 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Autoencoder: self-supervised disentanglement of static 3D structure and motion
Paper and Code
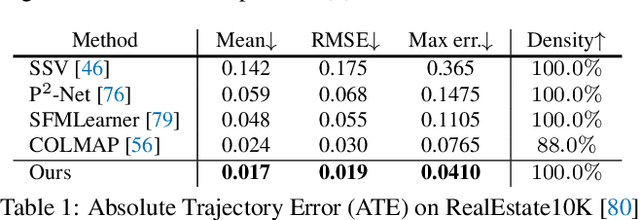
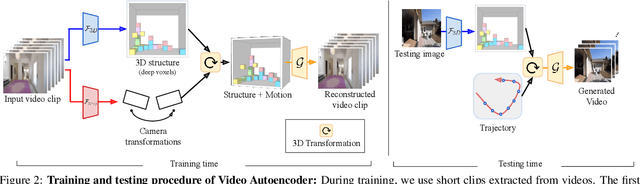
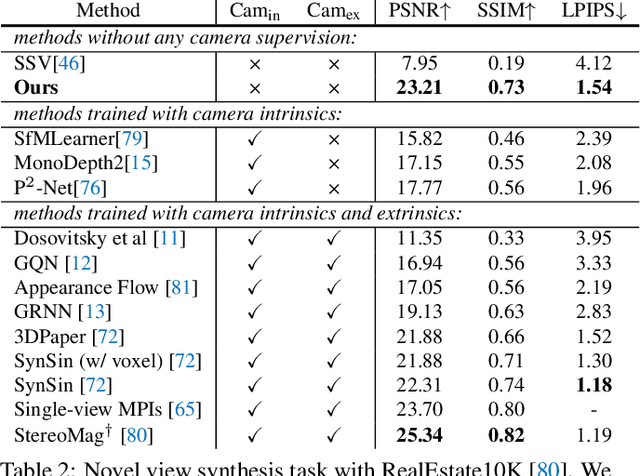
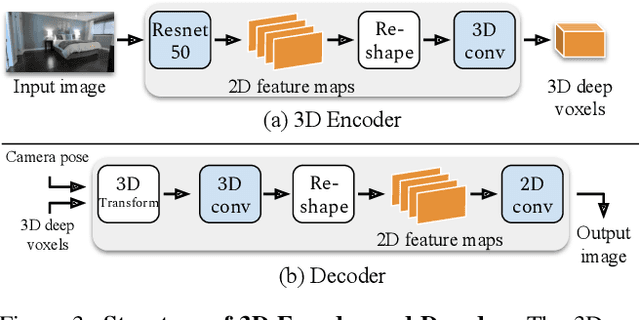
A video autoencoder is proposed for learning disentan- gled representations of 3D structure and camera pose from videos in a self-supervised manner. Relying on temporal continuity in videos, our work assumes that the 3D scene structure in nearby video frames remains static. Given a sequence of video frames as input, the video autoencoder extracts a disentangled representation of the scene includ- ing: (i) a temporally-consistent deep voxel feature to represent the 3D structure and (ii) a 3D trajectory of camera pose for each frame. These two representations will then be re-entangled for rendering the input video frames. This video autoencoder can be trained directly using a pixel reconstruction loss, without any ground truth 3D or camera pose annotations. The disentangled representation can be applied to a range of tasks, including novel view synthesis, camera pose estimation, and video generation by motion following. We evaluate our method on several large- scale natural video datasets, and show generalization results on out-of-domain images.