 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Information Maximization for Medical Imaging: CMIM
Oct 20, 2020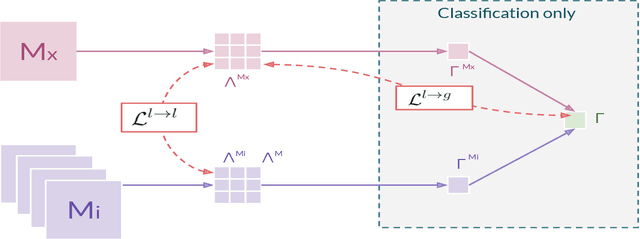

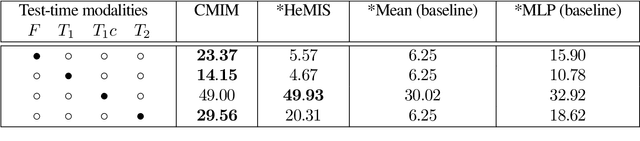
In hospitals, data are siloed to specific information systems that make the same information available under different modalities such as the different medical imaging exams the patient undergoes (CT scans, MRI, PET, Ultrasound, etc.) and their associated radiology reports. This offers unique opportunities to obtain and use at train-time those multiple views of the same information that might not always be available at test-time. In this paper, we propose an innovative framework that makes the most of available data by learning good representations of a multi-modal input that are resilient to modality dropping at test-time, using recent advances in mutual information maximization. By maximizing cross-modal information at train time, we are able to outperform several state-of-the-art baselines in two different settings, medical image classification, and segmentation. In particular, our method is shown to have a strong impact on the inference-time performance of weaker modalities.
InfoMask: Masked Variational Latent Representation to Localize Chest Disease
Mar 28, 2019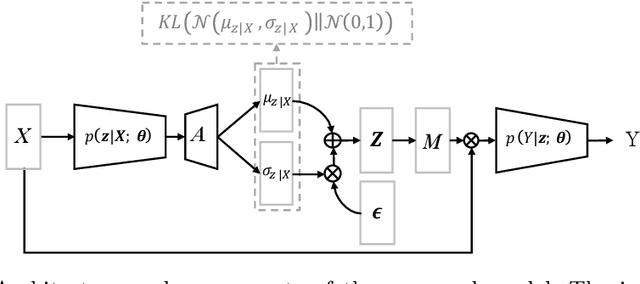
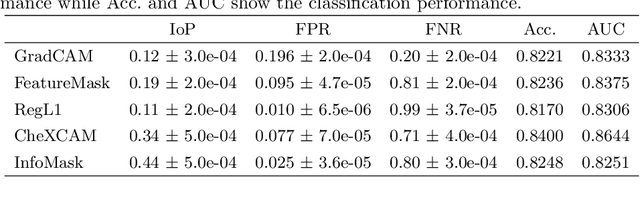

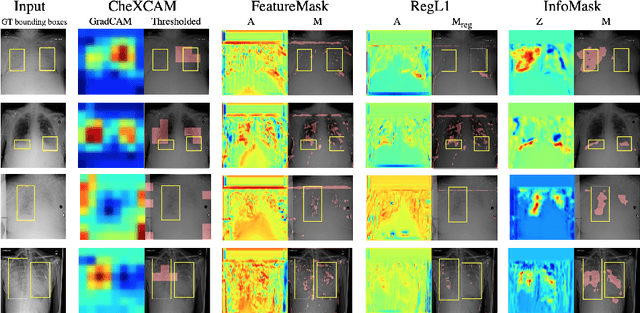
The scarcity of richly annotated medical images is limiting supervised deep learning based solutions to medical image analysis tasks, such as localizing discriminatory radiomic disease signatures. Therefore, it is desirable to leverage unsupervised and weakly supervised models. Most recent weakly supervised localization methods apply attention maps or region proposals in a multiple instance learning formulation. While attention maps can be noisy, leading to erroneously highlighted regions, it is not simple to decide on an optimal window/bag size for multiple instance learning approaches. In this paper, we propose a learned spatial masking mechanism to filter out irrelevant background signals from attention maps. The proposed method minimizes mutual information between a masked variational representation and the input while maximizing the information between the masked representation and class labels. This results in more accurate localization of discriminatory regions. We tested the proposed model on the ChestX-ray8 dataset to localize pneumonia from chest X-ray images without using any pixel-level or bounding-box annotations.