI systems that facilitate meaningful human control and responsibility.
Improving Confidence in the Estimation of Values and Norms
Apr 02, 2020
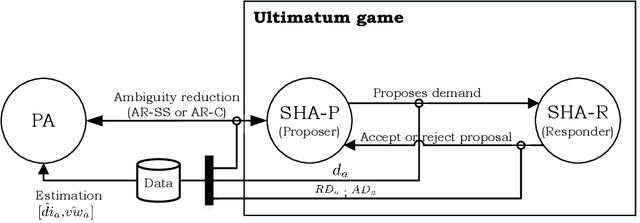

Autonomous agents (AA) will increasingly be interacting with us in our daily lives. While we want the benefits attached to AAs, it is essential that their behavior is aligned with our values and norms. Hence, an AA will need to estimate the values and norms of the humans it interacts with, which is not a straightforward task when solely observing an agent's behavior. This paper analyses to what extent an AA is able to estimate the values and norms of a simulated human agent (SHA) based on its actions in the ultimatum game. We present two methods to reduce ambiguity in profiling the SHAs: one based on search space exploration and another based on counterfactual analysis. We found that both methods are able to increase the confidence in estimating human values and norms, but differ in their applicability, the latter being more efficient when the number of interactions with the agent is to be minimized. These insights are useful to improve the alignment of AAs with human values and norms.