 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of Homomorphic Encryption in Medical Imaging
Oct 12, 2021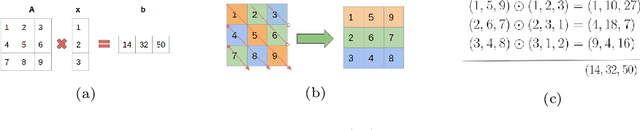
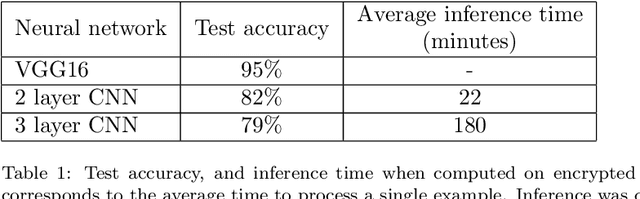
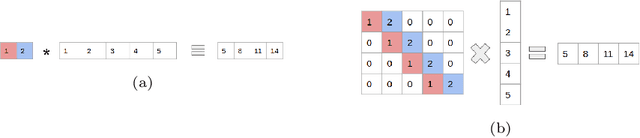
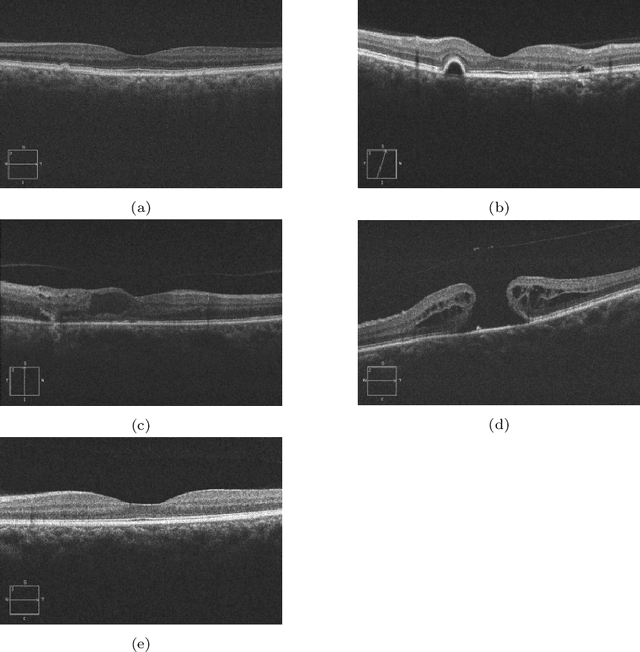
In this technical report, we explore the use of homomorphic encryption (HE) in the context of training and predicting with deep learning (DL) models to deliver strict \textit{Privacy by Design} services, and to enforce a zero-trust model of data governance. First, we show how HE can be used to make predictions over medical images while preventing unauthorized secondary use of data, and detail our results on a disease classification task with OCT images. Then, we demonstrate that HE can be used to secure the training of DL models through federated learning, and report some experiments using 3D chest CT-Scans for a nodule detection task.
