 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully invertible hyperbolic neural networks for segmenting large-scale surface and sub-surface data
Jun 30, 2024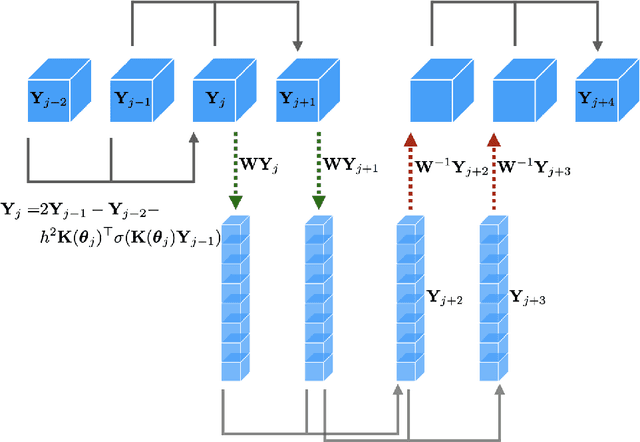
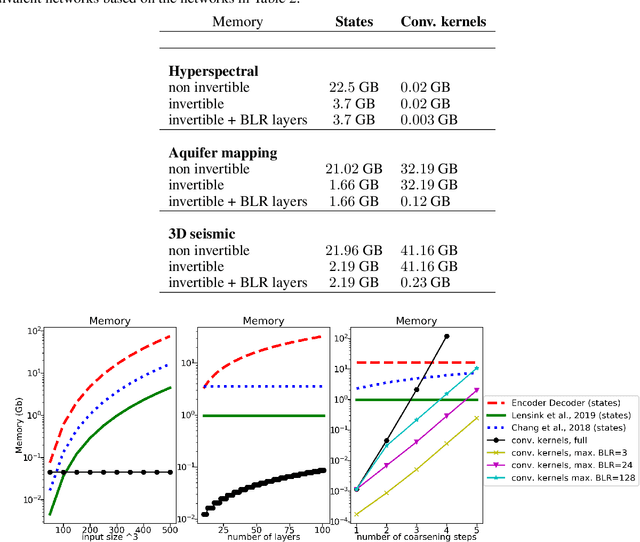
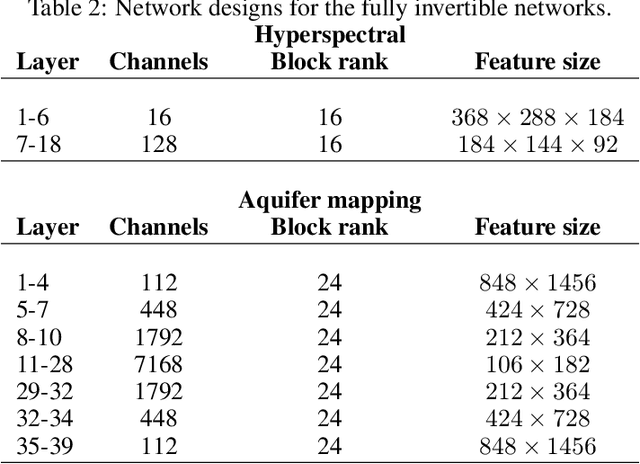
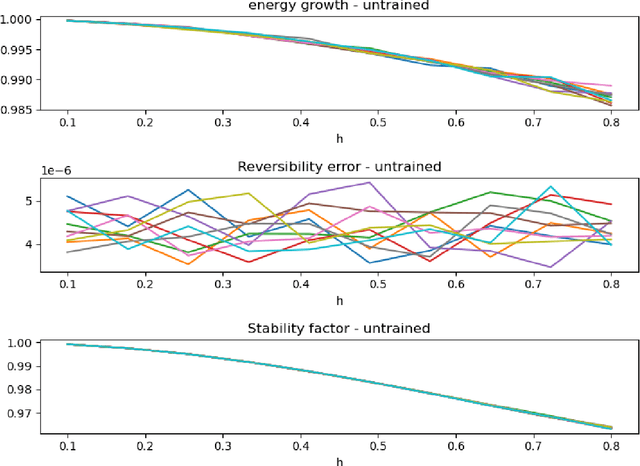
The large spatial/temporal/frequency scale of geoscience and remote-sensing datasets causes memory issues when using convolutional neural networks for (sub-) surface data segmentation. Recently developed fully reversible or fully invertible networks can mostly avoid memory limitations by recomputing the states during the backward pass through the network. This results in a low and fixed memory requirement for storing network states, as opposed to the typical linear memory growth with network depth. This work focuses on a fully invertible network based on the telegraph equation. While reversibility saves the major amount of memory used in deep networks by the data, the convolutional kernels can take up most memory if fully invertible networks contain multiple invertible pooling/coarsening layers. We address the explosion of the number of convolutional kernels by combining fully invertible networks with layers that contain the convolutional kernels in a compressed form directly. A second challenge is that invertible networks output a tensor the same size as its input. This property prevents the straightforward application of invertible networks to applications that map between different input-output dimensions, need to map to outputs with more channels than present in the input data, or desire outputs that decrease/increase the resolution compared to the input data. However, we show that by employing invertible networks in a non-standard fashion, we can still use them for these