 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffFP: Learning Behaviors from Scratch via Diffusion-based Fictitious Play
Nov 17, 2025Self-play reinforcement learning has demonstrated significant success in learning complex strategic and interactive behaviors in competitive multi-agent games. However, achieving such behaviors in continuous decision spaces remains challenging. Ensuring adaptability and generalization in self-play settings is critical for achieving competitive performance in dynamic multi-agent environments. These challenges often cause methods to converge slowly or fail to converge at all to a Nash equilibrium, making agents vulnerable to strategic exploitation by unseen opponents. To address these challenges, we propose DiffFP, a fictitious play (FP) framework that estimates the best response to unseen opponents while learning a robust and multimodal behavioral policy. Specifically, we approximate the best response using a diffusion policy that leverages generative modeling to learn adaptive and diverse strategies. Through empirical evaluation, we demonstrate that the proposed FP framework converges towards $ε$-Nash equilibria in continuous- space zero-sum games. We validate our method on complex multi-agent environments, including racing and multi-particle zero-sum games. Simulation results show that the learned policies are robust against diverse opponents and outperform baseline reinforcement learning policies. Our approach achieves up to 3$\times$ faster convergence and 30$\times$ higher success rates on average against RL-based baselines, demonstrating its robustness to opponent strategies and stability across training iterations
SAC-MoE: Reinforcement Learning with Mixture-of-Experts for Control of Hybrid Dynamical Systems with Uncertainty
Nov 15, 2025
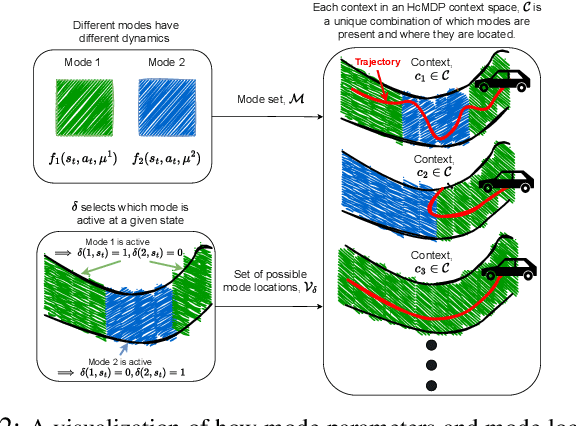
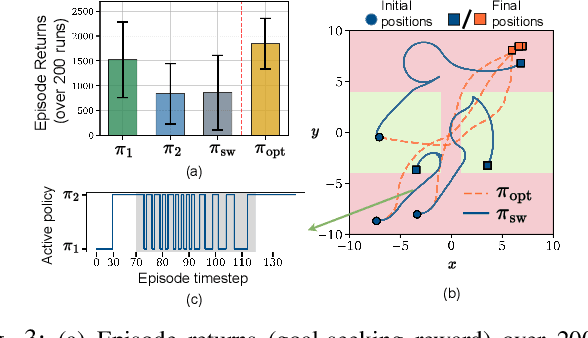
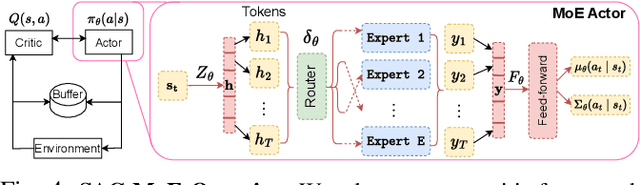
Hybrid dynamical systems result from the interaction of continuous-variable dynamics with discrete events and encompass various systems such as legged robots, vehicles and aircrafts. Challenges arise when the system's modes are characterized by unobservable (latent) parameters and the events that cause system dynamics to switch between different modes are also unobservable. Model-based control approaches typically do not account for such uncertainty in the hybrid dynamics, while standard model-free RL methods fail to account for abrupt mode switches, leading to poor generalization. To overcome this, we propose SAC-MoE which models the actor of the Soft Actor-Critic (SAC) framework as a Mixture-of-Experts (MoE) with a learned router that adaptively selects among learned experts. To further improve robustness, we develop a curriculum-based training algorithm to prioritize data collection in challenging settings, allowing better generalization to unseen modes and switching locations. Simulation studies in hybrid autonomous racing and legged locomotion tasks show that SAC-MoE outperforms baselines (up to 6x) in zero-shot generalization to unseen environments. Our curriculum strategy consistently improves performance across all evaluated policies. Qualitative analysis shows that the interpretable MoE router activates different experts for distinct latent modes.