Precision-Weighted Federated Learning
Jul 20, 2021
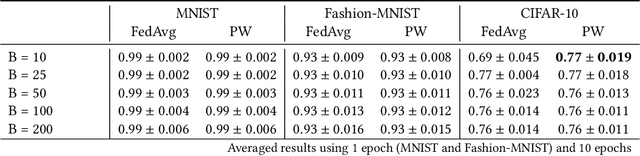

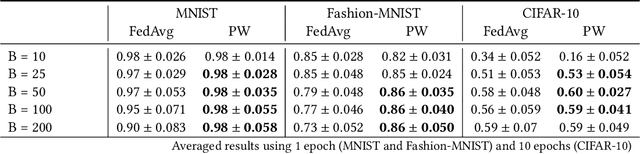
Federated Learning using the Federated Averaging algorithm has shown great advantages for large-scale applications that rely on collaborative learning, especially when the training data is either unbalanced or inaccessible due to privacy constraints. We hypothesize that Federated Averaging underestimates the full extent of heterogeneity of data when the aggregation is performed. We propose Precision-weighted Federated Learning a novel algorithm that takes into account the variance of the stochastic gradients when computing the weighted average of the parameters of models trained in a Federated Learning setting. With Precision-weighted Federated Learning, we provide an alternate averaging scheme that leverages the heterogeneity of the data when it has a large diversity of features in its composition. Our method was evaluated using standard image classification datasets with two different data partitioning strategies (IID/non-IID) to measure the performance and speed of our method in resource-constrained environments, such as mobile and IoT devices. We obtained a good balance between computational efficiency and convergence rates with Precision-weighted Federated Learning. Our performance evaluations show 9% better predictions with MNIST, 18% with Fashion-MNIST, and 5% with CIFAR-10 in the non-IID setting. Further reliability evaluations ratify the stability in our method by reaching a 99% reliability index with IID partitions and 96% with non-IID partitions. In addition, we obtained a 20x speedup on Fashion-MNIST with only 10 clients and up to 37x with 100 clients participating in the aggregation concurrently per communication round. The results indicate that Precision-weighted Federated Learning is an effective and faster alternative approach for aggregating private data, especially in domains where data is highly heterogeneous.
Cross-Modal Information Maximization for Medical Imaging: CMIM
Oct 20, 2020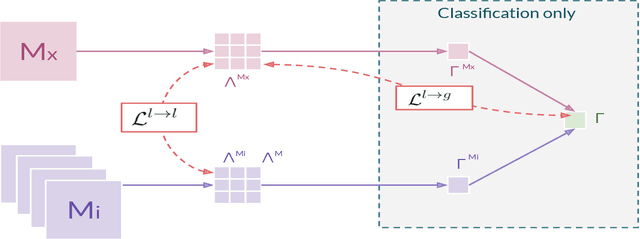

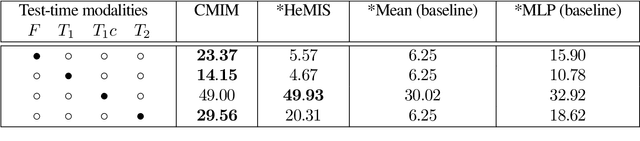
In hospitals, data are siloed to specific information systems that make the same information available under different modalities such as the different medical imaging exams the patient undergoes (CT scans, MRI, PET, Ultrasound, etc.) and their associated radiology reports. This offers unique opportunities to obtain and use at train-time those multiple views of the same information that might not always be available at test-time. In this paper, we propose an innovative framework that makes the most of available data by learning good representations of a multi-modal input that are resilient to modality dropping at test-time, using recent advances in mutual information maximization. By maximizing cross-modal information at train time, we are able to outperform several state-of-the-art baselines in two different settings, medical image classification, and segmentation. In particular, our method is shown to have a strong impact on the inference-time performance of weaker modalities.
