 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn exploration of algorithmic discrimination in data and classification
Nov 06, 2018
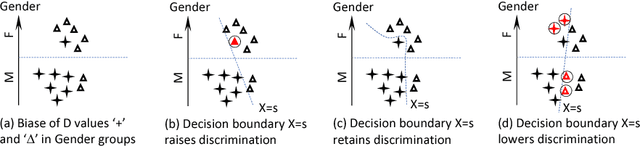

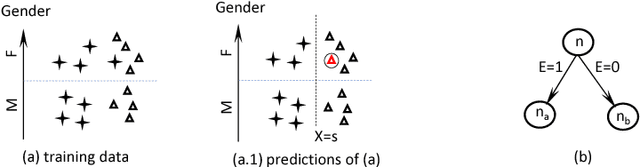
Algorithmic discrimination is an important aspect when data is used for predictive purposes. This paper analyzes the relationships between discrimination and classification, data set partitioning, and decision models, as well as correlation. The paper uses real world data sets to demonstrate the existence of discrimination and the independence between the discrimination of data sets and the discrimination of classification models.
FairMod - Making Predictive Models Discrimination Aware
Nov 05, 2018


Predictive models such as decision trees and neural networks may produce discrimination in their predictions. This paper proposes a method to post-process the predictions of a predictive model to make the processed predictions non-discriminatory. The method considers multiple protected variables together. Multiple protected variables make the problem more challenging than a simple protected variable. The method uses a well-cited discrimination metric and adapts it to allow the specification of explanatory variables, such as position, profession, education, that describe the contexts of the applications. It models the post-processing of predictions problem as a nonlinear optimization problem to find best adjustments to the predictions so that the discrimination constraints of all protected variables are all met at the same time. The proposed method is independent of classification methods. It can handle the cases that existing methods cannot handle: satisfying multiple protected attributes at the same time, allowing multiple explanatory attributes, and being independent of classification model types. An evaluation using four real world data sets shows that the proposed method is as effectively as existing methods, in addition to its extra power.