 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Combinatorial Bandits: Balancing Competitivity and Complementarity
Jul 07, 2022

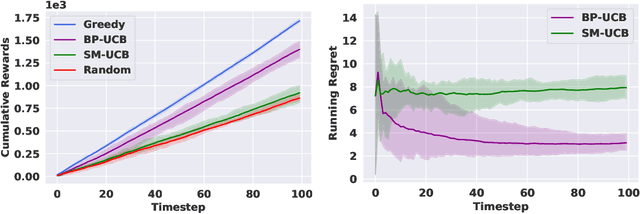

We study non-modular function maximization in the online interactive bandit setting. We are motivated by applications where there is a natural complementarity between certain elements: e.g., in a movie recommendation system, watching the first movie in a series complements the experience of watching a second (and a third, etc.). This is not expressible using only submodular functions which can represent only competitiveness between elements. We extend the purely submodular approach in two ways. First, we assume that the objective can be decomposed into the sum of monotone suBmodular and suPermodular function, known as a BP objective. Here, complementarity is naturally modeled by the supermodular component. We develop a UCB-style algorithm, where at each round a noisy gain is revealed after an action is taken that balances refining beliefs about the unknown objectives (exploration) and choosing actions that appear promising (exploitation). Defining regret in terms of submodular and supermodular curvature with respect to a full-knowledge greedy baseline, we show that this algorithm achieves at most $O(\sqrt{T})$ regret after $T$ rounds of play. Second, for those functions that do not admit a BP structure, we provide analogous regret guarantees in terms of their submodularity ratio; this is applicable for functions that are almost, but not quite, submodular. We numerically study the tasks of movie recommendation on the MovieLens dataset, and selection of training subsets for classification. Through these examples, we demonstrate the algorithm's performance as well as the shortcomings of viewing these problems as being solely submodular.