Learn Faster and Forget Slower via Fast and Stable Task Adaptation
Jul 02, 2020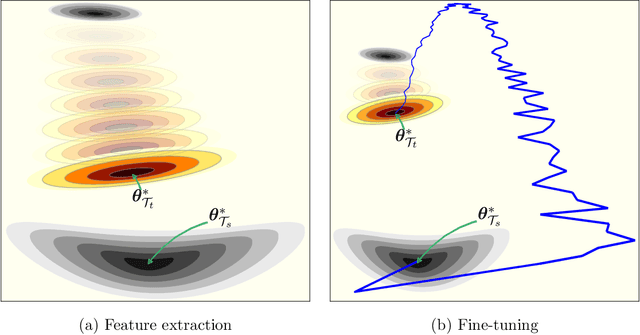

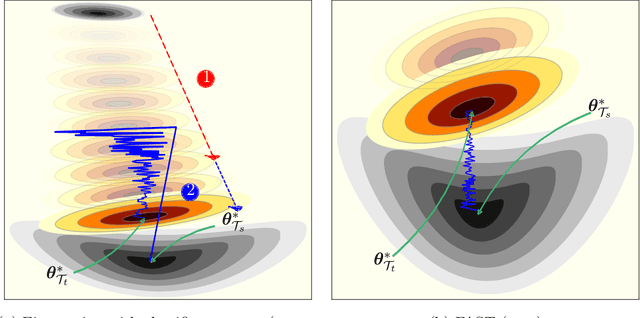
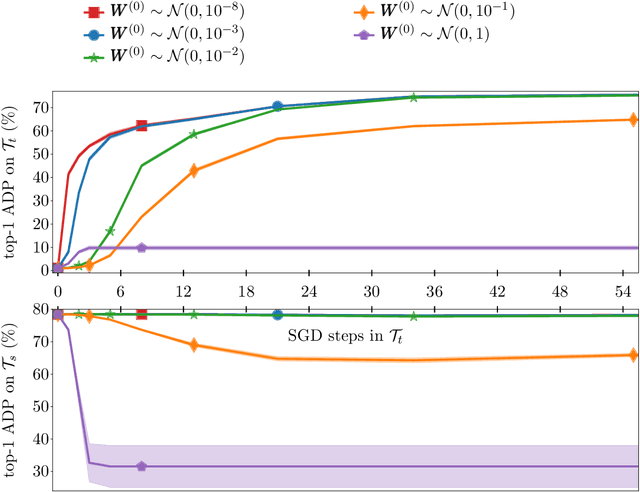
Training Deep Neural Networks (DNNs) is still highly time-consuming and compute-intensive. It has been shown that adapting a pretrained model may significantly accelerate this process. With a focus on classification, we show that current fine-tuning techniques make the pretrained models catastrophically forget the transferred knowledge even before anything about the new task is learned. Such rapid knowledge loss undermines the merits of transfer learning and may result in a much slower convergence rate compared to when the maximum amount of knowledge is exploited. We investigate the source of this problem from different perspectives and to alleviate it, introduce Fast And Stable Task-adaptation (FAST), an easy to apply fine-tuning algorithm. The paper provides a novel geometric perspective on how the loss landscape of source and target tasks are linked in different transfer learning strategies. We empirically show that compared to prevailing fine-tuning practices, FAST learns the target task faster and forgets the source task slower. The code is available at https://github.com/fvarno/FAST.
Dual Adversarial Inference for Text-to-Image Synthesis
Aug 14, 2019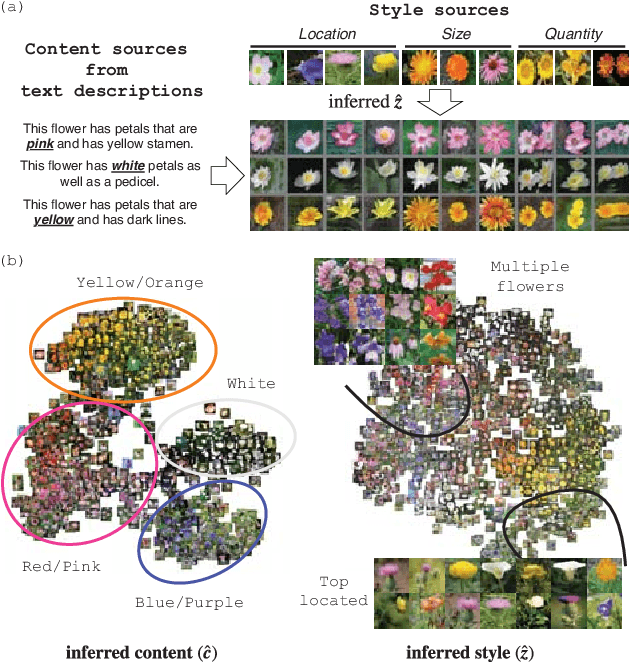

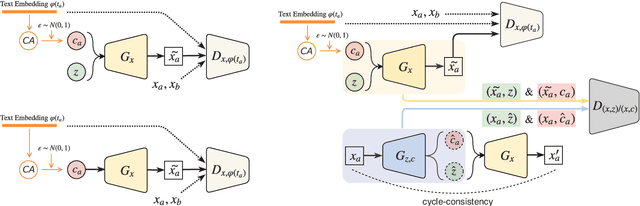
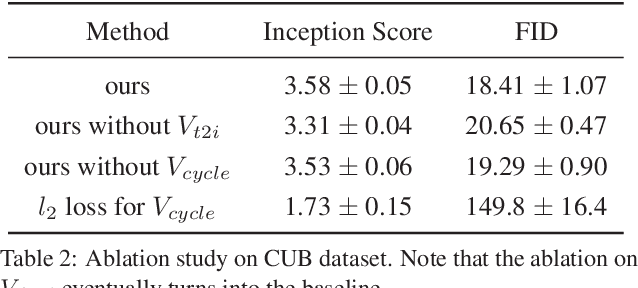