tasks. Examples in hyperspectral land-use classification, airborne geophysical surveying, and seismic imaging illustrate that we can input large data volumes in one chunk and do not need to work on small patches, use dimensionality reduction, or employ methods that classify a patch to a single central pixel.
Segmentation of Pulmonary Opacification in Chest CT Scans of COVID-19 Patients
Jul 08, 2020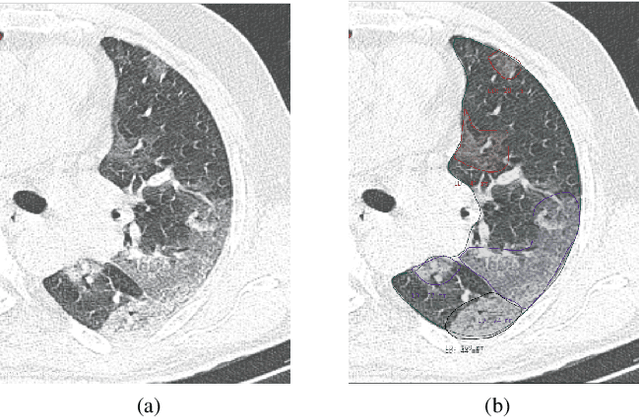
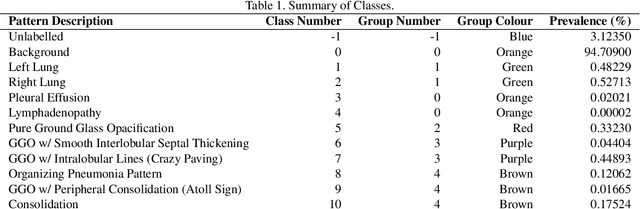
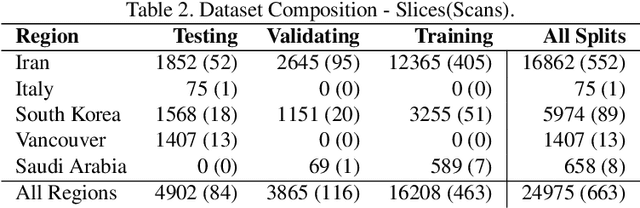
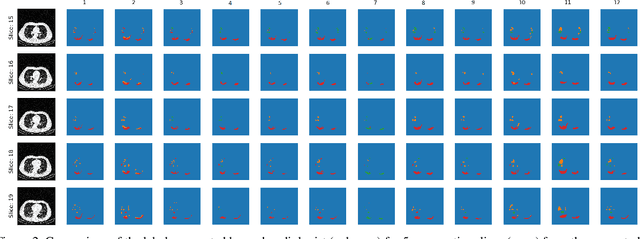
The Severe Acute Respiratory Syndrome Coronavirus 2 (SARS-CoV-2) has rapidly spread into a global pandemic. A form of pneumonia, presenting as opacities with in a patient's lungs, is the most common presentation associated with this virus, and great attention has gone into how these changes relate to patient morbidity and mortality. In this work we provide open source models for the segmentation of patterns of pulmonary opacification on chest Computed Tomography (CT) scans which have been correlated with various stages and severities of infection. We have collected 663 chest CT scans of COVID-19 patients from healthcare centers around the world, and created pixel wise segmentation labels for nearly 25,000 slices that segment 6 different patterns of pulmonary opacification. We provide open source implementations and pre-trained weights for multiple segmentation models trained on our dataset. Our best model achieves an opacity Intersection-Over-Union score of 0.76 on our test set, demonstrates successful domain adaptation, and predicts the volume of opacification within 1.7\% of expert radiologists. Additionally, we present an analysis of the inter-observer variability inherent to this task, and propose methods for appropriate probabilistic approaches.
