 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Atomic Conformational Ensembles of Proteins via Test-Time Supervision of Boltz-2 on Cryo-EM Density Maps
May 11, 2026Knowledge of a protein's atomic conformational ensemble is critical to determining its function, yet state-of-the-art ensemble prediction models are limited by lack of high-quality conformational data from simulation or experiment. Recent advances in heterogeneous reconstruction for cryo-electron microscopy (cryo-EM) have enabled scientists to visualize ensembles of density maps for larger proteins and complexes not typically accessible through simulation, but building atomic models into these maps remains a challenge. Traditionally, ensemble prediction models are trained via a two-stage process: experimental density maps are converted into atomic structural ensembles through model building, after which these structures are used to train sequence-to-atomic ensemble predictors. In this work, we propose a new principle for fine-tuning pre-trained static structure prediction models such as Boltz-2 directly on raw cryo-EM maps, bypassing the two-stage process. We apply this technique to the problem of atomic model building by fine-tuning Boltz-2 to generate atomic conformations from an input ensemble of cryo-EM maps, achieving superior model building accuracy compared to prior work. Beyond overfitting to individual map ensembles, our method, CryoSampler, also shows preliminary evidence of in-domain generalization after fine-tuning, sampling diverse atomic conformations for an unseen sequences within the same protein family without requiring cryo-EM data. These capabilities indicate that CryoSampler holds the potential to train next-generation atomic ensemble prediction models directly on raw cryo-EM measurements.
Scalable 3D Reconstruction From Single Particle X-Ray Diffraction Images Based on Online Machine Learning
Dec 22, 2023X-ray free-electron lasers (XFELs) offer unique capabilities for measuring the structure and dynamics of biomolecules, helping us understand the basic building blocks of life. Notably, high-repetition-rate XFELs enable single particle imaging (X-ray SPI) where individual, weakly scattering biomolecules are imaged under near-physiological conditions with the opportunity to access fleeting states that cannot be captured in cryogenic or crystallized conditions. Existing X-ray SPI reconstruction algorithms, which estimate the unknown orientation of a particle in each captured image as well as its shared 3D structure, are inadequate in handling the massive datasets generated by these emerging XFELs. Here, we introduce X-RAI, an online reconstruction framework that estimates the structure of a 3D macromolecule from large X-ray SPI datasets. X-RAI consists of a convolutional encoder, which amortizes pose estimation over large datasets, as well as a physics-based decoder, which employs an implicit neural representation to enable high-quality 3D reconstruction in an end-to-end, self-supervised manner. We demonstrate that X-RAI achieves state-of-the-art performance for small-scale datasets in simulation and challenging experimental settings and demonstrate its unprecedented ability to process large datasets containing millions of diffraction images in an online fashion. These abilities signify a paradigm shift in X-ray SPI towards real-time capture and reconstruction.
Querying Labelled Data with Scenario Programs for Sim-to-Real Validation
Dec 01, 2021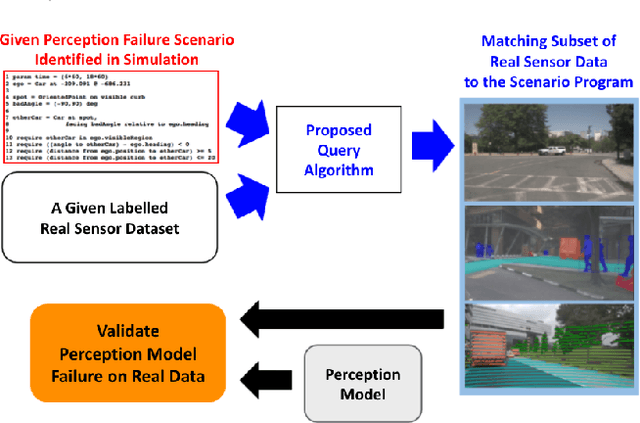

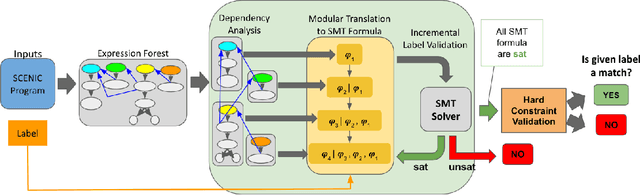
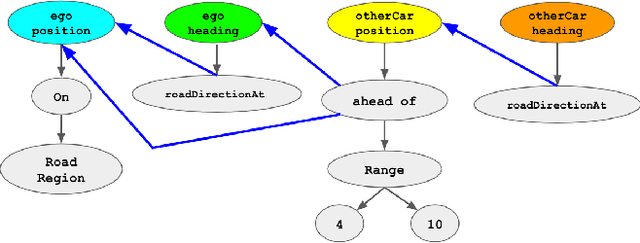
Simulation-based testing of autonomous vehicles (AVs) has become an essential complement to road testing to ensure safety. Consequently, substantial research has focused on searching for failure scenarios in simulation. However, a fundamental question remains: are AV failure scenarios identified in simulation meaningful in reality, i.e., are they reproducible on the real system? Due to the sim-to-real gap arising from discrepancies between simulated and real sensor data, a failure scenario identified in simulation can be either a spurious artifact of the synthetic sensor data or an actual failure that persists with real sensor data. An approach to validate simulated failure scenarios is to identify instances of the scenario in a corpus of real data, and check if the failure persists on the real data. To this end, we propose a formal definition of what it means for a labelled data item to match an abstract scenario, encoded as a scenario program using the SCENIC probabilistic programming language. Using this definition, we develop a querying algorithm which, given a scenario program and a labelled dataset, finds the subset of data matching the scenario. Experiments demonstrate that our algorithm is accurate and efficient on a variety of realistic traffic scenarios, and scales to a reasonable number of agents.