Synthesizing images from a given text description involves engaging two types of information: the content, which includes information explicitly described in the text (e.g., color, composition, etc.), and the style, which is usually not well described in the text (e.g., location, quantity, size, etc.). However, in previous works, it is typically treated as a process of generating images only from the content, i.e., without considering learning meaningful style representations. In this paper, we aim to learn two variables that are disentangled in the latent space, representing content and style respectively. We achieve this by augmenting current text-to-image synthesis frameworks with a dual adversarial inference mechanism. Through extensive experiments, we show that our model learns, in an unsupervised manner, style representations corresponding to certain meaningful information present in the image that are not well described in the text. The new framework also improves the quality of synthesized images when evaluated on Oxford-102, CUB and COCO datasets.
Efficient Neural Task Adaptation by Maximum Entropy Initialization
May 25, 2019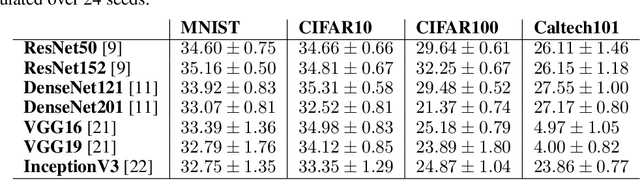
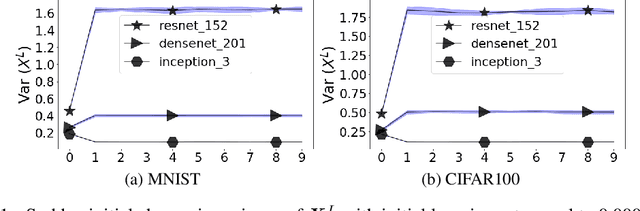
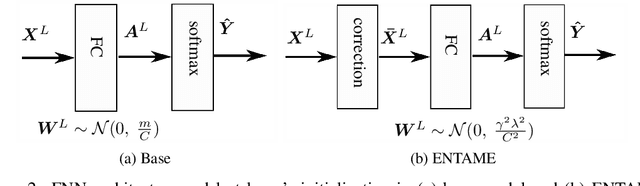
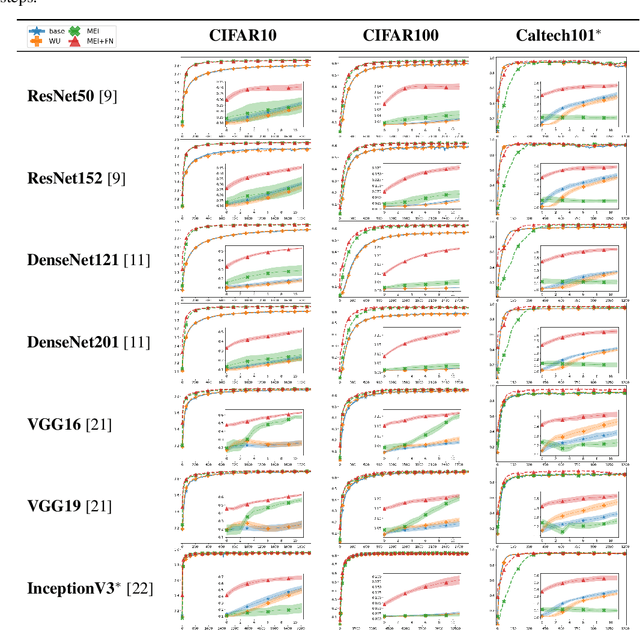
Transferring knowledge from one neural network to another has been shown to be helpful for learning tasks with few training examples. Prevailing fine-tuning methods could potentially contaminate pre-trained features by comparably high energy random noise. This noise is mainly delivered from a careless replacement of task-specific parameters. We analyze theoretically such knowledge contamination for classification tasks and propose a practical and easy to apply method to trap and minimize the contaminant. In our approach, the entropy of the output estimates gets maximized initially and the first back-propagated error is