 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn Faster and Forget Slower via Fast and Stable Task Adaptation
Paper and Code
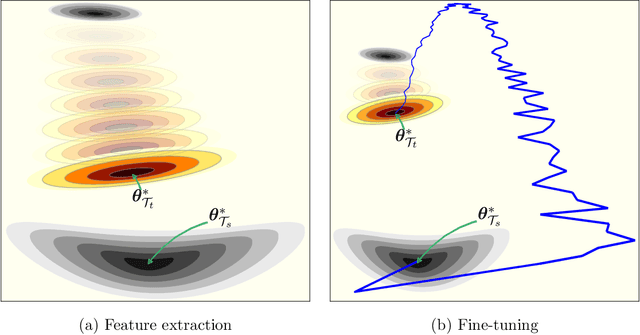

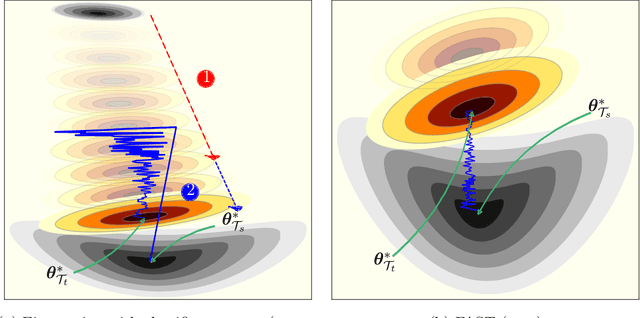
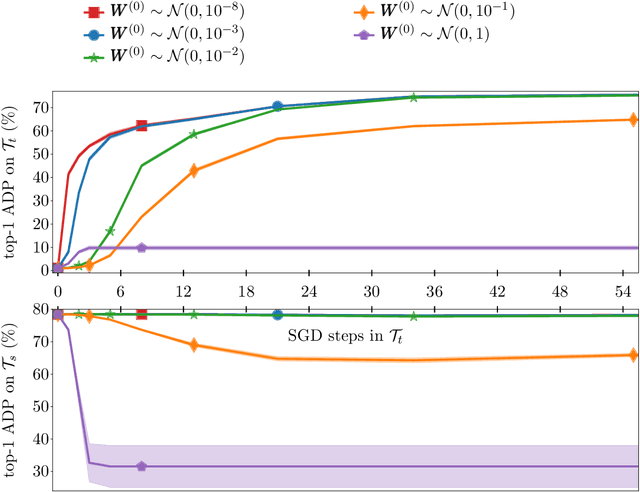
Training Deep Neural Networks (DNNs) is still highly time-consuming and compute-intensive. It has been shown that adapting a pretrained model may significantly accelerate this process. With a focus on classification, we show that current fine-tuning techniques make the pretrained models catastrophically forget the transferred knowledge even before anything about the new task is learned. Such rapid knowledge loss undermines the merits of transfer learning and may result in a much slower convergence rate compared to when the maximum amount of knowledge is exploited. We investigate the source of this problem from different perspectives and to alleviate it, introduce Fast And Stable Task-adaptation (FAST), an easy to apply fine-tuning algorithm. The paper provides a novel geometric perspective on how the loss landscape of source and target tasks are linked in different transfer learning strategies. We empirically show that compared to prevailing fine-tuning practices, FAST learns the target task faster and forgets the source task slower. The code is available at https://github.com/fvarno/FAST.