 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Cognitive Attributes in Financial Decision-Making
Apr 11, 2025Cognitive attributes are fundamental to metacognition, shaping how individuals process information, evaluate choices, and make decisions. To develop metacognitive artificial intelligence (AI) models that reflect human reasoning, it is essential to account for the attributes that influence reasoning patterns and decision-maker behavior, often leading to different or even conflicting choices. This makes it crucial to incorporate cognitive attributes in designing AI models that align with human decision-making processes, especially in high-stakes domains such as finance, where decisions have significant real-world consequences. However, existing AI alignment research has primarily focused on value alignment, often overlooking the role of individual cognitive attributes that distinguish decision-makers. To address this issue, this paper (1) analyzes the literature on cognitive attributes, (2) establishes five criteria for defining them, and (3) categorizes 19 domain-specific cognitive attributes relevant to financial decision-making. These three components provide a strong basis for developing AI systems that accurately reflect and align with human decision-making processes in financial contexts.
The Impact of an XAI-Augmented Approach on Binary Classification with Scarce Data
Jul 01, 2024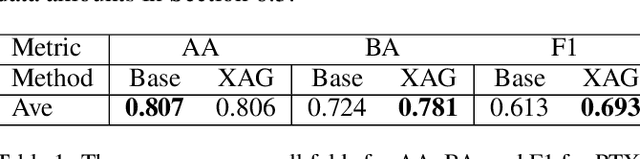
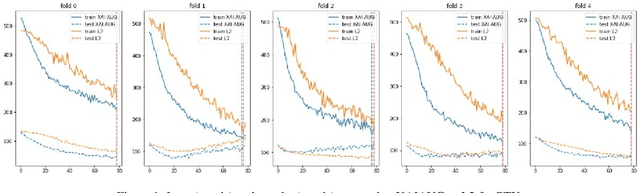

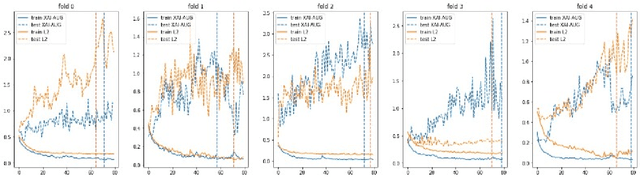
Point-of-Care Ultrasound (POCUS) is the practice of clinicians conducting and interpreting ultrasound scans right at the patient's bedside. However, the expertise needed to interpret these images is considerable and may not always be present in emergency situations. This reality makes algorithms such as machine learning classifiers extremely valuable to augment human decisions. POCUS devices are becoming available at a reasonable cost in the size of a mobile phone. The challenge of turning POCUS devices into life-saving tools is that interpretation of ultrasound images requires specialist training and experience. Unfortunately, the difficulty to obtain positive training images represents an important obstacle to building efficient and accurate classifiers. Hence, the problem we try to investigate is how to explore strategies to increase accuracy of classifiers trained with scarce data. We hypothesize that training with a few data instances may not suffice for classifiers to generalize causing them to overfit. Our approach uses an Explainable AI-Augmented approach to help the algorithm learn more from less and potentially help the classifier better generalize.
Interpretable Models for Detecting and Monitoring Elevated Intracranial Pressure
Mar 04, 2024


Detecting elevated intracranial pressure (ICP) is crucial in diagnosing and managing various neurological conditions. These fluctuations in pressure are transmitted to the optic nerve sheath (ONS), resulting in changes to its diameter, which can then be detected using ultrasound imaging devices. However, interpreting sonographic images of the ONS can be challenging. In this work, we propose two systems that actively monitor the ONS diameter throughout an ultrasound video and make a final prediction as to whether ICP is elevated. To construct our systems, we leverage subject matter expert (SME) guidance, structuring our processing pipeline according to their collection procedure, while also prioritizing interpretability and computational efficiency. We conduct a number of experiments, demonstrating that our proposed systems are able to outperform various baselines. One of our SMEs then manually validates our top system's performance, lending further credibility to our approach while demonstrating its potential utility in a clinical setting.
