 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUEEN: Query Unlearning against Model Extraction
Paper and Code
Jul 01, 2024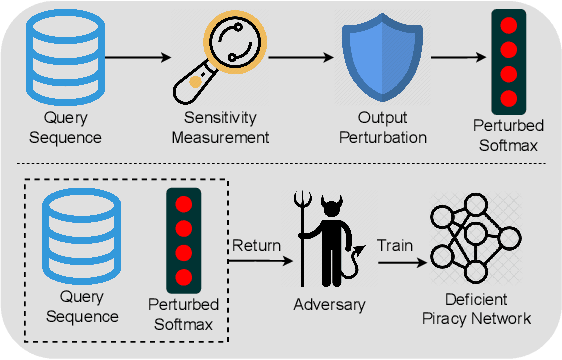
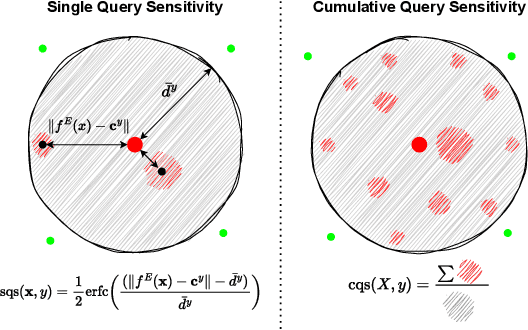
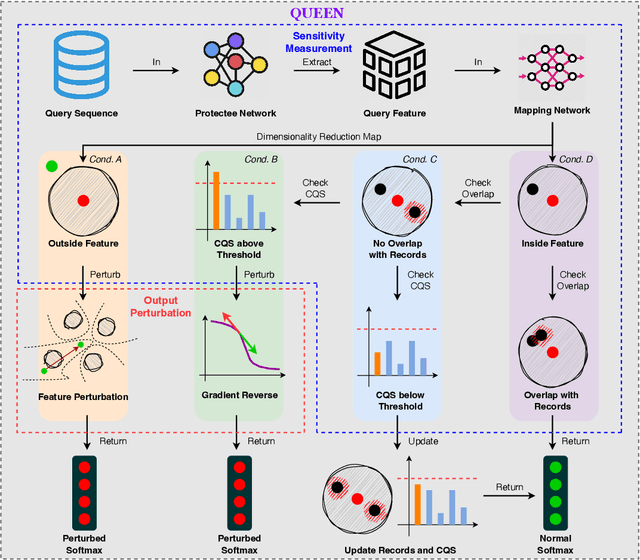

Model extraction attacks currently pose a non-negligible threat to the security and privacy of deep learning models. By querying the model with a small dataset and usingthe query results as the ground-truth labels, an adversary can steal a piracy model with performance comparable to the original model. Two key issues that cause the threat are, on the one hand, accurate and unlimited queries can be obtained by the adversary; on the other hand, the adversary can aggregate the query results to train the model step by step. The existing defenses usually employ model watermarking or fingerprinting to protect the ownership. However, these methods cannot proactively prevent the violation from happening. To mitigate the threat, we propose QUEEN (QUEry unlEarNing) that proactively launches counterattacks on potential model extraction attacks from the very beginning. To limit the potential threat, QUEEN has sensitivity measurement and outputs perturbation that prevents the adversary from training a piracy model with high performance. In sensitivity measurement, QUEEN measures the single query sensitivity by its distance from the center of its cluster in the feature space. To reduce the learning accuracy of attacks, for the highly sensitive query batch, QUEEN applies query unlearning, which is implemented by gradient reverse to perturb the softmax output such that the piracy model will generate reverse gradients to worsen its performance unconsciously. Experiments show that QUEEN outperforms the state-of-the-art defenses against various model extraction attacks with a relatively low cost to the model accuracy. The artifact is publicly available at https://anonymous.4open.science/r/queen implementation-5408/.