GenPlan: Generative sequence models as adaptive planners
Dec 11, 2024Offline reinforcement learning has shown tremendous success in behavioral planning by learning from previously collected demonstrations. However, decision-making in multitask missions still presents significant challenges. For instance, a mission might require an agent to explore an unknown environment, discover goals, and navigate to them, even if it involves interacting with obstacles along the way. Such behavioral planning problems are difficult to solve due to: a) agents failing to adapt beyond the single task learned through their reward function, and b) the inability to generalize to new environments not covered in the training demonstrations, e.g., environments where all doors were unlocked in the demonstrations. Consequently, state-of-the-art decision making methods are limited to missions where the required tasks are well-represented in the training demonstrations and can be solved within a short (temporal) planning horizon. To address this, we propose GenPlan: a stochastic and adaptive planner that leverages discrete-flow models for generative sequence modeling, enabling sample-efficient exploration and exploitation. This framework relies on an iterative denoising procedure to generate a sequence of goals and actions. This approach captures multi-modal action distributions and facilitates goal and task discovery, thereby enhancing generalization to out-of-distribution tasks and environments, i.e., missions not part of the training data. We demonstrate the effectiveness of our method through multiple simulation environments. Notably, GenPlan outperforms the state-of-the-art methods by over 10% on adaptive planning tasks, where the agent adapts to multi-task missions while leveraging demonstrations on single-goal-reaching tasks.
Adaptformer: Sequence models as adaptive iterative planners
Nov 30, 2024Despite recent advances in learning-based behavioral planning for autonomous systems, decision-making in multi-task missions remains a challenging problem. For instance, a mission might require a robot to explore an unknown environment, locate the goals, and navigate to them, even if there are obstacles along the way. Such problems are difficult to solve due to: a) sparse rewards, meaning a reward signal is available only once all the tasks in a mission have been satisfied, and b) the agent having to perform tasks at run-time that are not covered in the training data, e.g., demonstrations only from an environment where all doors were unlocked. Consequently, state-of-the-art decision-making methods in such settings are limited to missions where the required tasks are well-represented in the training demonstrations and can be solved within a short planning horizon. To overcome these limitations, we propose Adaptformer, a stochastic and adaptive planner that utilizes sequence models for sample-efficient exploration and exploitation. This framework relies on learning an energy-based heuristic, which needs to be minimized over a sequence of high-level decisions. To generate successful action sequences for long-horizon missions, Adaptformer aims to achieve shorter sub-goals, which are proposed through an intrinsic sub-goal curriculum. Through these two key components, Adaptformer allows for generalization to out-of-distribution tasks and environments, i.e., missions that were not a part of the training data. Empirical results in multiple simulation environments demonstrate the effectiveness of our method. Notably, Adaptformer not only outperforms the state-of-the-art method by up to 25% in multi-goal maze reachability tasks but also successfully adapts to multi-task missions that the state-of-the-art method could not complete, leveraging demonstrations from single-goal-reaching tasks.
CAMM: Building Category-Agnostic and Animatable 3D Models from Monocular Videos
Apr 14, 2023
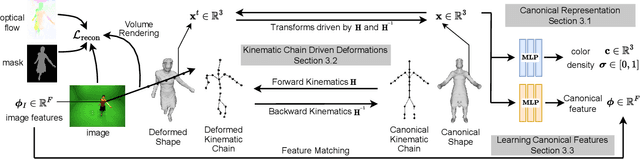
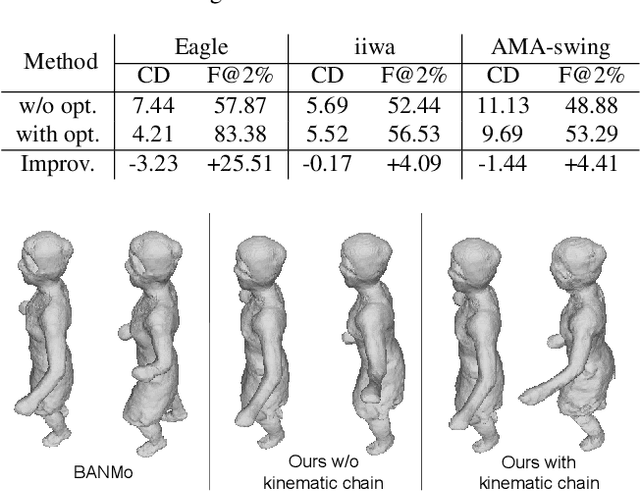
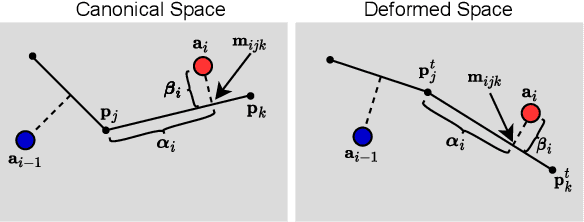
Animating an object in 3D often requires an articulated structure, e.g. a kinematic chain or skeleton of the manipulated object with proper skinning weights, to obtain smooth movements and surface deformations. However, existing models that allow direct pose manipulations are either limited to specific object categories or built with specialized equipment. To reduce the work needed for creating animatable 3D models, we propose a novel reconstruction method that learns an animatable kinematic chain for any articulated object. Our method operates on monocular videos without prior knowledge of the object's shape or underlying structure. Our approach is on par with state-of-the-art 3D surface reconstruction methods on various articulated object categories while enabling direct pose manipulations by re-posing the learned kinematic chain.