MobilePTX: Sparse Coding for Pneumothorax Detection Given Limited Training Examples
Dec 08, 2022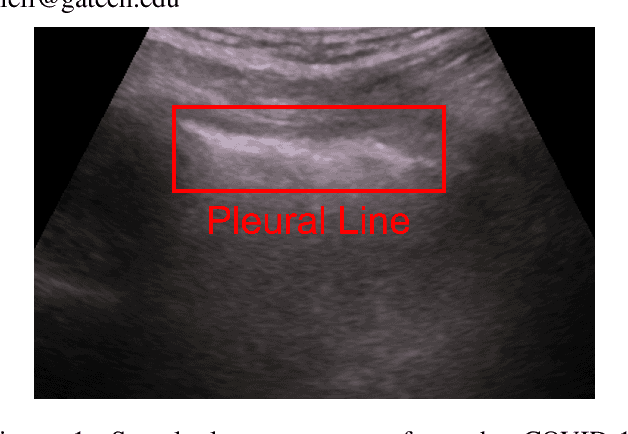
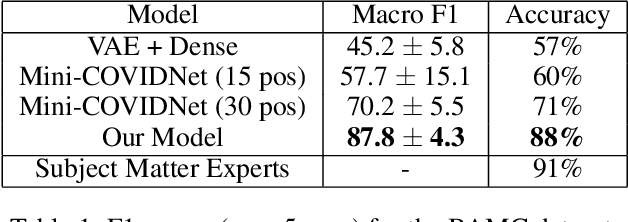
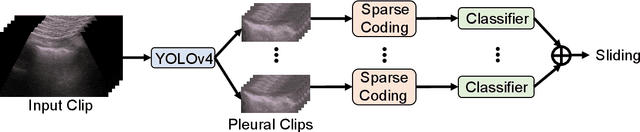

Point-of-Care Ultrasound (POCUS) refers to clinician-performed and interpreted ultrasonography at the patient's bedside. Interpreting these images requires a high level of expertise, which may not be available during emergencies. In this paper, we support POCUS by developing classifiers that can aid medical professionals by diagnosing whether or not a patient has pneumothorax. We decomposed the task into multiple steps, using YOLOv4 to extract relevant regions of the video and a 3D sparse coding model to represent video features. Given the difficulty in acquiring positive training videos, we trained a small-data classifier with a maximum of 15 positive and 32 negative examples. To counteract this limitation, we leveraged subject matter expert (SME) knowledge to limit the hypothesis space, thus reducing the cost of data collection. We present results using two lung ultrasound datasets and demonstrate that our model is capable of achieving performance on par with SMEs in pneumothorax identification. We then developed an iOS application that runs our full system in less than 4 seconds on an iPad Pro, and less than 8 seconds on an iPhone 13 Pro, labeling key regions in the lung sonogram to provide interpretable diagnoses.
Explanation Container in Case-Based Biomedical Question-Answering
Dec 22, 2021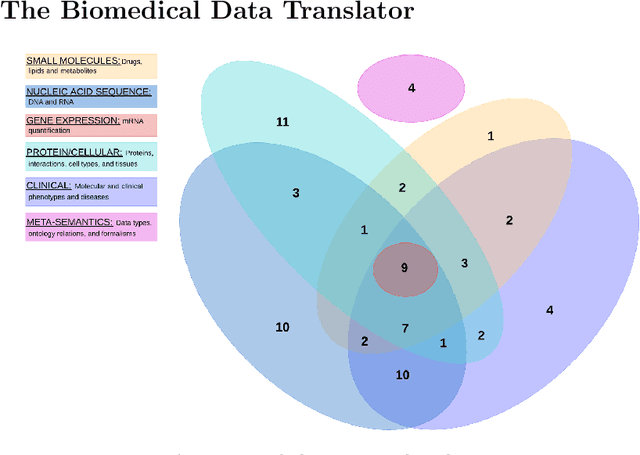
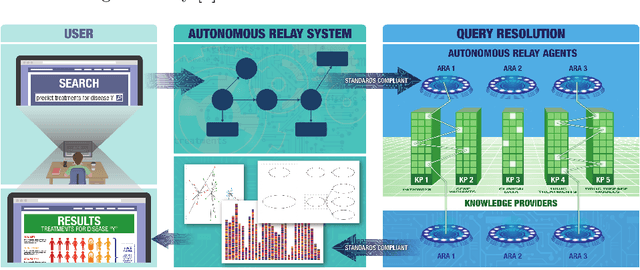
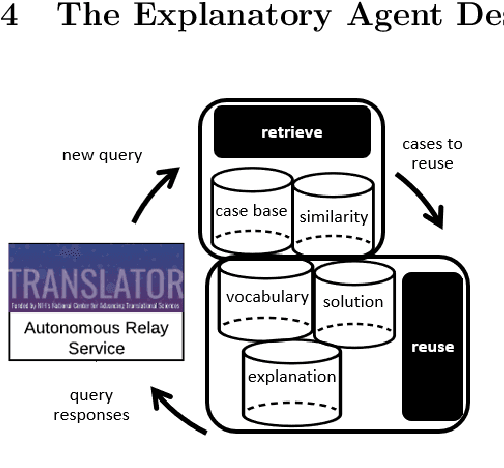
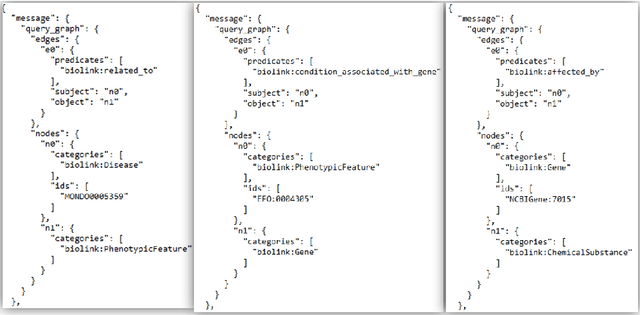
