 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness Constraints in Semi-supervised Learning
Paper and Code
Sep 14, 2020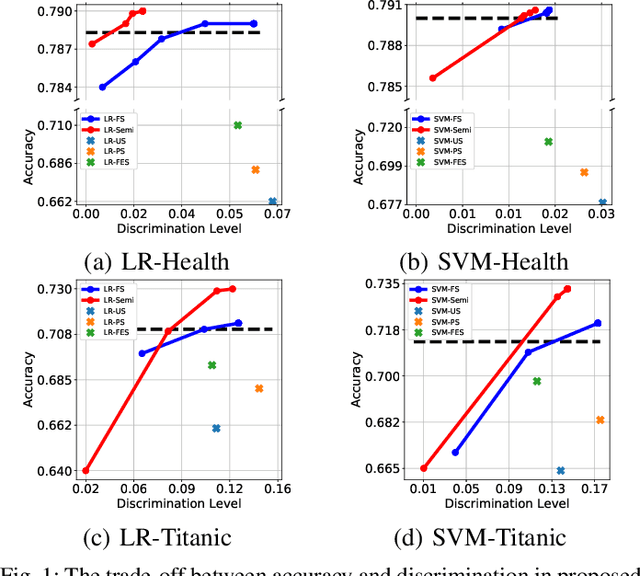

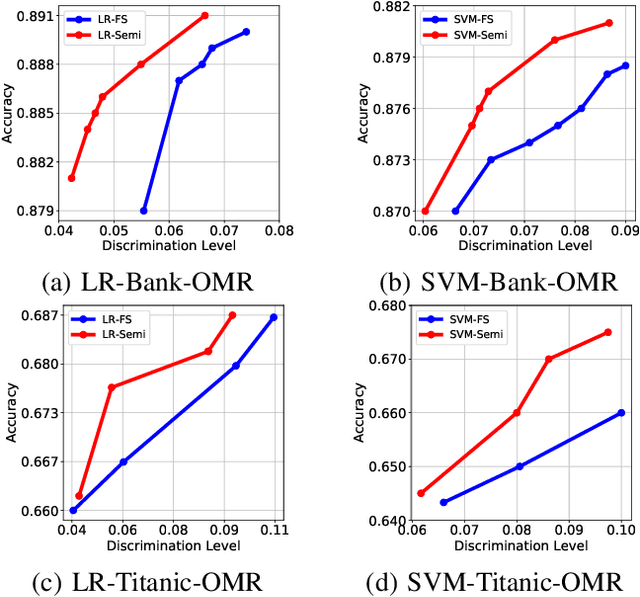
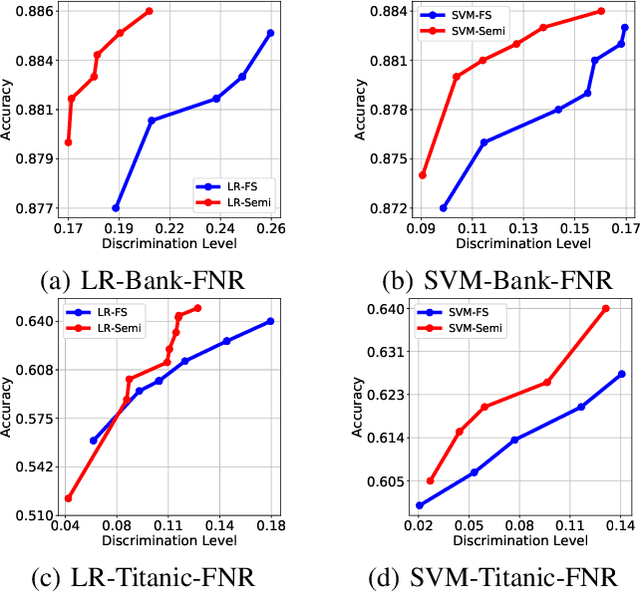
Fairness in machine learning has received considerable attention. However, most studies on fair learning focus on either supervised learning or unsupervised learning. Very few consider semi-supervised settings. Yet, in reality, most machine learning tasks rely on large datasets that contain both labeled and unlabeled data. One of key issues with fair learning is the balance between fairness and accuracy. Previous studies arguing that increasing the size of the training set can have a better trade-off. We believe that increasing the training set with unlabeled data may achieve the similar result. Hence, we develop a framework for fair semi-supervised learning, which is formulated as an optimization problem. This includes classifier loss to optimize accuracy, label propagation loss to optimize unlabled data prediction, and fairness constraints over labeled and unlabeled data to optimize the fairness level. The framework is conducted in logistic regression and support vector machines under the fairness metrics of disparate impact and disparate mistreatment. We theoretically analyze the source of discrimination in semi-supervised learning via bias, variance and noise decomposition. Extensive experiments show that our method is able to achieve fair semi-supervised learning, and reach a better trade-off between accuracy and fairness than fair supervised learning.