stalled at the output of the last layer. Our proposed method not only outperforms the traditional fine-tuning, but also significantly speeds up the convergence of the learner. It is robust to randomness and independent of the choice of architecture. Overall, our experiments show that the power of transfer learning has been substantially underestimated so far.
InfoMask: Masked Variational Latent Representation to Localize Chest Disease
Mar 28, 2019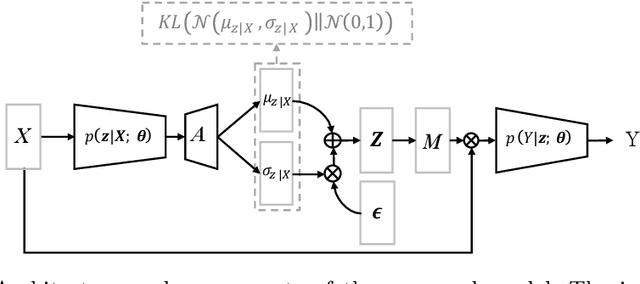
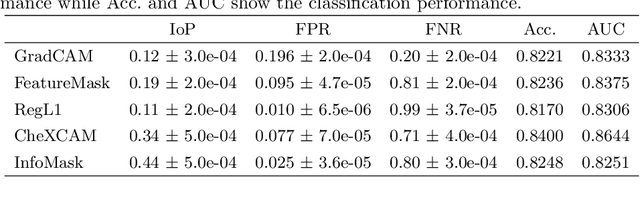

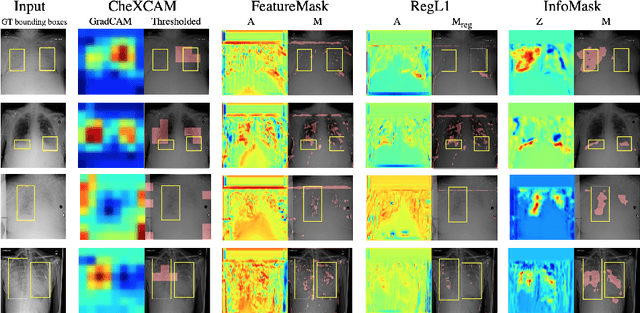
The scarcity of richly annotated medical images is limiting supervised deep learning based solutions to medical image analysis tasks, such as localizing discriminatory radiomic disease signatures. Therefore, it is desirable to leverage unsupervised and weakly supervised models. Most recent weakly supervised localization methods apply attention maps or region proposals in a multiple instance learning formulation. While attention maps can be noisy, leading to erroneously highlighted regions, it is not simple to decide on an optimal window/bag size for multiple instance learning approaches. In this paper, we propose a learned spatial masking mechanism to filter out irrelevant background signals from attention maps. The proposed method minimizes mutual information between a masked variational representation and the input while maximizing the information between the masked representation and class labels. This results in more accurate localization of discriminatory regions. We tested the proposed model on the ChestX-ray8 dataset to localize pneumonia from chest X-ray images without using any pixel-level or bounding-box annotations.
