 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVertical Federated Unlearning via Backdoor Certification
Dec 16, 2024Vertical Federated Learning (VFL) offers a novel paradigm in machine learning, enabling distinct entities to train models cooperatively while maintaining data privacy. This method is particularly pertinent when entities possess datasets with identical sample identifiers but diverse attributes. Recent privacy regulations emphasize an individual's \emph{right to be forgotten}, which necessitates the ability for models to unlearn specific training data. The primary challenge is to develop a mechanism to eliminate the influence of a specific client from a model without erasing all relevant data from other clients. Our research investigates the removal of a single client's contribution within the VFL framework. We introduce an innovative modification to traditional VFL by employing a mechanism that inverts the typical learning trajectory with the objective of extracting specific data contributions. This approach seeks to optimize model performance using gradient ascent, guided by a pre-defined constrained model. We also introduce a backdoor mechanism to verify the effectiveness of the unlearning procedure. Our method avoids fully accessing the initial training data and avoids storing parameter updates. Empirical evidence shows that the results align closely with those achieved by retraining from scratch. Utilizing gradient ascent, our unlearning approach addresses key challenges in VFL, laying the groundwork for future advancements in this domain. All the code and implementations related to this paper are publicly available at https://github.com/mengde-han/VFL-unlearn.
Momentum Gradient Descent Federated Learning with Local Differential Privacy
Sep 28, 2022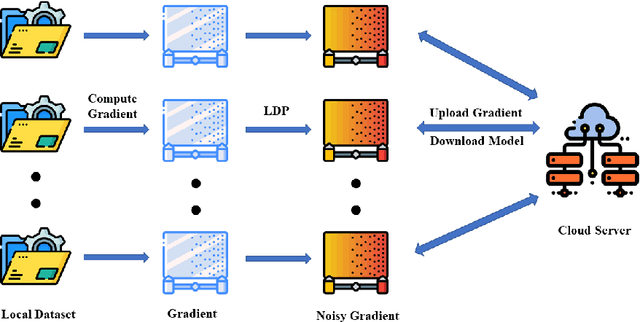
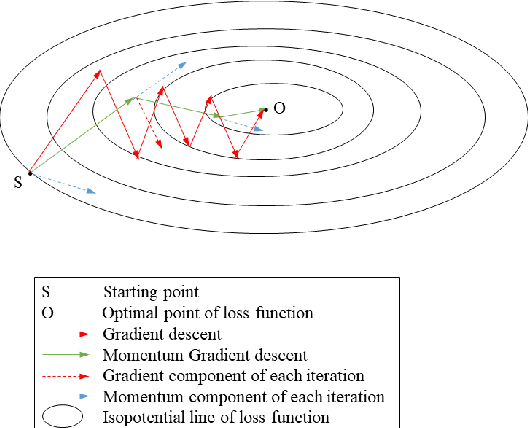
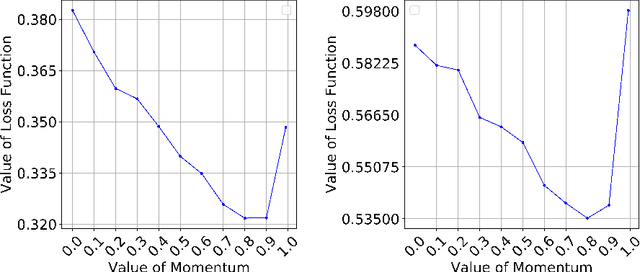
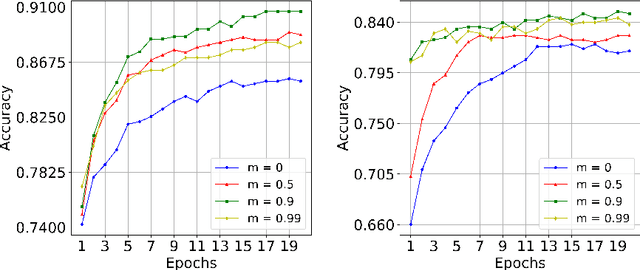
Nowadays, the development of information technology is growing rapidly. In the big data era, the privacy of personal information has been more pronounced. The major challenge is to find a way to guarantee that sensitive personal information is not disclosed while data is published and analyzed. Centralized differential privacy is established on the assumption of a trusted third-party data curator. However, this assumption is not always true in reality. As a new privacy preservation model, local differential privacy has relatively strong privacy guarantees. Although federated learning has relatively been a privacy-preserving approach for distributed learning, it still introduces various privacy concerns. To avoid privacy threats and reduce communication costs, in this article, we propose integrating federated learning and local differential privacy with momentum gradient descent to improve the performance of machine learning models.
