 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Ensemble Logic
Aug 26, 2024We introduce Temporal Ensemble Logic (TEL), a monadic, first-order modal logic for linear-time temporal reasoning. TEL includes primitive temporal constructs such as ``always up to $t$ time later'' ($\Box_t$), ``sometimes before $t$ time in the future'' ($\Diamond_t$), and ``$t$-time later'' $\varphi_t$. TEL has been motivated from the requirement for rigor and reproducibility for cohort specification and discovery in clinical and population health research, to fill a gap in formalizing temporal reasoning in biomedicine. In this paper, we first introduce TEL in a general set up, with discrete and dense time as special cases. We then focus on the theoretical development of discrete TEL on the temporal domain of positive integers $\mathbb{N}^+$, denoted as ${\rm TEL}_{\mathbb{N}^+}$. ${\rm TEL}_{\mathbb{N}^+}$ is strictly more expressive than the standard monadic second order logic, characterized by B\"{u}chi automata. We present its formal semantics, a proof system, and provide a proof for the undecidability of the satisfiability of ${\rm TEL}_{\mathbb{N}^+}$. We also discuss expressiveness and decidability fragments for ${\rm TEL}_{\mathbb{N}^+}$, followed by illustrative applications.
Cross-Vendor CT Image Data Harmonization Using CVH-CT
Oct 19, 2021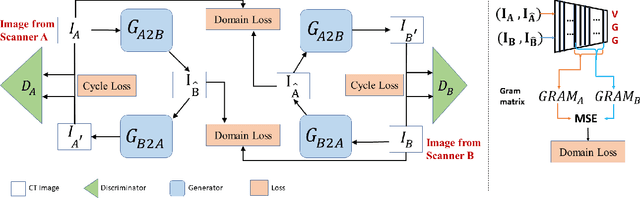

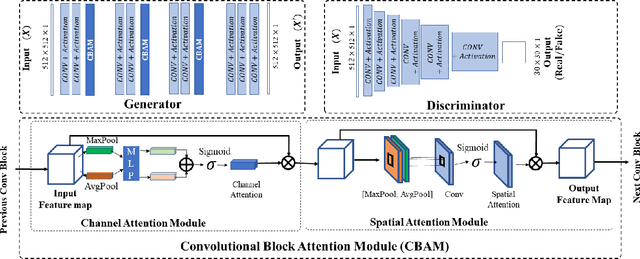
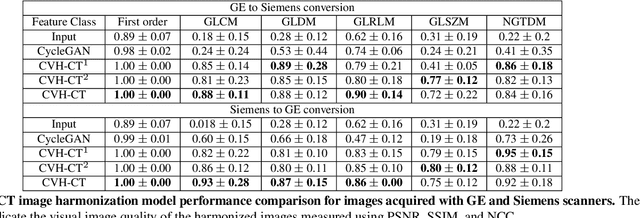
While remarkable advances have been made in Computed Tomography (CT), most of the existing efforts focus on imaging enhancement while reducing radiation dose. How to harmonize CT image data captured using different scanners is vital in cross-center large-scale radiomics studies but remains the boundary to explore. Furthermore, the lack of paired training image problem makes it computationally challenging to adopt existing deep learning models. %developed for CT image standardization. %this problem more challenging. We propose a novel deep learning approach called CVH-CT for harmonizing CT images captured using scanners from different vendors. The generator of CVH-CT uses a self-attention mechanism to learn the scanner-related information. We also propose a VGG feature-based domain loss to effectively extract texture properties from unpaired image data to learn the scanner-based texture distributions. The experimental results show that CVH-CT is clearly better than the baselines because of the use of the proposed domain loss, and CVH-CT can effectively reduce the scanner-related variability in terms of radiomic features.
CT Image Harmonization for Enhancing Radiomics Studies
Jul 03, 2021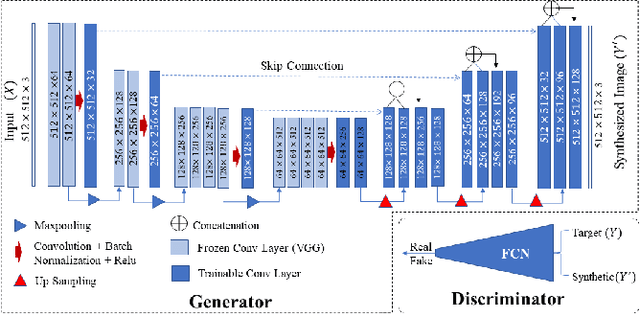
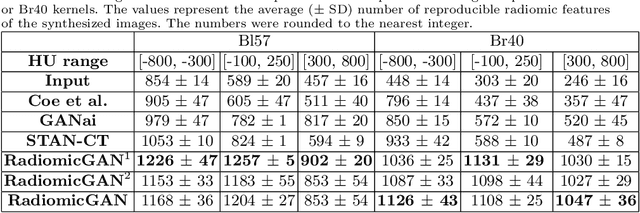
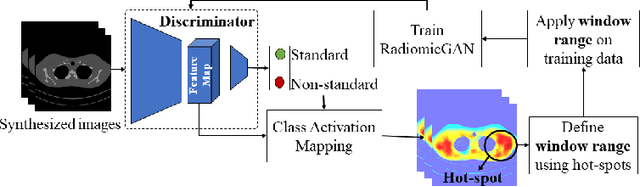