A Weakly Supervised Region-Based Active Learning Method for COVID-19 Segmentation in CT Images
Jul 07, 2020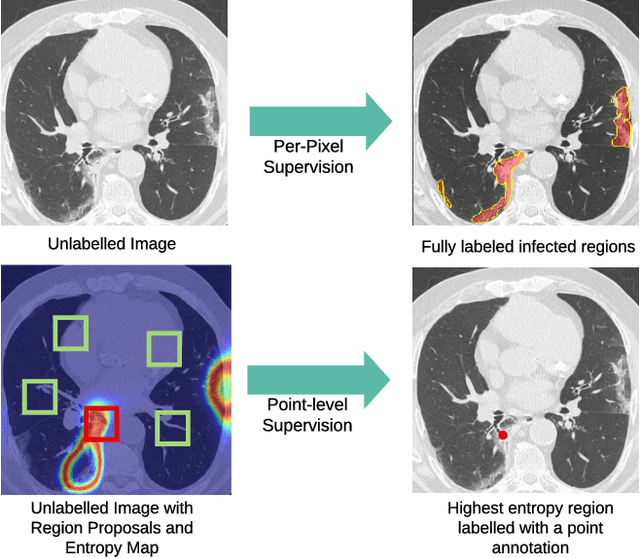
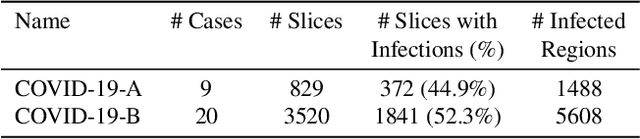
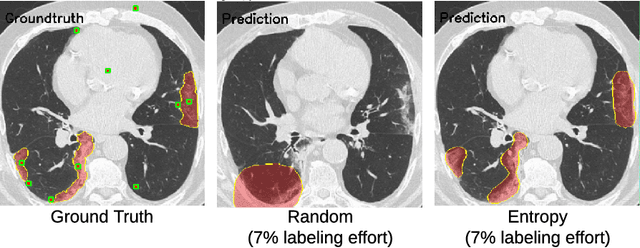
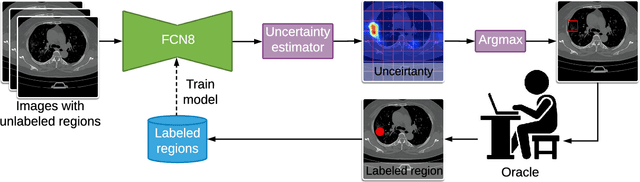
One of the key challenges in the battle against the Coronavirus (COVID-19) pandemic is to detect and quantify the severity of the disease in a timely manner. Computed tomographies (CT) of the lungs are effective for assessing the state of the infection. Unfortunately, labeling CT scans can take a lot of time and effort, with up to 150 minutes per scan. We address this challenge introducing a scalable, fast, and accurate active learning system that accelerates the labeling of CT scan images. Conventionally, active learning methods require the labelers to annotate whole images with full supervision, but that can lead to wasted efforts as many of the annotations could be redundant. Thus, our system presents the annotator with unlabeled regions that promise high information content and low annotation cost. Further, the system allows annotators to label regions using point-level supervision, which is much cheaper to acquire than per-pixel annotations. Our experiments on open-source COVID-19 datasets show that using an entropy-based method to rank unlabeled regions yields to significantly better results than random labeling of these regions. Also, we show that labeling small regions of images is more efficient than labeling whole images. Finally, we show that with only 7\% of the labeling effort required to label the whole training set gives us around 90\% of the performance obtained by training the model on the fully annotated training set. Code is available at: \url{https://github.com/IssamLaradji/covid19_active_learning}.
