 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelated Differential Privacy: Feature Selection in Machine Learning
Paper and Code
Oct 07, 2020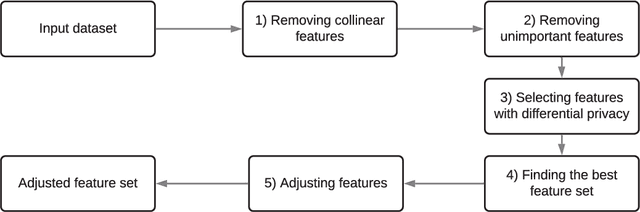
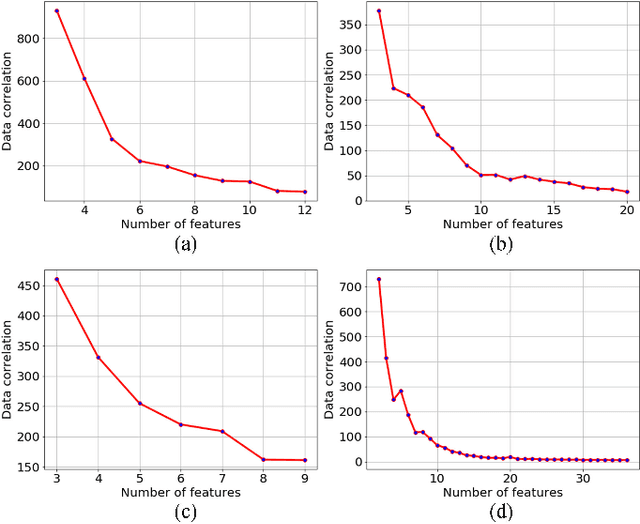
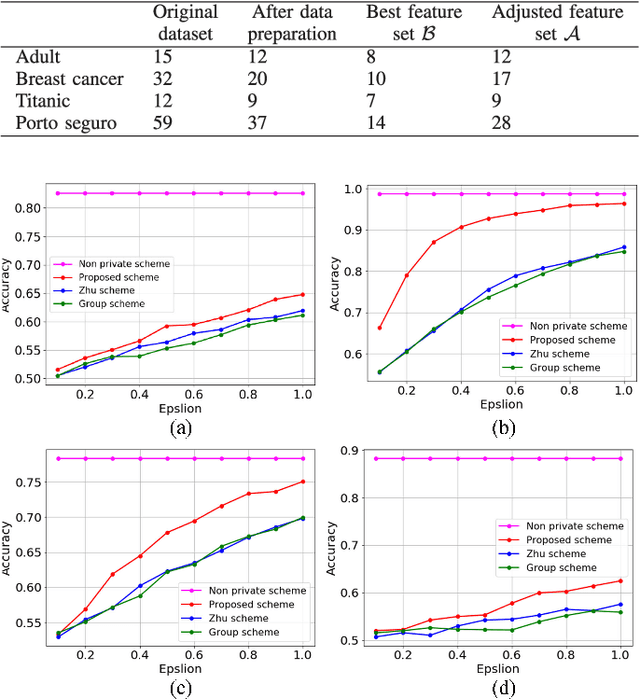
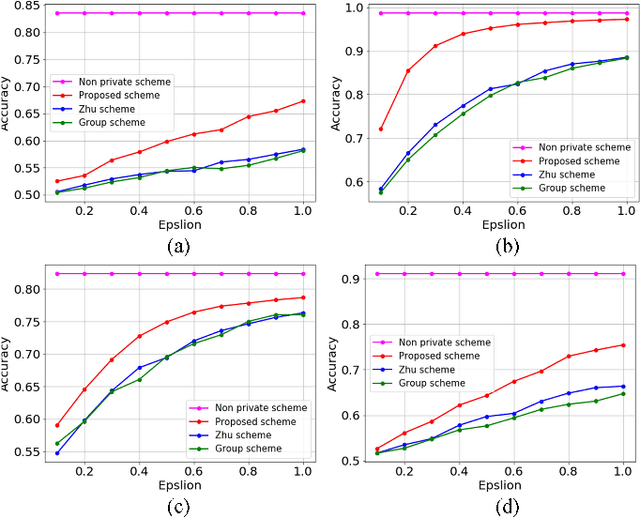
Privacy preserving in machine learning is a crucial issue in industry informatics since data used for training in industries usually contain sensitive information. Existing differentially private machine learning algorithms have not considered the impact of data correlation, which may lead to more privacy leakage than expected in industrial applications. For example, data collected for traffic monitoring may contain some correlated records due to temporal correlation or user correlation. To fill this gap, we propose a correlation reduction scheme with differentially private feature selection considering the issue of privacy loss when data have correlation in machine learning tasks. %The key to the proposed scheme is to describe the data correlation and select features which leads to less data correlation across the whole dataset. The proposed scheme involves five steps with the goal of managing the extent of data correlation, preserving the privacy, and supporting accuracy in the prediction results. In this way, the impact of data correlation is relieved with the proposed feature selection scheme, and moreover, the privacy issue of data correlation in learning is guaranteed. The proposed method can be widely used in machine learning algorithms which provide services in industrial areas. Experiments show that the proposed scheme can produce better prediction results with machine learning tasks and fewer mean square errors for data queries compared to existing schemes.