 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Representing Ground-Truth Explanations to Evaluate XAI Methods
Nov 18, 2020
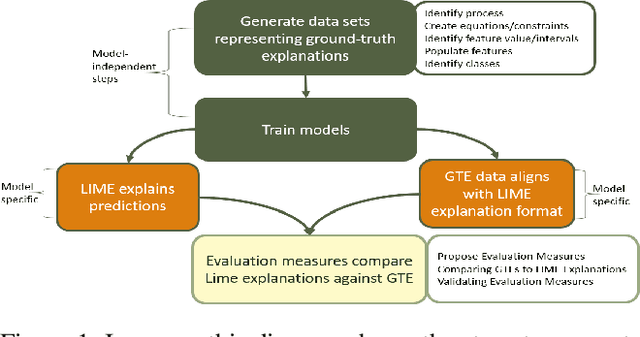
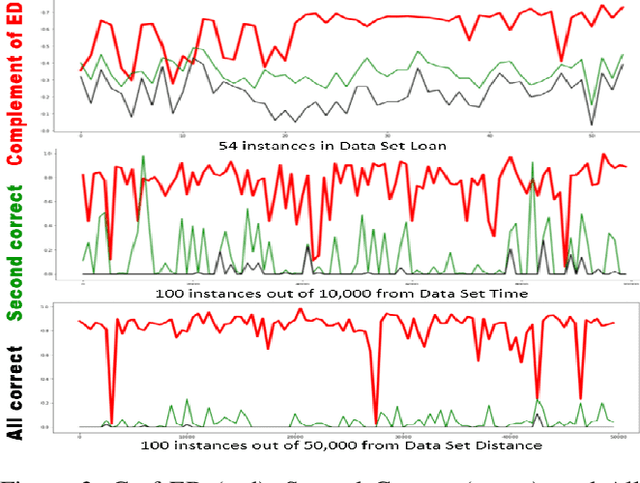

Explainable artificial intelligence (XAI) methods are currently evaluated with approaches mostly originated in interpretable machine learning (IML) research that focus on understanding models such as comparison against existing attribution approaches, sensitivity analyses, gold set of features, axioms, or through demonstration of images. There are problems with these methods such as that they do not indicate where current XAI approaches fail to guide investigations towards consistent progress of the field. They do not measure accuracy in support of accountable decisions, and it is practically impossible to determine whether one XAI method is better than the other or what the weaknesses of existing models are, leaving researchers without guidance on which research questions will advance the field. Other fields usually utilize ground-truth data and create benchmarks. Data representing ground-truth explanations is not typically used in XAI or IML. One reason is that explanations are subjective, in the sense that an explanation that satisfies one user may not satisfy another. To overcome these problems, we propose to represent explanations with canonical equations that can be used to evaluate the accuracy of XAI methods. The contributions of this paper include a methodology to create synthetic data representing ground-truth explanations, three data sets, an evaluation of LIME using these data sets, and a preliminary analysis of the challenges and potential benefits in using these data to evaluate existing XAI approaches. Evaluation methods based on human-centric studies are outside the scope of this paper.