 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Client Drift in Federated Learning via Adaptive Bias Estimation
Apr 27, 2022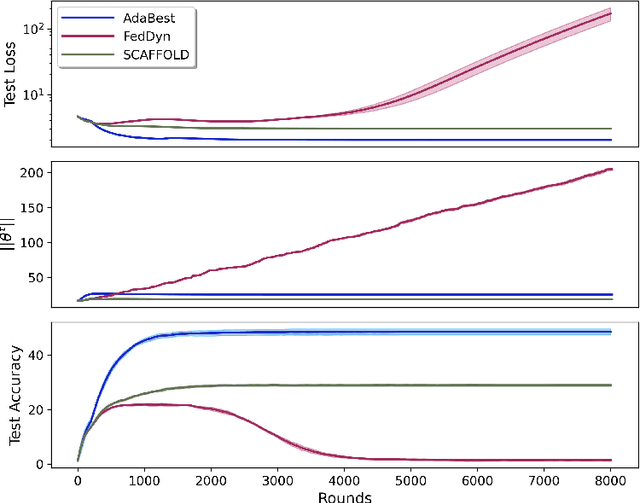

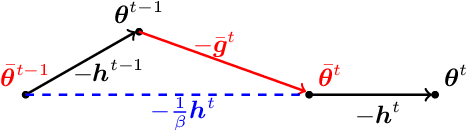
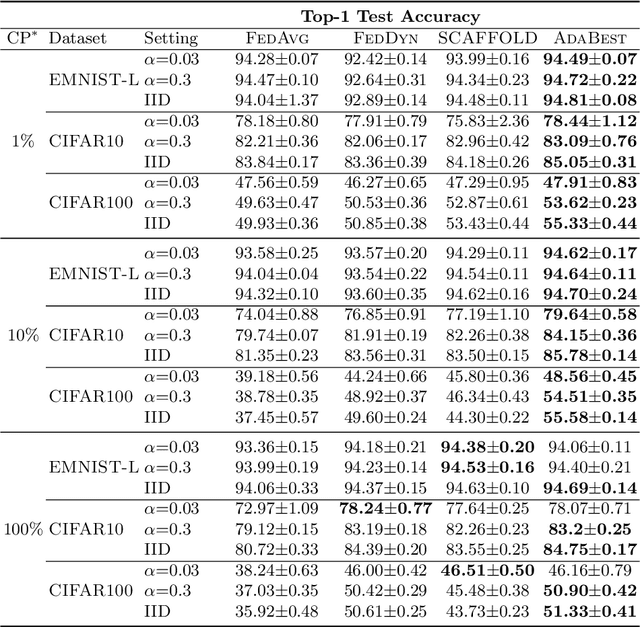
In Federated Learning a number of clients collaborate to train a model without sharing their data. Client models are optimized locally and are communicated through a central hub called server. A major challenge is to deal with heterogeneity among clients' data which causes the local optimization to drift away with respect to the global objective. In order to estimate and therefore remove this drift, variance reduction techniques have been incorporated into Federated Learning optimization recently. However, the existing solutions propagate the error of their estimations, throughout the optimization trajectory which leads to inaccurate approximations of the clients' drift and ultimately failure to remove them properly. In this paper, we address this issue by introducing an adaptive algorithm that efficiently reduces clients' drift. Compared to the previous works on adapting variance reduction to Federated Learning, our approach uses less or the same level of communication bandwidth, computation or memory. Additionally, it addresses the instability problem--prevalent in prior work, caused by increasing norm of the estimates which makes our approach a much more practical solution for large scale Federated Learning settings. Our experimental results demonstrate that the proposed algorithm converges significantly faster and achieves higher accuracy compared to the baselines in an extensive set of Federated Learning benchmarks.