Fairness in Semi-supervised Learning: Unlabeled Data Help to Reduce Discrimination
Sep 25, 2020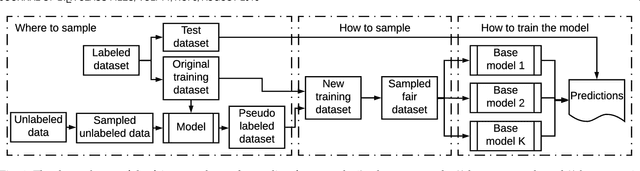
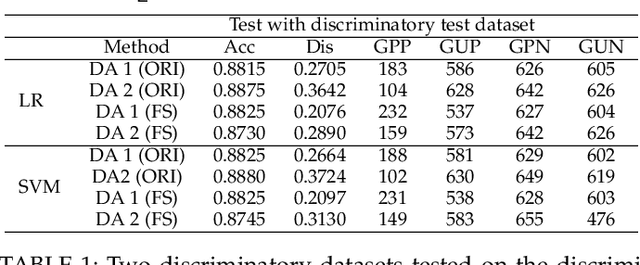
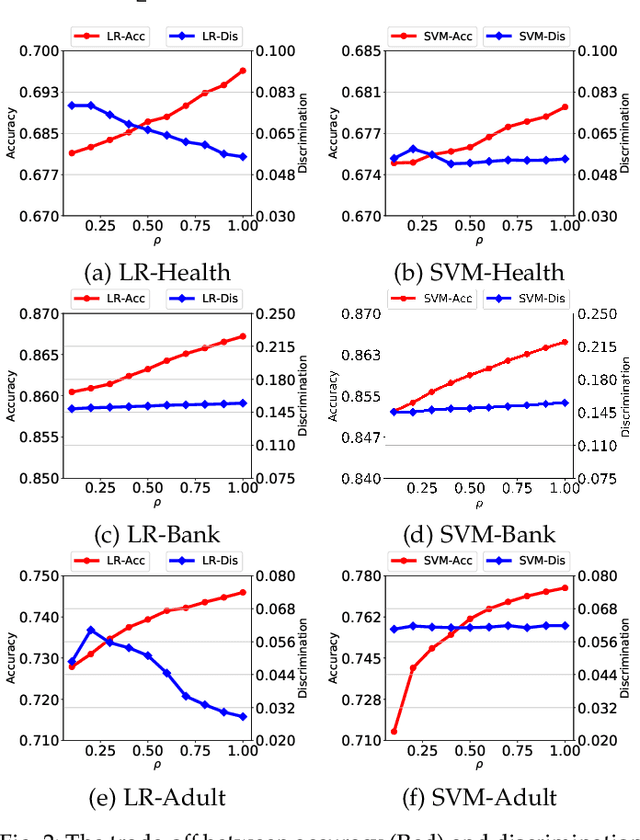
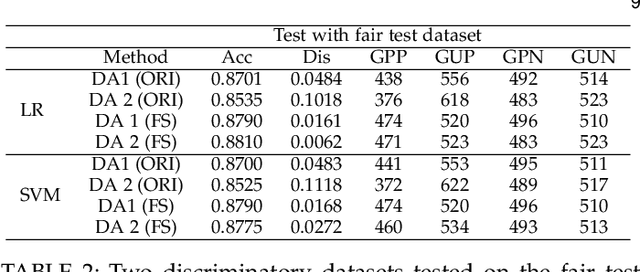
A growing specter in the rise of machine learning is whether the decisions made by machine learning models are fair. While research is already underway to formalize a machine-learning concept of fairness and to design frameworks for building fair models with sacrifice in accuracy, most are geared toward either supervised or unsupervised learning. Yet two observations inspired us to wonder whether semi-supervised learning might be useful to solve discrimination problems. First, previous study showed that increasing the size of the training set may lead to a better trade-off between fairness and accuracy. Second, the most powerful models today require an enormous of data to train which, in practical terms, is likely possible from a combination of labeled and unlabeled data. Hence, in this paper, we present a framework of fair semi-supervised learning in the pre-processing phase, including pseudo labeling to predict labels for unlabeled data, a re-sampling method to obtain multiple fair datasets and lastly, ensemble learning to improve accuracy and decrease discrimination. A theoretical decomposition analysis of bias, variance and noise highlights the different sources of discrimination and the impact they have on fairness in semi-supervised learning. A set of experiments on real-world and synthetic datasets show that our method is able to use unlabeled data to achieve a better trade-off between accuracy and discrimination.