A Scenario-Based Platform for Testing Autonomous Vehicle Behavior Prediction Models in Simulation
Nov 14, 2021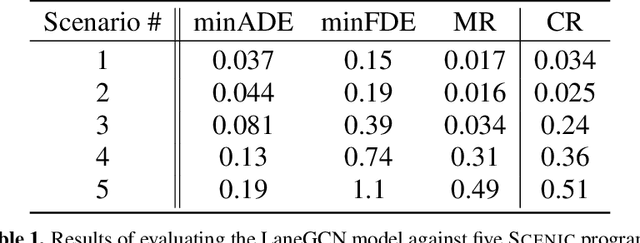

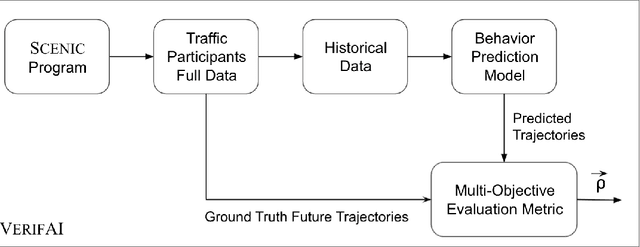
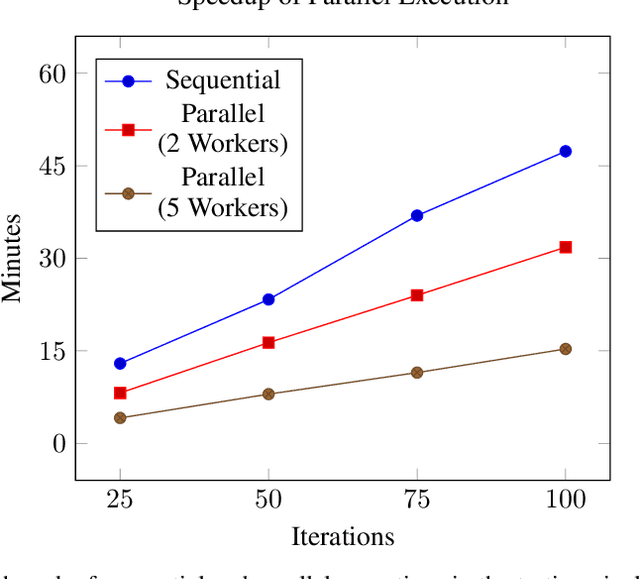
Behavior prediction remains one of the most challenging tasks in the autonomous vehicle (AV) software stack. Forecasting the future trajectories of nearby agents plays a critical role in ensuring road safety, as it equips AVs with the necessary information to plan safe routes of travel. However, these prediction models are data-driven and trained on data collected in real life that may not represent the full range of scenarios an AV can encounter. Hence, it is important that these prediction models are extensively tested in various test scenarios involving interactive behaviors prior to deployment. To support this need, we present a simulation-based testing platform which supports (1) intuitive scenario modeling with a probabilistic programming language called Scenic, (2) specifying a multi-objective evaluation metric with a partial priority ordering, (3) falsification of the provided metric, and (4) parallelization of simulations for scalable testing. As a part of the platform, we provide a library of 25 Scenic programs that model challenging test scenarios involving interactive traffic participant behaviors. We demonstrate the effectiveness and the scalability of our platform by testing a trained behavior prediction model and searching for failure scenarios.
