 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating drug discovery with Artificial: a whole-lab orchestration and scheduling system for self-driving labs
Apr 01, 2025Self-driving labs are transforming drug discovery by enabling automated, AI-guided experimentation, but they face challenges in orchestrating complex workflows, integrating diverse instruments and AI models, and managing data efficiently. Artificial addresses these issues with a comprehensive orchestration and scheduling system that unifies lab operations, automates workflows, and integrates AI-driven decision-making. By incorporating AI/ML models like NVIDIA BioNeMo - which facilitates molecular interaction prediction and biomolecular analysis - Artificial enhances drug discovery and accelerates data-driven research. Through real-time coordination of instruments, robots, and personnel, the platform streamlines experiments, enhances reproducibility, and advances drug discovery.
Evaluating the Performance and Robustness of LLMs in Materials Science Q&A and Property Predictions
Sep 22, 2024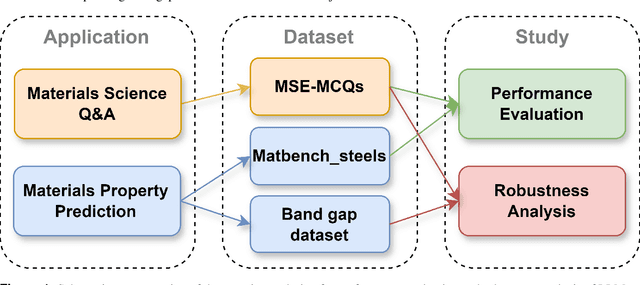

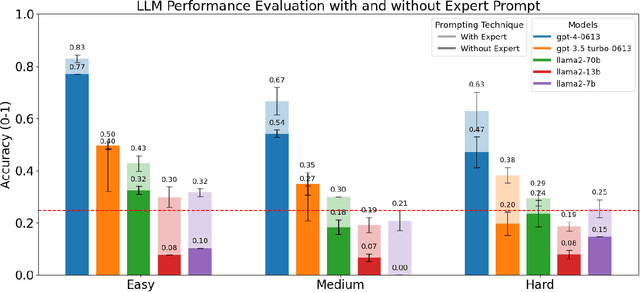
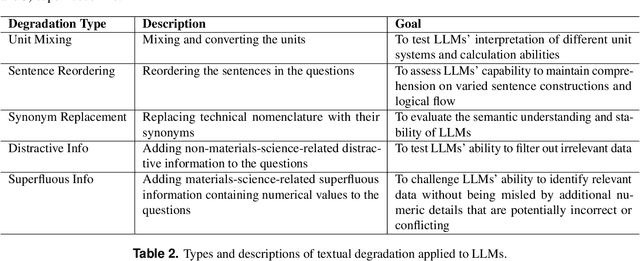
Large Language Models (LLMs) have the potential to revolutionize scientific research, yet their robustness and reliability in domain-specific applications remain insufficiently explored. This study conducts a comprehensive evaluation and robustness analysis of LLMs within the field of materials science, focusing on domain-specific question answering and materials property prediction. Three distinct datasets are used in this study: 1) a set of multiple-choice questions from undergraduate-level materials science courses, 2) a dataset including various steel compositions and yield strengths, and 3) a band gap dataset, containing textual descriptions of material crystal structures and band gap values. The performance of LLMs is assessed using various prompting strategies, including zero-shot chain-of-thought, expert prompting, and few-shot in-context learning. The robustness of these models is tested against various forms of 'noise', ranging from realistic disturbances to intentionally adversarial manipulations, to evaluate their resilience and reliability under real-world conditions. Additionally, the study uncovers unique phenomena of LLMs during predictive tasks, such as mode collapse behavior when the proximity of prompt examples is altered and performance enhancement from train/test mismatch. The findings aim to provide informed skepticism for the broad use of LLMs in materials science and to inspire advancements that enhance their robustness and reliability for practical applications.