Learning Normalized Inputs for Iterative Estimation in Medical Image Segmentation
Feb 16, 2017
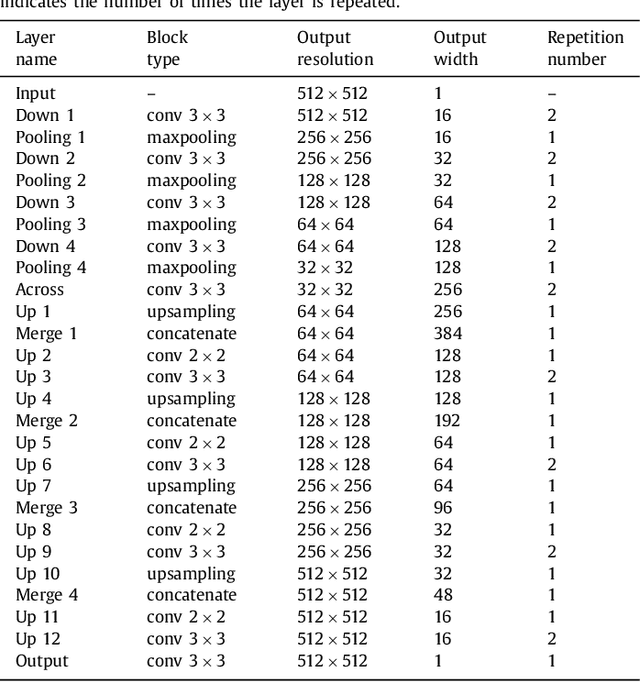
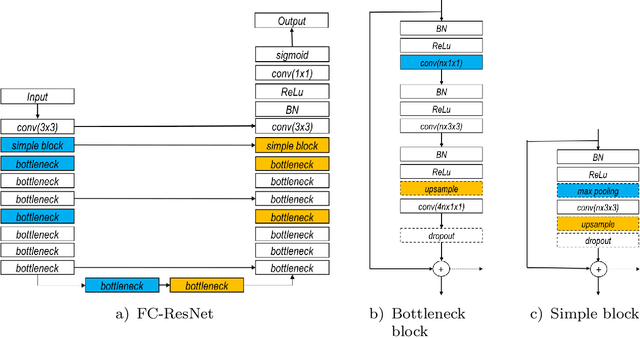

In this paper, we introduce a simple, yet powerful pipeline for medical image segmentation that combines Fully Convolutional Networks (FCNs) with Fully Convolutional Residual Networks (FC-ResNets). We propose and examine a design that takes particular advantage of recent advances in the understanding of both Convolutional Neural Networks as well as ResNets. Our approach focuses upon the importance of a trainable pre-processing when using FC-ResNets and we show that a low-capacity FCN model can serve as a pre-processor to normalize medical input data. In our image segmentation pipeline, we use FCNs to obtain normalized images, which are then iteratively refined by means of a FC-ResNet to generate a segmentation prediction. As in other fully convolutional approaches, our pipeline can be used off-the-shelf on different image modalities. We show that using this pipeline, we exhibit state-of-the-art performance on the challenging Electron Microscopy benchmark, when compared to other 2D methods. We improve segmentation results on CT images of liver lesions, when contrasting with standard FCN methods. Moreover, when applying our 2D pipeline on a challenging 3D MRI prostate segmentation challenge we reach results that are competitive even when compared to 3D methods. The obtained results illustrate the strong potential and versatility of the pipeline by achieving highly accurate results on multi-modality images from different anatomical regions and organs.