A Customizable Dynamic Scenario Modeling and Data Generation Platform for Autonomous Driving
Nov 30, 2020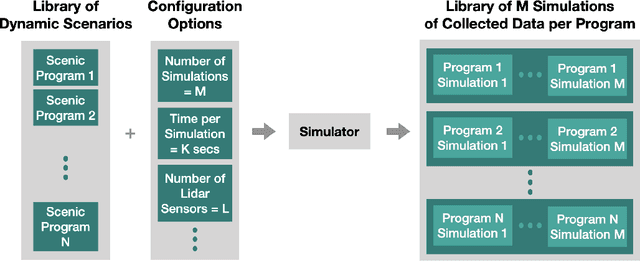
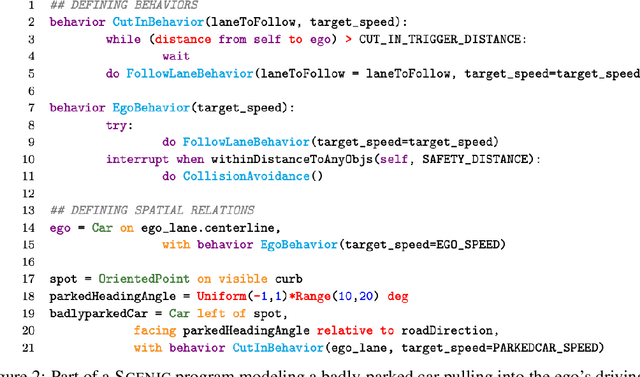
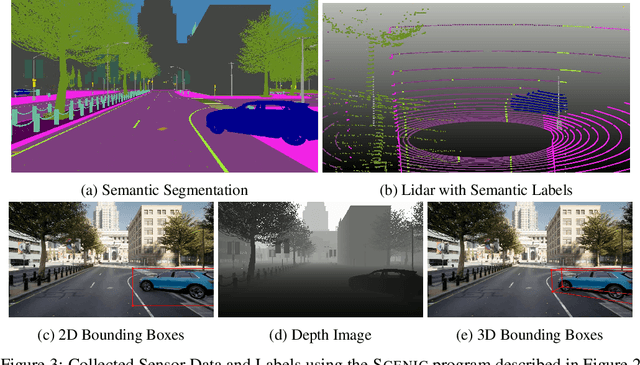
Safely interacting with humans is a significant challenge for autonomous driving. The performance of this interaction depends on machine learning-based modules of an autopilot, such as perception, behavior prediction, and planning. These modules require training datasets with high-quality labels and a diverse range of realistic dynamic behaviors. Consequently, training such modules to handle rare scenarios is difficult because they are, by definition, rarely represented in real-world datasets. Hence, there is a practical need to augment datasets with synthetic data covering these rare scenarios. In this paper, we present a platform to model dynamic and interactive scenarios, generate the scenarios in simulation with different modalities of labeled sensor data, and collect this information for data augmentation. To our knowledge, this is the first integrated platform for these tasks specialized to the autonomous driving domain.
Optimization of Ensemble Supervised Learning Algorithms for Increased Sensitivity, Specificity, and AUC of Population-Based Colorectal Cancer Screenings
Aug 15, 2017
Over 150,000 new people in the United States are diagnosed with colorectal cancer each year. Nearly a third die from it (American Cancer Society). The only approved noninvasive diagnosis tools currently involve fecal blood count tests (FOBTs) or stool DNA tests. Fecal blood count tests take only five minutes and are available over the counter for as low as \$15. They are highly specific, yet not nearly as sensitive, yielding a high percentage (25%) of false negatives (Colon Cancer Alliance). Moreover, FOBT results are far too generalized, meaning that a positive result could mean much more than just colorectal cancer, and could just as easily mean hemorrhoids, anal fissure, proctitis, Crohn's disease, diverticulosis, ulcerative colitis, rectal ulcer, rectal prolapse, ischemic colitis, angiodysplasia, rectal trauma, proctitis from radiation therapy, and others. Stool DNA tests, the modern benchmark for CRC screening, have a much higher sensitivity and specificity, but also cost \$600, take two weeks to process, and are not for high-risk individuals or people with a history of polyps. To yield a cheap and effective CRC screening alternative, a unique ensemble-based classification algorithm is put in place that considers the FIT result, BMI, smoking history, and diabetic status of patients. This method is tested under ten-fold cross validation to have a .95 AUC, 92% specificity, 89% sensitivity, .88 F1, and 90% precision. Once clinically validated, this test promises to be cheaper, faster, and potentially more accurate when compared to a stool DNA test.