A Weakly Supervised Consistency-based Learning Method for COVID-19 Segmentation in CT Images
Jul 07, 2020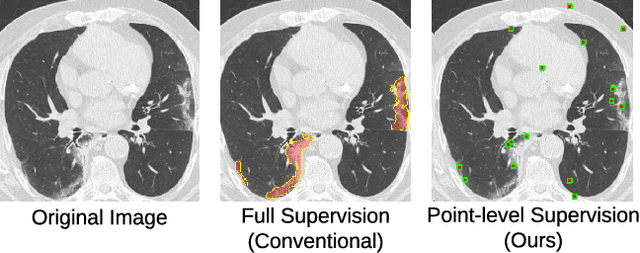

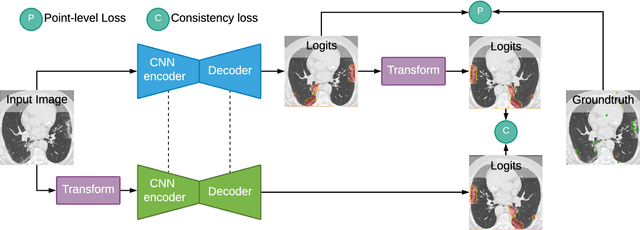
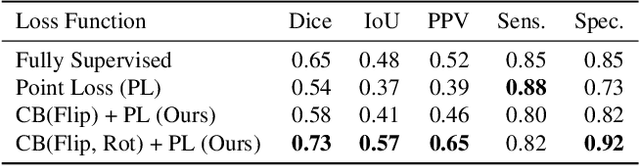
Coronavirus Disease 2019 (COVID-19) has spread aggressively across the world causing an existential health crisis. Thus, having a system that automatically detects COVID-19 in tomography (CT) images can assist in quantifying the severity of the illness. Unfortunately, labelling chest CT scans requires significant domain expertise, time, and effort. We address these labelling challenges by only requiring point annotations, a single pixel for each infected region on a CT image. This labeling scheme allows annotators to label a pixel in a likely infected region, only taking 1-3 seconds, as opposed to 10-15 seconds to segment a region. Conventionally, segmentation models train on point-level annotations using the cross-entropy loss function on these labels. However, these models often suffer from low precision. Thus, we propose a consistency-based (CB) loss function that encourages the output predictions to be consistent with spatial transformations of the input images. The experiments on 3 open-source COVID-19 datasets show that this loss function yields significant improvement over conventional point-level loss functions and almost matches the performance of models trained with full supervision with much less human effort. Code is available at: \url{https://github.com/IssamLaradji/covid19_weak_supervision}.
