 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Mixup Training: Improved Calibration and Predictive Uncertainty for Deep Neural Networks
Paper and Code
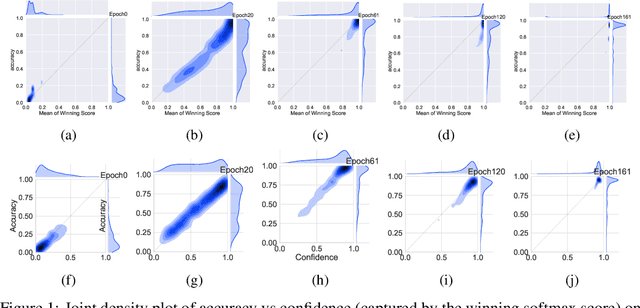
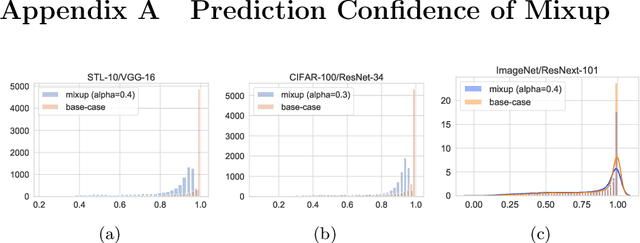
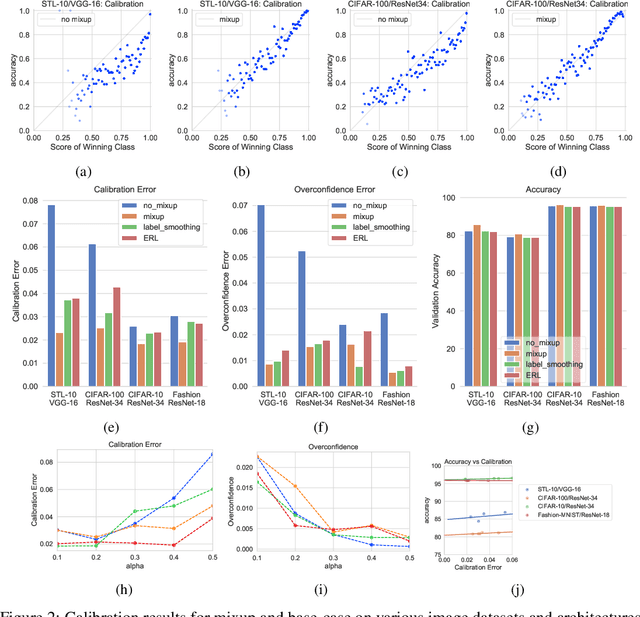
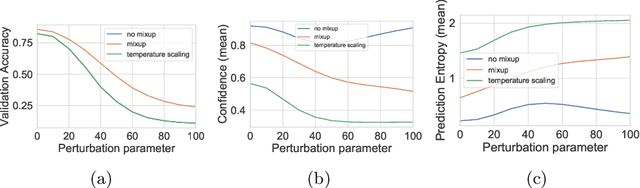
Mixup~\cite{zhang2017mixup} is a recently proposed method for training deep neural networks where additional samples are generated during training by convexly combining random pairs of images and their associated labels. While simple to implement, it has shown to be a surprisingly effective method of data augmentation for image classification; DNNs trained with mixup show noticeable gains in classification performance on a number of image classification benchmarks. In this work, we discuss a hitherto untouched aspect of mixup training -- the calibration and predictive uncertainty of models trained with mixup. We find that DNNs trained with mixup are significantly better calibrated -- i.e., the predicted softmax scores are much better indicators of the actual likelihood of a correct prediction -- than DNNs trained in the regular fashion. We conduct experiments on a number of image classification architectures and datasets -- including large-scale datasets like ImageNet -- and find this to be the case. Additionally, we find that merely mixing features does not result in the same calibration benefit and that the label smoothing in mixup training plays a significant role in improving calibration. Finally, we also observe that mixup-trained DNNs are less prone to over-confident predictions on out-of-distribution and random-noise data. We conclude that the typical overconfidence seen in neural networks, even on in-distribution data is likely a consequence of training with hard labels, suggesting that mixup training be employed for classification tasks where predictive uncertainty is a significant concern.