 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Analytics for Dementia: Machine Learning on Healthcare Data
Jan 12, 2026Dementia is a complex syndrome impacting cognitive and emotional functions, with Alzheimer's disease being the most common form. This study focuses on enhancing dementia prediction using machine learning (ML) techniques on patient health data. Supervised learning algorithms are applied in this study, including K-Nearest Neighbors (KNN), Quadratic Discriminant Analysis (QDA), Linear Discriminant Analysis (LDA), and Gaussian Process Classifiers. To address class imbalance and improve model performance, techniques such as Synthetic Minority Over-sampling Technique (SMOTE) and Term Frequency-Inverse Document Frequency (TF-IDF) vectorization were employed. Among the models, LDA achieved the highest testing accuracy of 98%. This study highlights the importance of model interpretability and the correlation of dementia with features such as the presence of the APOE-epsilon4 allele and chronic conditions like diabetes. This research advocates for future ML innovations, particularly in integrating explainable AI approaches, to further improve predictive capabilities in dementia care.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
How Well Can Vison-Language Models Understand Humans' Intention? An Open-ended Theory of Mind Question Evaluation Benchmark
Mar 28, 2025Vision Language Models (VLMs) have demonstrated strong reasoning capabilities in Visual Question Answering (VQA) tasks; However, their ability to perform Theory of Mind (ToM) tasks such as accurately inferring human intentions, beliefs, and other mental states remains underexplored. In this work, we propose an open-ended question framework to comprehensively evaluate VLMs' performance across diverse categories of ToM tasks. We curated and annotated a benchmark dataset composed of 30 images. We then assessed the performance of four VLMs of varying sizes on this dataset. Our experimental results show that the GPT-4 model outperformed all others, with only one smaller model, GPT-4o-mini, achieving comparable performance. Additionally, we observed that VLMs often struggle to accurately infer intentions in complex scenarios such as bullying or cheating. Moreover, our findings also reveal that smaller models can sometimes infer correct intentions despite relying on incorrect visual cues.
The Impact of an XAI-Augmented Approach on Binary Classification with Scarce Data
Jul 01, 2024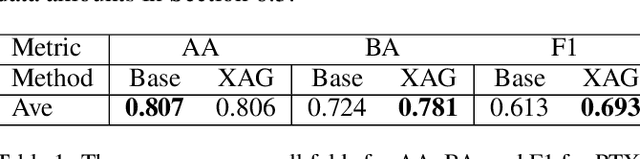
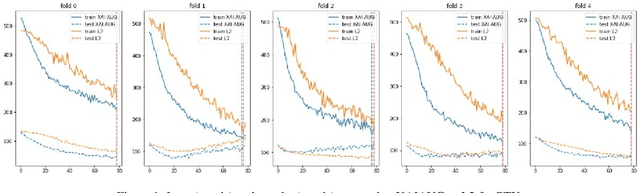

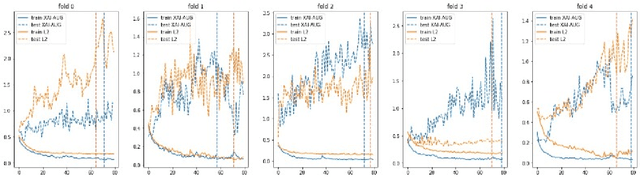
Point-of-Care Ultrasound (POCUS) is the practice of clinicians conducting and interpreting ultrasound scans right at the patient's bedside. However, the expertise needed to interpret these images is considerable and may not always be present in emergency situations. This reality makes algorithms such as machine learning classifiers extremely valuable to augment human decisions. POCUS devices are becoming available at a reasonable cost in the size of a mobile phone. The challenge of turning POCUS devices into life-saving tools is that interpretation of ultrasound images requires specialist training and experience. Unfortunately, the difficulty to obtain positive training images represents an important obstacle to building efficient and accurate classifiers. Hence, the problem we try to investigate is how to explore strategies to increase accuracy of classifiers trained with scarce data. We hypothesize that training with a few data instances may not suffice for classifiers to generalize causing them to overfit. Our approach uses an Explainable AI-Augmented approach to help the algorithm learn more from less and potentially help the classifier better generalize.