Fully reversible neural networks for large-scale surface and sub-surface characterization via remote sensing
Mar 16, 2020
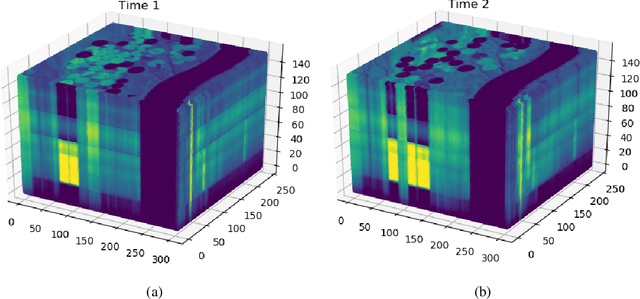
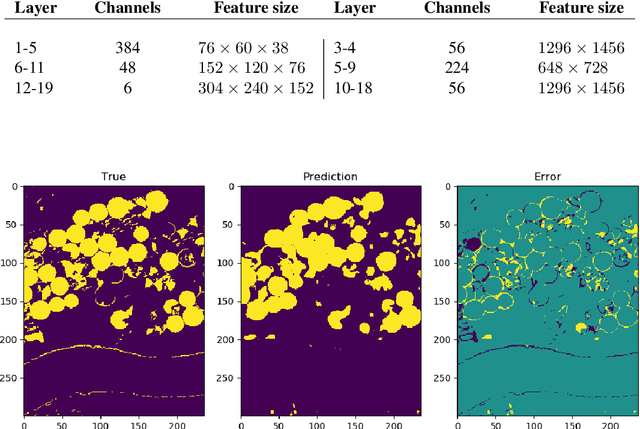
The large spatial/frequency scale of hyperspectral and airborne magnetic and gravitational data causes memory issues when using convolutional neural networks for (sub-) surface characterization. Recently developed fully reversible networks can mostly avoid memory limitations by virtue of having a low and fixed memory requirement for storing network states, as opposed to the typical linear memory growth with depth. Fully reversible networks enable the training of deep neural networks that take in entire data volumes, and create semantic segmentations in one go. This approach avoids the need to work in small patches or map a data patch to the class of just the central pixel. The cross-entropy loss function requires small modifications to work in conjunction with a fully reversible network and learn from sparsely sampled labels without ever seeing fully labeled ground truth. We show examples from land-use change detection from hyperspectral time-lapse data, and regional aquifer mapping from airborne geophysical and geological data.
Symmetric block-low-rank layers for fully reversible multilevel neural networks
Dec 14, 2019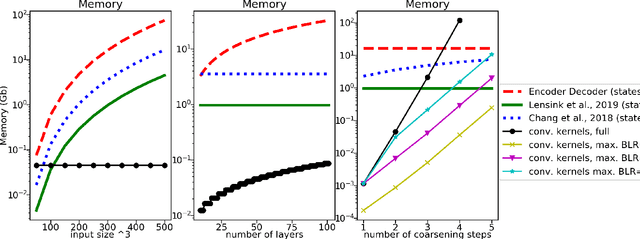
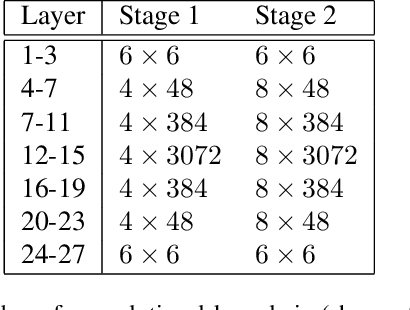
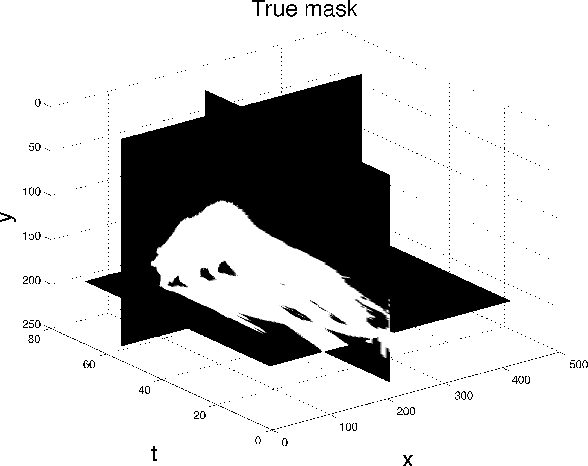
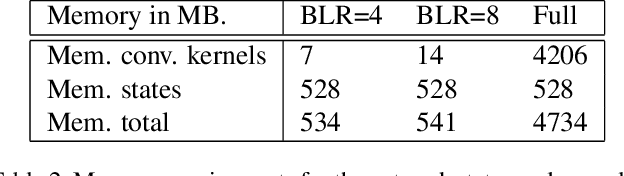
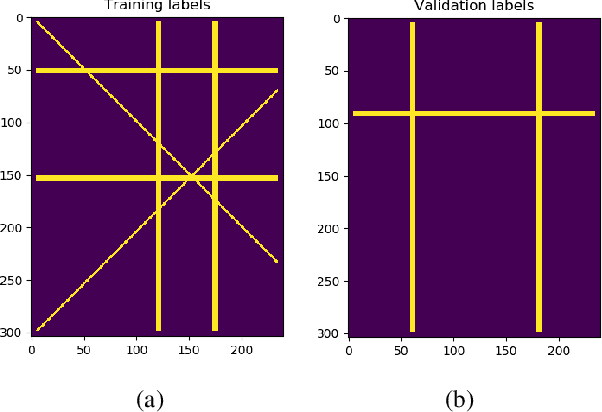
Factors that limit the size of the input and output of a neural network include memory requirements for the network states/activations to compute gradients, as well as memory for the convolutional kernels or other weights. The memory restriction is especially limiting for applications where we want to learn how to map volumetric data to the desired output, such as video-to-video. Recently developed fully reversible neural networks enable gradient computations