The National Center for Advancing Translational Sciences(NCATS) Biomedical Data Translator (Translator) aims to attenuate problems faced by translational scientists. Translator is a multi-agent architecture consisting of six autonomous relay agents (ARAs) and eight knowledge providers (KPs). In this paper, we present the design of the Explanatory Agent (xARA), a case-based ARA that answers biomedical queries by accessing multiple KPs, ranking results, and explaining the ranking of results. The Explanatory Agent is designed with five knowledge containers that include the four original knowledge containers and one additional container for explanation - the Explanation Container. The Explanation Container is case-based and designed with its own knowledge containers.
Longitudinal Distance: Towards Accountable Instance Attribution
Aug 23, 2021

Previous research in interpretable machine learning (IML) and explainable artificial intelligence (XAI) can be broadly categorized as either focusing on seeking interpretability in the agent's model (i.e., IML) or focusing on the context of the user in addition to the model (i.e., XAI). The former can be categorized as feature or instance attribution. Example- or sample-based methods such as those using or inspired by case-based reasoning (CBR) rely on various approaches to select instances that are not necessarily attributing instances responsible for an agent's decision. Furthermore, existing approaches have focused on interpretability and explainability but fall short when it comes to accountability. Inspired in case-based reasoning principles, this paper introduces a pseudo-metric we call Longitudinal distance and its use to attribute instances to a neural network agent's decision that can be potentially used to build accountable CBR agents.