While remarkable advances have been made in Computed Tomography (CT), capturing CT images with non-standardized protocols causes low reproducibility regarding radiomic features, forming a barrier on CT image analysis in a large scale. RadiomicGAN is developed to effectively mitigate the discrepancy caused by using non-standard reconstruction kernels. RadiomicGAN consists of hybrid neural blocks including both pre-trained and trainable layers adopted to learn radiomic feature distributions efficiently. A novel training approach, called Dynamic Window-based Training, has been developed to smoothly transform the pre-trained model to the medical imaging domain. Model performance evaluated using 1401 radiomic features show that RadiomicGAN clearly outperforms the state-of-art image standardization models.
STAN-CT: Standardizing CT Image using Generative Adversarial Network
Apr 02, 2020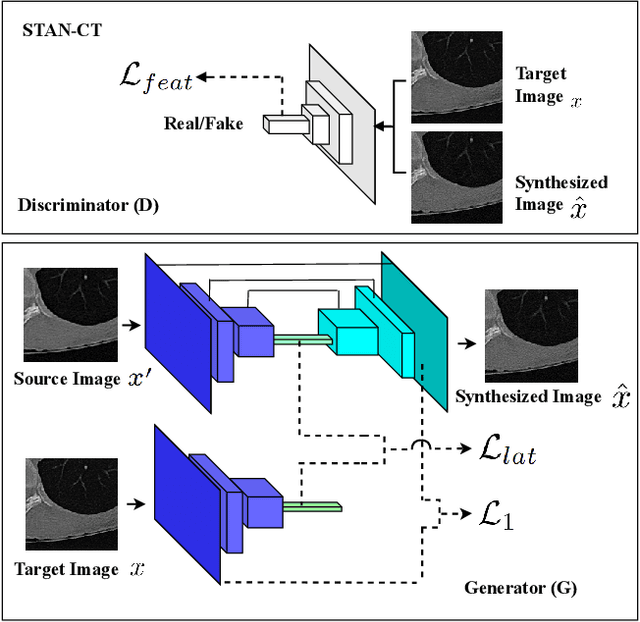


Computed tomography (CT) plays an important role in lung malignancy diagnostics and therapy assessment and facilitating precision medicine delivery. However, the use of personalized imaging protocols poses a challenge in large-scale cross-center CT image radiomic studies. We present an end-to-end solution called STAN-CT for CT image standardization and normalization, which effectively reduces discrepancies in image features caused by using different imaging protocols or using different CT scanners with the same imaging protocol. STAN-CT consists of two components: 1) a novel Generative Adversarial Networks (GAN) model that is capable of effectively learning the data distribution of a standard imaging protocol with only a few rounds of generator training, and 2) an automatic DICOM reconstruction pipeline with systematic image quality control that ensure the generation of high-quality standard DICOM images. Experimental results indicate that the training efficiency and model performance of STAN-CT have been significantly improved compared to the state-of-the-art CT image standardization and normalization algorithms.
Automated Classification of Seizures against Nonseizures: A Deep Learning Approach
Jun 05, 2019

