 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Phase Matter For Monaural Source Separation?
Nov 02, 2017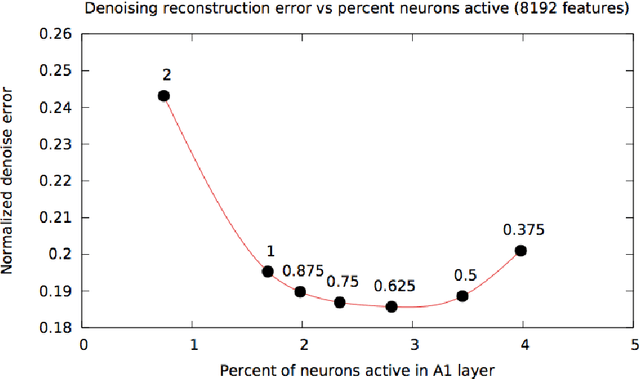


The "cocktail party" problem of fully separating multiple sources from a single channel audio waveform remains unsolved. Current biological understanding of neural encoding suggests that phase information is preserved and utilized at every stage of the auditory pathway. However, current computational approaches primarily discard phase information in order to mask amplitude spectrograms of sound. In this paper, we seek to address whether preserving phase information in spectral representations of sound provides better results in monaural separation of vocals from a musical track by using a neurally plausible sparse generative model. Our results demonstrate that preserving phase information reduces artifacts in the separated tracks, as quantified by the signal to artifact ratio (GSAR). Furthermore, our proposed method achieves state-of-the-art performance for source separation, as quantified by a mean signal to interference ratio (GSIR) of 19.46.