using storage of the network states for a couple of layers only. While this saves a tremendous amount of memory, it is the convolutional kernels that take up most memory if fully reversible networks contain multiple invertible pooling/coarsening layers. Invertible coarsening operators such as the orthogonal wavelet transform cause the number of channels to grow explosively. We address this issue by combining fully reversible networks with layers that contain the convolutional kernels in a compressed form directly. Specifically, we introduce a layer that has a symmetric block-low-rank structure. In spirit, this layer is similar to bottleneck and squeeze-and-expand structures. We contribute symmetry by construction, and a combination of notation and flattening of tensors allows us to interpret these network structures in linear algebraic fashion as a block-low-rank matrix in factorized form and observe various properties. A video segmentation example shows that we can train a network to segment the entire video in one go, which would not be possible, in terms of memory requirements, using non-reversible networks and previously proposed reversible networks.
Fluid Flow Mass Transport for Generative Networks
Oct 07, 2019
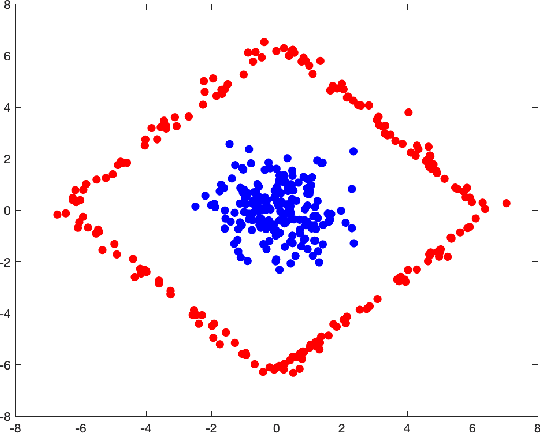

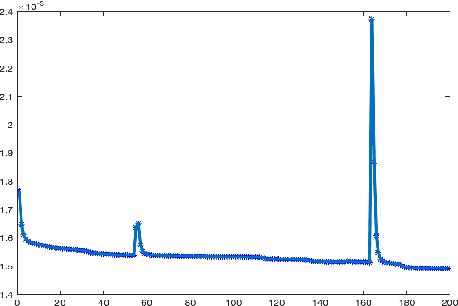
Generative Adversarial Networks have been shown to be powerful in generating content. To this end, they have been studied intensively in the last few years. Nonetheless, training these networks requires solving a saddle point problem that is difficult to solve and slowly converging. Motivated from techniques in the registration of point clouds and by the fluid flow formulation of mass transport, we investigate a new formulation that is based on strict minimization, without the need for the maximization. The formulation views the problem as a matching problem rather than an adversarial one and thus allows us to quickly converge and obtain meaningful metrics in the optimization path.