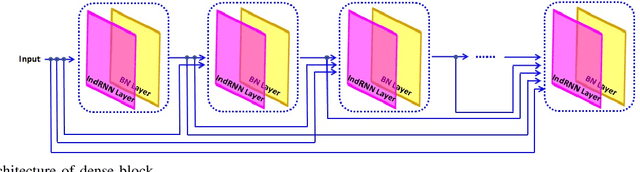
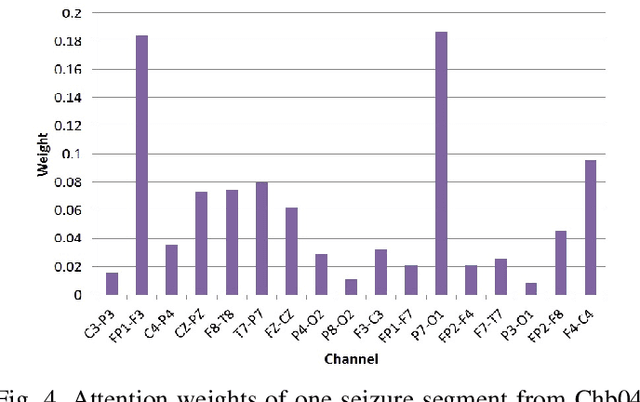
In current clinical practice, electroencephalograms (EEG) are reviewed and analyzed by well-trained neurologists to provide supports for therapeutic decisions. The way of manual reviewing is labor-intensive and error prone. Automatic and accurate seizure/nonseizure classification methods are needed. One major problem is that the EEG signals for seizure state and nonseizure state exhibit considerable variations. In order to capture essential seizure features, this paper integrates an emerging deep learning model, the independently recurrent neural network (IndRNN), with a dense structure and an attention mechanism to exploit temporal and spatial discriminating features and overcome seizure variabilities. The dense structure is to ensure maximum information flow between layers. The attention mechanism is to capture spatial features. Evaluations are performed in cross-validation experiments over the noisy CHB-MIT data set. The obtained average sensitivity, specificity and precision of 88.80%, 88.60% and 88.69% are better than using the current state-of-the-art methods. In addition, we explore how the segment length affects the classification performance. Thirteen different segment lengths are assessed, showing that the classification performance varies over the segment lengths, and the maximal fluctuating margin is more than 4%. Thus, the segment length is an important factor influencing the classification performance.
A Novel Independent RNN Approach to Classification of Seizures against Non-seizures
Mar 22, 2019

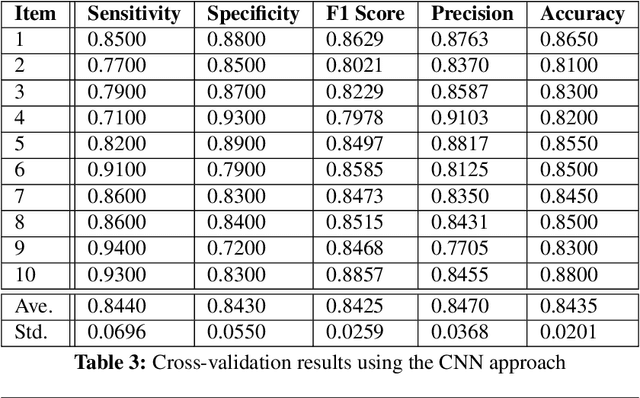

In current clinical practices, electroencephalograms (EEG) are reviewed and analyzed by trained neurologists to provide supports for therapeutic decisions. Manual reviews can be laborious and error prone. Automatic and accurate seizure/non-seizure classification methods are desirable. A critical challenge is that seizure morphologies exhibit considerable variabilities. In order to capture essential seizure features, this paper leverages an emerging deep learning model, the independently recurrent neural network (IndRNN), to construct a new approach for the seizure/non-seizure classification. This new approach gradually expands the time scales, thereby extracting temporal and spatial features from the local time duration to the entire record. Evaluations are conducted with cross-validation experiments across subjects over the noisy data of CHB-MIT. Experimental results demonstrate that the proposed approach outperforms the current state-of-the-art methods. In addition, we explore how the segment length affects the classification performance. Thirteen different segment lengths are assessed, showing that the classification performance varies over the segment lengths, and the maximal fluctuating margin is more than 4%. Thus, the segment length is an important factor influencing the classification performance.