Learn Faster and Forget Slower via Fast and Stable Task Adaptation
Jul 02, 2020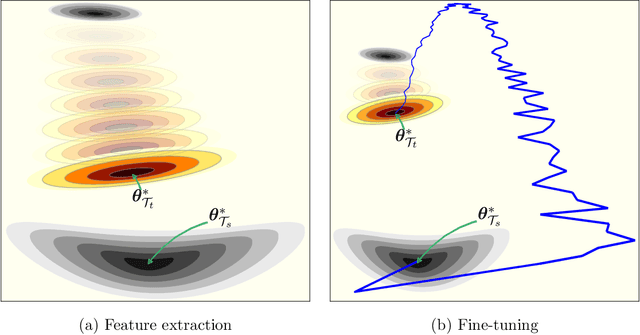

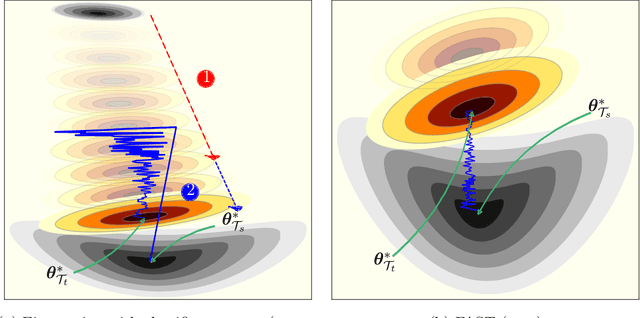
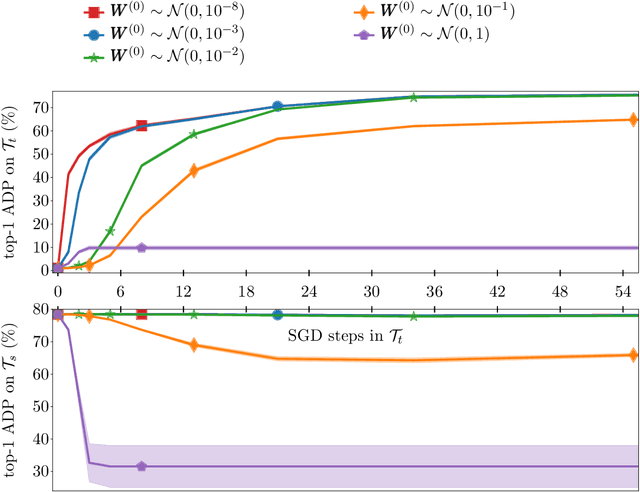
Training Deep Neural Networks (DNNs) is still highly time-consuming and compute-intensive. It has been shown that adapting a pretrained model may significantly accelerate this process. With a focus on classification, we show that current fine-tuning techniques make the pretrained models catastrophically forget the transferred knowledge even before anything about the new task is learned. Such rapid knowledge loss undermines the merits of transfer learning and may result in a much slower convergence rate compared to when the maximum amount of knowledge is exploited. We investigate the source of this problem from different perspectives and to alleviate it, introduce Fast And Stable Task-adaptation (FAST), an easy to apply fine-tuning algorithm. The paper provides a novel geometric perspective on how the loss landscape of source and target tasks are linked in different transfer learning strategies. We empirically show that compared to prevailing fine-tuning practices, FAST learns the target task faster and forgets the source task slower. The code is available at https://github.com/fvarno/FAST.
Efficient Neural Task Adaptation by Maximum Entropy Initialization
May 25, 2019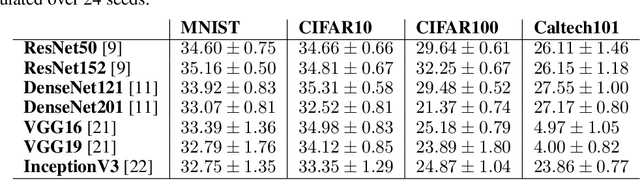
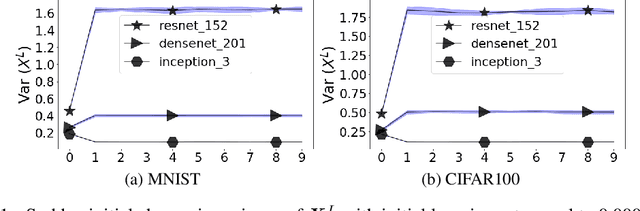
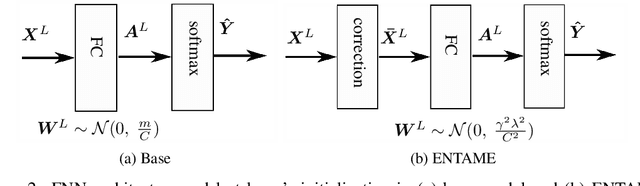
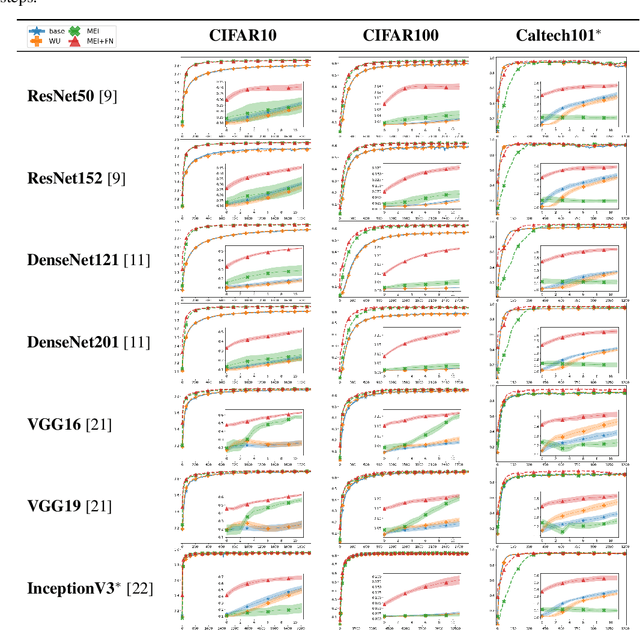
Transferring knowledge from one neural network to another has been shown to be helpful for learning tasks with few training examples. Prevailing fine-tuning methods could potentially contaminate pre-trained features by comparably high energy random noise. This noise is mainly delivered from a careless replacement of task-specific parameters. We analyze theoretically such knowledge contamination for classification tasks and propose a practical and easy to apply method to trap and minimize the contaminant. In our approach, the entropy of the output estimates gets maximized initially and the first back-propagated error is stalled at the output of the last layer. Our proposed method not only outperforms the traditional fine-tuning, but also significantly speeds up the convergence of the learner. It is robust to randomness and independent of the choice of architecture. Overall, our experiments show that the power of transfer learning has been substantially underestimated so far.