Fully Hyperbolic Convolutional Neural Networks
May 24, 2019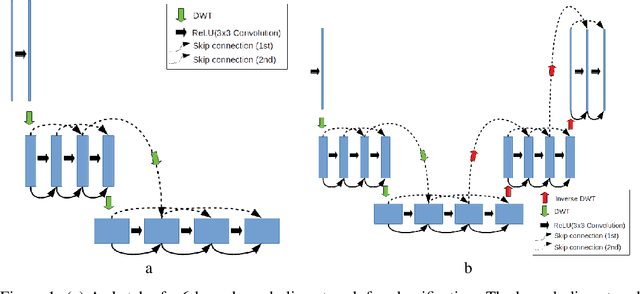



Convolutional Neural Networks (CNN) have recently seen tremendous success in various computer vision tasks. However, their application to problems with high dimensional input and output has been limited by two factors. First, in the training stage, it is necessary to store network activations for back propagation. Second, in the inference stage, a few copies of the image are typically stored to be concatenated to other network states deeper in the network. In these settings, the memory requirements associated with storing activations can exceed what is feasible with current hardware. For the problem of image classification, reversible architectures have been proposed that allow one to recalculate activations in the backwards pass instead of storing them, however, such networks do not perform well for problems such as segmentation. Furthermore, currently only block reversible networks have been possible because pooling operations are not reversible. Motivated by the propagation of signals over physical networks, that are governed by the hyperbolic Telegraph equation, in this work we introduce a fully conservative hyperbolic network for problems with high dimensional input and output. We introduce a coarsening operation that allows completely reversible CNNs by using the Discrete Wavelet Transform and its inverse to both coarsen and interpolate the network state and change the number of channels. This means that during training we do not need to store the activations from the forward pass, and can train arbitrarily deep or wide networks. Furthermore, our network has a much lower memory footprint for inference. We show that we are able to achieve results comparable to the state of the art in image classification, depth estimation, and semantic segmentation, with a much lower memory footprint.
IMEXnet: A Forward Stable Deep Neural Network
Mar 06, 2019
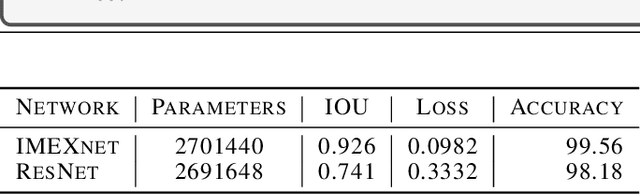
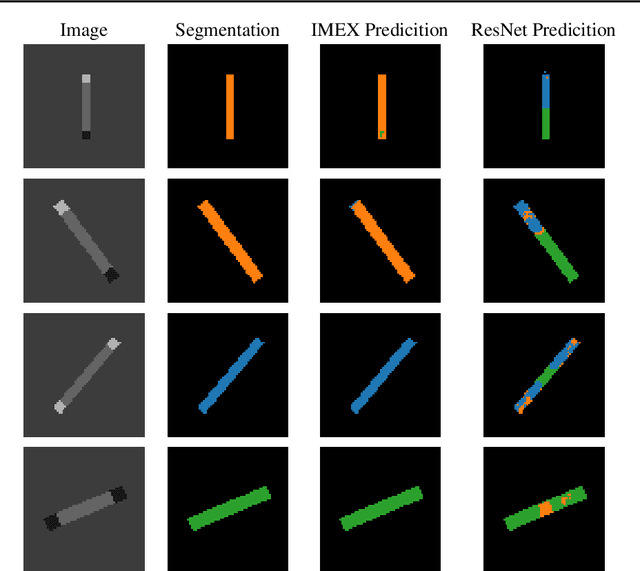

Deep convolutional neural networks have revolutionized many machine learning and computer vision tasks. Despite their enormous success, remaining key challenges limit their wider use. Pressing challenges include improving the network's robustness to perturbations of the input images and simplifying the design of architectures that generalize. Another problem relates to the limited "field of view" of convolution operators, which means that very deep networks are required to model nonlocal relations in high-resolution image data. We introduce the IMEXnet that addresses these challenges by adapting semi-implicit methods for partial differential equations. Compared to similar explicit networks such as the residual networks (ResNets) our network is more stable. This stability has been recently shown to reduce the sensitivity to small changes in the input features and improve generalization. The implicit step connects all pixels in the images and therefore addresses the field of view problem, while being comparable to standard convolutions in terms of the number of parameters and computational complexity. We also present a new dataset for semantic segmentation and demonstrate the effectiveness of our architecture using the NYU depth dataset.