 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding informative materials datasets beyond targeted objectives
May 06, 2026Materials science data collection can be expensive, making the reuse and long-term utility of datasets critical important for future discovery campaigns. In practice, researchers prioritize a subset of properties due to research interests. However, ignoring a subset of outcomes in data collection campaigns potentially generate datasets poorly suited for future learning tasks. Here, we present a framework for dataset construction that maximizes informativeness for target properties of interest while preserving performance on untargeted ones. Our approach uses diversity-aware selection to ensure broad coverage of the materials space. In noisy experimental dataset construction, we find that without our diversity-aware framework, prediction performance on untargeted properties can degrade by up to 40% relative to random sampling, whereas applying our framework yields improvements of up to 10% . For targeted properties, performance can degrade with respect to random sampling by up to 12.5% without diversity, while our framework achieves gains of up to 25%. Incorporating diversity into dataset construction not only preserves informativeness for the targeted properties, but also improves materials coverage for potential future objectives. As a result, the constructed datasets remain broadly informative across considered and unconsidered outcomes, ensuring unbiased quality entries and mitigating cold-start limitations in subsequent modeling and discovery campaigns.
Evaluating the Performance and Robustness of LLMs in Materials Science Q&A and Property Predictions
Sep 22, 2024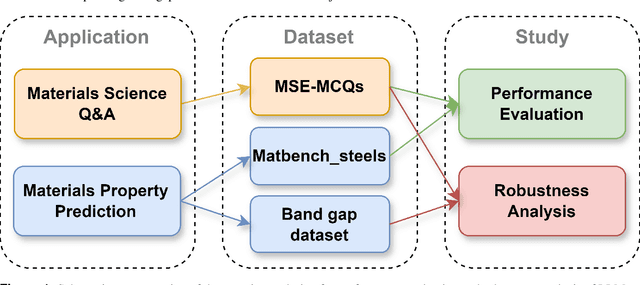

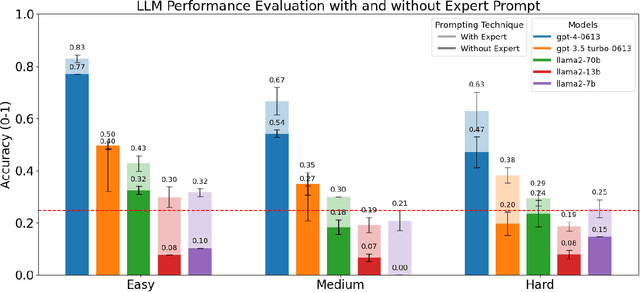
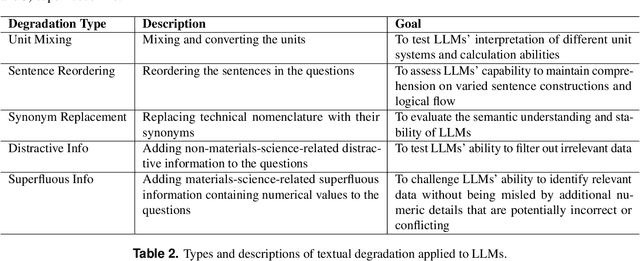
Large Language Models (LLMs) have the potential to revolutionize scientific research, yet their robustness and reliability in domain-specific applications remain insufficiently explored. This study conducts a comprehensive evaluation and robustness analysis of LLMs within the field of materials science, focusing on domain-specific question answering and materials property prediction. Three distinct datasets are used in this study: 1) a set of multiple-choice questions from undergraduate-level materials science courses, 2) a dataset including various steel compositions and yield strengths, and 3) a band gap dataset, containing textual descriptions of material crystal structures and band gap values. The performance of LLMs is assessed using various prompting strategies, including zero-shot chain-of-thought, expert prompting, and few-shot in-context learning. The robustness of these models is tested against various forms of 'noise', ranging from realistic disturbances to intentionally adversarial manipulations, to evaluate their resilience and reliability under real-world conditions. Additionally, the study uncovers unique phenomena of LLMs during predictive tasks, such as mode collapse behavior when the proximity of prompt examples is altered and performance enhancement from train/test mismatch. The findings aim to provide informed skepticism for the broad use of LLMs in materials science and to inspire advancements that enhance their robustness and reliability for practical applications.
GraspARL: Dynamic Grasping via Adversarial Reinforcement Learning
Mar 14, 2022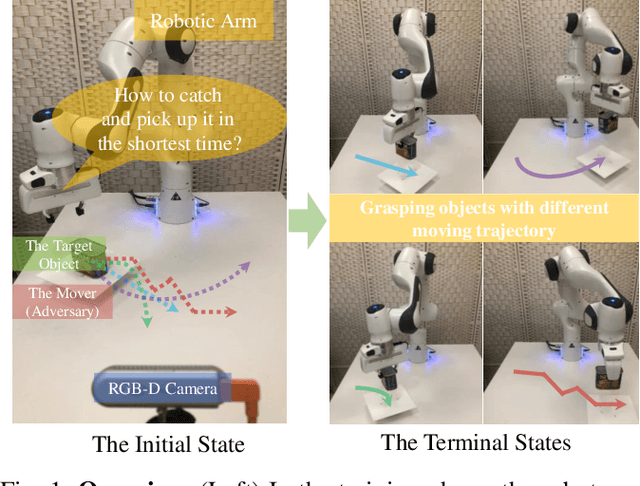
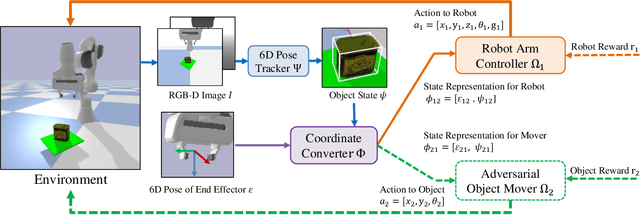
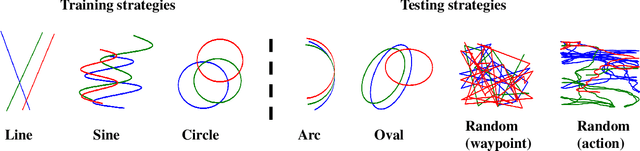

Grasping moving objects, such as goods on a belt or living animals, is an important but challenging task in robotics. Conventional approaches rely on a set of manually defined object motion patterns for training, resulting in poor generalization to unseen object trajectories. In this work, we introduce an adversarial reinforcement learning framework for dynamic grasping, namely GraspARL. To be specific. we formulate the dynamic grasping problem as a 'move-and-grasp' game, where the robot is to pick up the object on the mover and the adversarial mover is to find a path to escape it. Hence, the two agents play a min-max game and are trained by reinforcement learning. In this way, the mover can auto-generate diverse moving trajectories while training. And the robot trained with the adversarial trajectories can generalize to various motion patterns. Empirical results on the simulator and real-world scenario demonstrate the effectiveness of each and good generalization of our method.