Data Representing Ground-Truth Explanations to Evaluate XAI Methods
Nov 18, 2020
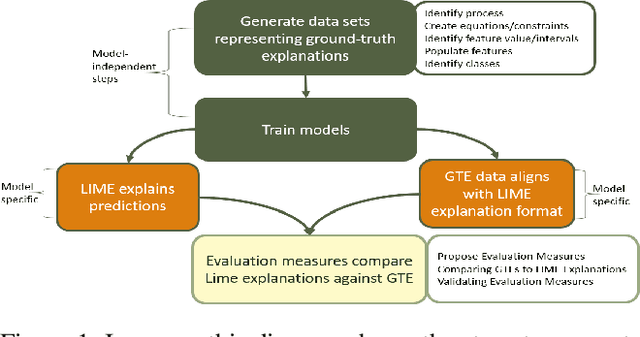
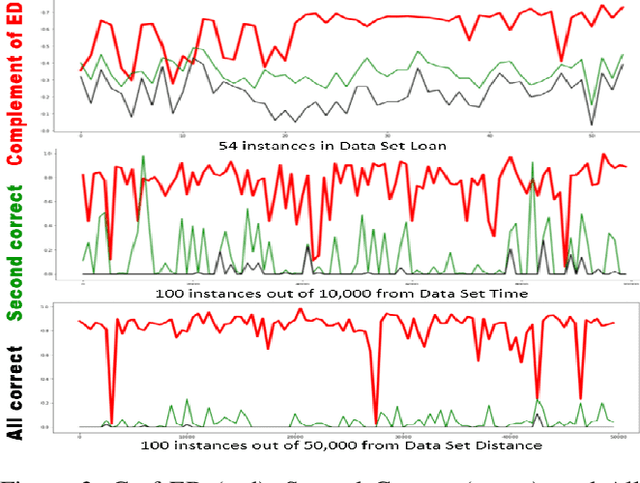

Explainable artificial intelligence (XAI) methods are currently evaluated with approaches mostly originated in interpretable machine learning (IML) research that focus on understanding models such as comparison against existing attribution approaches, sensitivity analyses, gold set of features, axioms, or through demonstration of images. There are problems with these methods such as that they do not indicate where current XAI approaches fail to guide investigations towards consistent progress of the field. They do not measure accuracy in support of accountable decisions, and it is practically impossible to determine whether one XAI method is better than the other or what the weaknesses of existing models are, leaving researchers without guidance on which research questions will advance the field. Other fields usually utilize ground-truth data and create benchmarks. Data representing ground-truth explanations is not typically used in XAI or IML. One reason is that explanations are subjective, in the sense that an explanation that satisfies one user may not satisfy another. To overcome these problems, we propose to represent explanations with canonical equations that can be used to evaluate the accuracy of XAI methods. The contributions of this paper include a methodology to create synthetic data representing ground-truth explanations, three data sets, an evaluation of LIME using these data sets, and a preliminary analysis of the challenges and potential benefits in using these data to evaluate existing XAI approaches. Evaluation methods based on human-centric studies are outside the scope of this paper.
Qualitative Investigation in Explainable Artificial Intelligence: A Bit More Insight from Social Science
Nov 13, 2020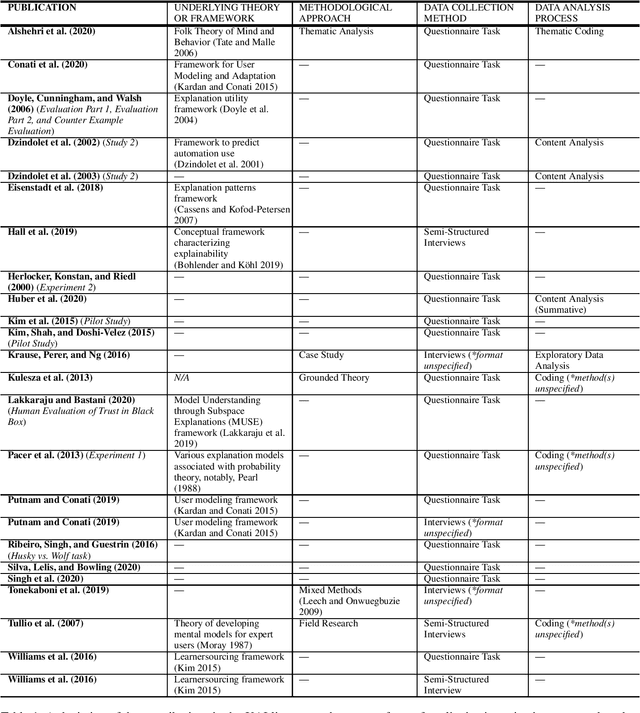
This paper presents a focused analysis of human studies in explainable artificial intelligence (XAI) entailing qualitative investigation. We draw on the social science corpora of qualitative research to illustrate opportunities for making the human studies where XAI researchers used observations, interviews, focus groups, and/or questionnaires to capture qualitative data more rigorous. We contextualize the presentation of the XAI contributions included in our analysis according to the components of rigor described in the qualitative research literature: 1) underlying theories or frameworks, 2) methodological approaches, 3) data collection methods, and 4) data analysis processes. The results of our analysis support calls from others in the XAI community advocating for collaboration with experts from social disciplines to bolster rigor and effectiveness in human studies.