 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Continuous Control Policies for Information-Theoretic Active Perception
Paper and Code
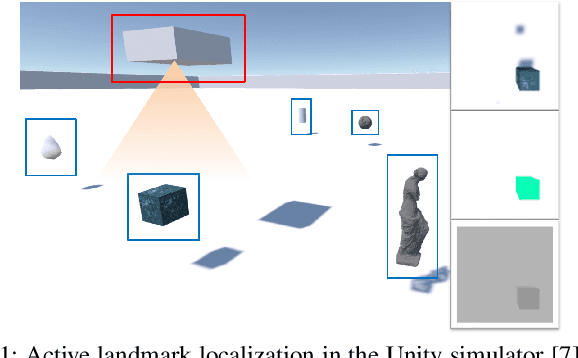
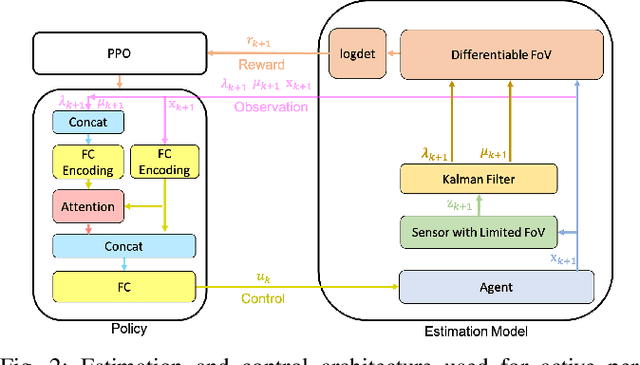
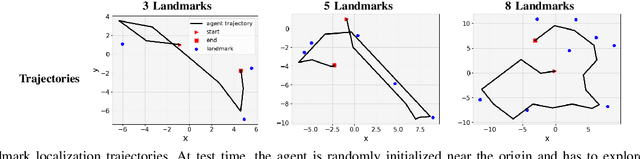
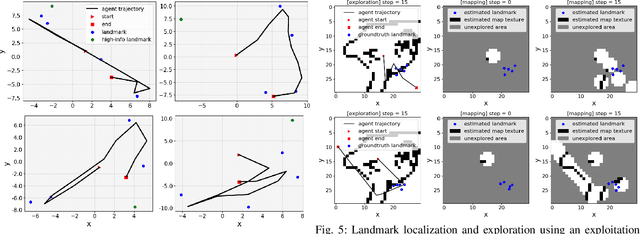
This paper proposes a method for learning continuous control policies for active landmark localization and exploration using an information-theoretic cost. We consider a mobile robot detecting landmarks within a limited sensing range, and tackle the problem of learning a control policy that maximizes the mutual information between the landmark states and the sensor observations. We employ a Kalman filter to convert the partially observable problem in the landmark state to Markov decision process (MDP), a differentiable field of view to shape the reward, and an attention-based neural network to represent the control policy. The approach is further unified with active volumetric mapping to promote exploration in addition to landmark localization. The performance is demonstrated in several simulated landmark localization tasks in comparison with benchmark methods.