 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage to Pseudo-Episode: Boosting Few-Shot Segmentation by Unlabeled Data
May 14, 2024Few-shot segmentation (FSS) aims to train a model which can segment the object from novel classes with a few labeled samples. The insufficient generalization ability of models leads to unsatisfactory performance when the models lack enough labeled data from the novel classes. Considering that there are abundant unlabeled data available, it is promising to improve the generalization ability by exploiting these various data. For leveraging unlabeled data, we propose a novel method, named Image to Pseudo-Episode (IPE), to generate pseudo-episodes from unlabeled data. Specifically, our method contains two modules, i.e., the pseudo-label generation module and the episode generation module. The former module generates pseudo-labels from unlabeled images by the spectral clustering algorithm, and the latter module generates pseudo-episodes from pseudo-labeled images by data augmentation methods. Extensive experiments on PASCAL-$5^i$ and COCO-$20^i$ demonstrate that our method achieves the state-of-the-art performance for FSS.
Towards Robust Semantic Segmentation against Patch-based Attack via Attention Refinement
Jan 03, 2024The attention mechanism has been proven effective on various visual tasks in recent years. In the semantic segmentation task, the attention mechanism is applied in various methods, including the case of both Convolution Neural Networks (CNN) and Vision Transformer (ViT) as backbones. However, we observe that the attention mechanism is vulnerable to patch-based adversarial attacks. Through the analysis of the effective receptive field, we attribute it to the fact that the wide receptive field brought by global attention may lead to the spread of the adversarial patch. To address this issue, in this paper, we propose a Robust Attention Mechanism (RAM) to improve the robustness of the semantic segmentation model, which can notably relieve the vulnerability against patch-based attacks. Compared to the vallina attention mechanism, RAM introduces two novel modules called Max Attention Suppression and Random Attention Dropout, both of which aim to refine the attention matrix and limit the influence of a single adversarial patch on the semantic segmentation results of other positions. Extensive experiments demonstrate the effectiveness of our RAM to improve the robustness of semantic segmentation models against various patch-based attack methods under different attack settings.
Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation
Apr 09, 2020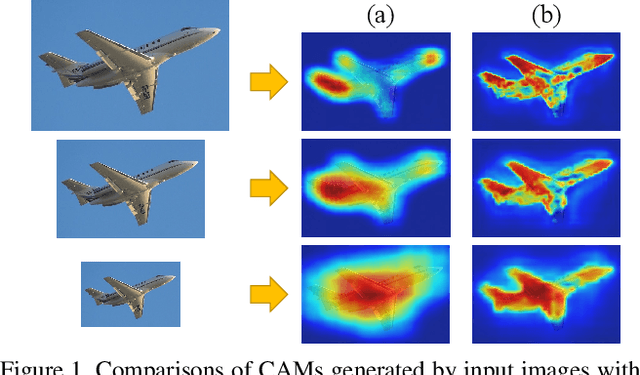
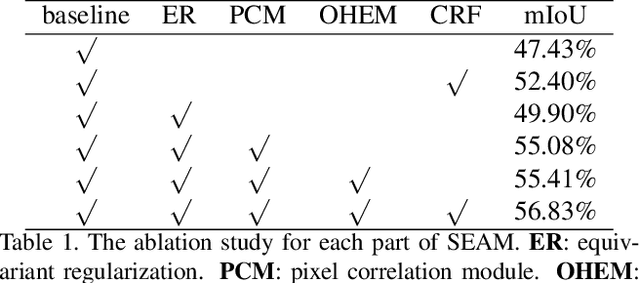
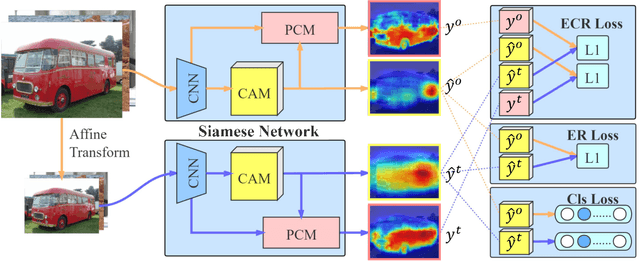

Image-level weakly supervised semantic segmentation is a challenging problem that has been deeply studied in recent years. Most of advanced solutions exploit class activation map (CAM). However, CAMs can hardly serve as the object mask due to the gap between full and weak supervisions. In this paper, we propose a self-supervised equivariant attention mechanism (SEAM) to discover additional supervision and narrow the gap. Our method is based on the observation that equivariance is an implicit constraint in fully supervised semantic segmentation, whose pixel-level labels take the same spatial transformation as the input images during data augmentation. However, this constraint is lost on the CAMs trained by image-level supervision. Therefore, we propose consistency regularization on predicted CAMs from various transformed images to provide self-supervision for network learning. Moreover, we propose a pixel correlation module (PCM), which exploits context appearance information and refines the prediction of current pixel by its similar neighbors, leading to further improvement on CAMs consistency. Extensive experiments on PASCAL VOC 2012 dataset demonstrate our method outperforms state-of-the-art methods using the same level of supervision. The code is released online.
Self-supervised Scale Equivariant Network for Weakly Supervised Semantic Segmentation
Sep 09, 2019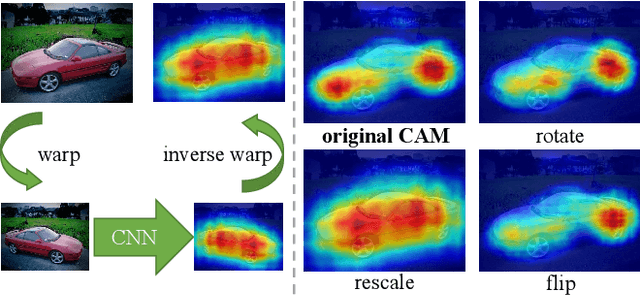

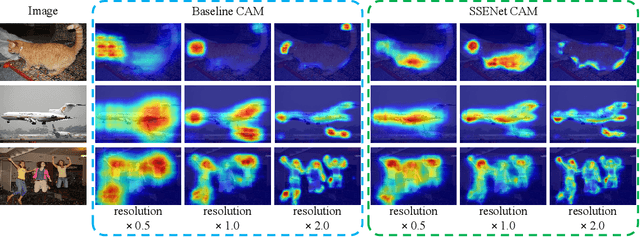

Weakly supervised semantic segmentation has attracted much research interest in recent years considering its advantage of low labeling cost. Most of the advanced algorithms follow the design principle that expands and constrains the seed regions from class activation maps (CAM). As well-known, conventional CAM tends to be incomplete or over-activated due to weak supervision. Fortunately, we find that semantic segmentation has a characteristic of spatial transformation equivariance, which can form a few self-supervisions to help weakly supervised learning. This work mainly explores the advantages of scale equivariant constrains for CAM generation, formulated as a self-supervised scale equivariant network (SSENet). Specifically, a novel scale equivariant regularization is elaborately designed to ensure consistency of CAMs from the same input image with different resolutions. This novel scale equivariant regularization can guide the whole network to learn more accurate class activation. This regularized CAM can be embedded in most recent advanced weakly supervised semantic segmentation framework. Extensive experiments on PASCAL VOC 2012 datasets demonstrate that our method achieves the state-of-the-art performance both quantitatively and qualitatively for weakly supervised semantic segmentation. Code has been made available.