Fairness Constraints in Semi-supervised Learning
Sep 14, 2020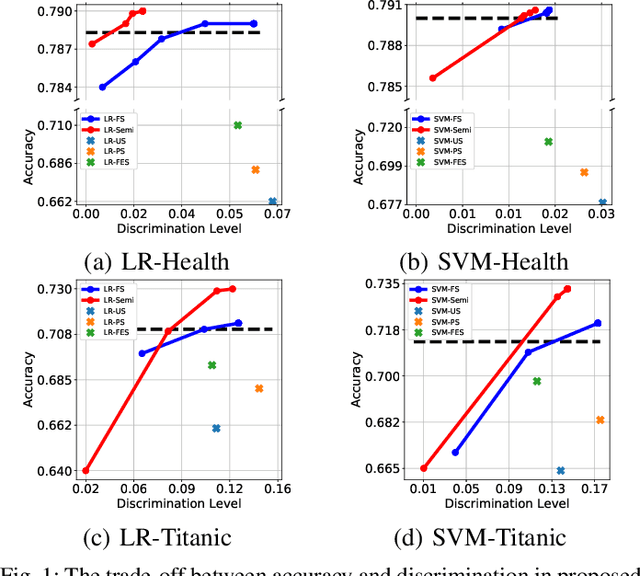

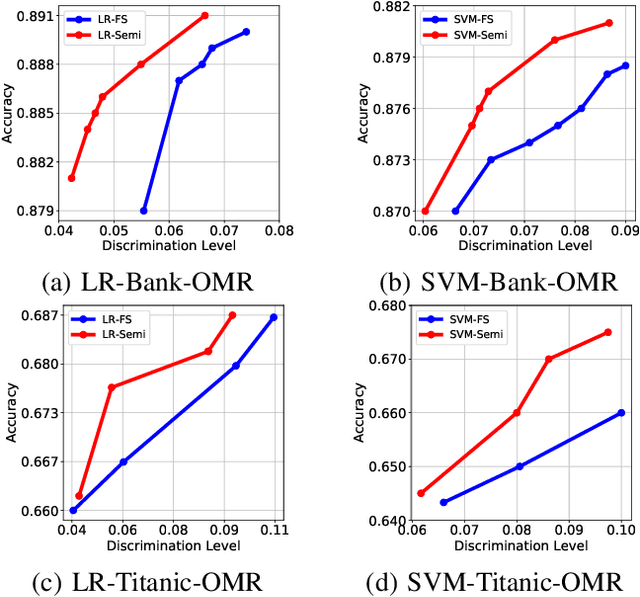
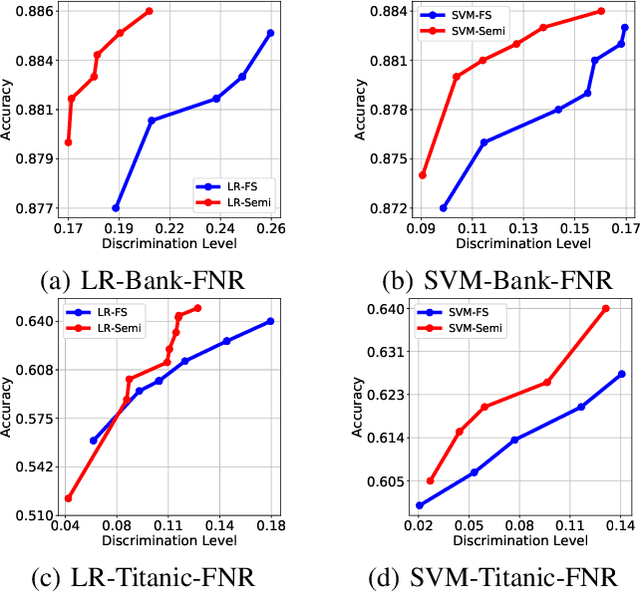
Fairness in machine learning has received considerable attention. However, most studies on fair learning focus on either supervised learning or unsupervised learning. Very few consider semi-supervised settings. Yet, in reality, most machine learning tasks rely on large datasets that contain both labeled and unlabeled data. One of key issues with fair learning is the balance between fairness and accuracy. Previous studies arguing that increasing the size of the training set can have a better trade-off. We believe that increasing the training set with unlabeled data may achieve the similar result. Hence, we develop a framework for fair semi-supervised learning, which is formulated as an optimization problem. This includes classifier loss to optimize accuracy, label propagation loss to optimize unlabled data prediction, and fairness constraints over labeled and unlabeled data to optimize the fairness level. The framework is conducted in logistic regression and support vector machines under the fairness metrics of disparate impact and disparate mistreatment. We theoretically analyze the source of discrimination in semi-supervised learning via bias, variance and noise decomposition. Extensive experiments show that our method is able to achieve fair semi-supervised learning, and reach a better trade-off between accuracy and fairness than fair supervised learning.