 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Deep Learning for Mental Disorders Prediction from Audio Speech Samples
Sep 12, 2019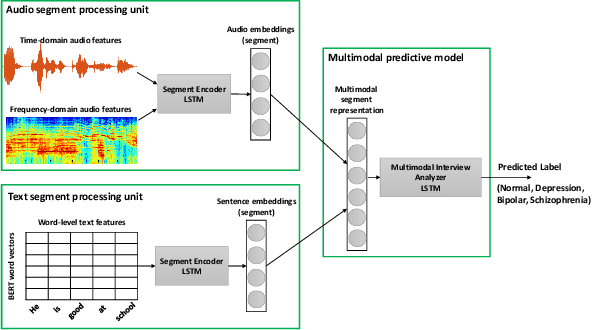
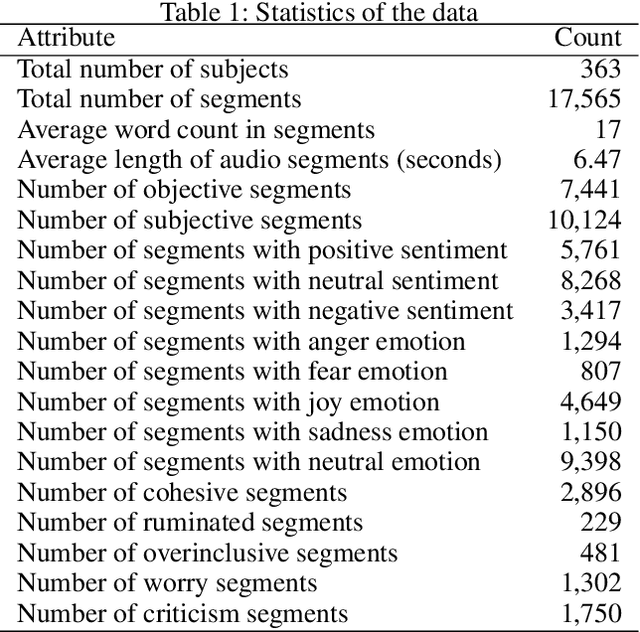
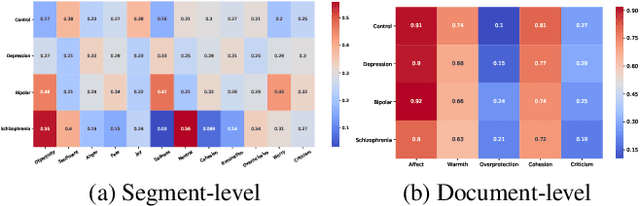
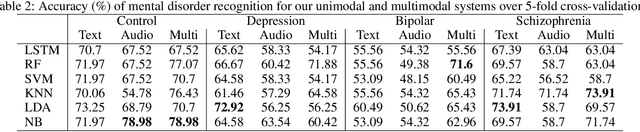
Key features of mental illnesses are reflected in speech. Our research focuses on designing a multimodal deep learning structure that automatically extracts salient features from recorded speech samples for predicting various mental disorders including depression, bipolar, and schizophrenia. We adopt a variety of pre-trained models to extract embeddings from both audio and text segments. We use several state-of-the-art embedding techniques including BERT, FastText, and Doc2VecC for the text representation learning and WaveNet and VGG-ish models for audio encoding. We also leverage huge auxiliary emotion-labeled text and audio corpora to train emotion-specific embeddings and use transfer learning in order to address the problem of insufficient annotated multimodal data available. All these embeddings are then combined into a joint representation in a multimodal fusion layer and finally a recurrent neural network is used to predict the mental disorder. Our results show that mental disorders can be predicted with acceptable accuracy through multimodal analysis of clinical interviews.
Efficient Neural Task Adaptation by Maximum Entropy Initialization
May 25, 2019
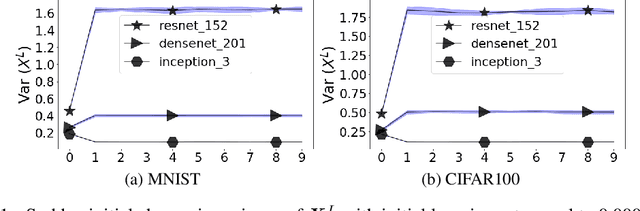
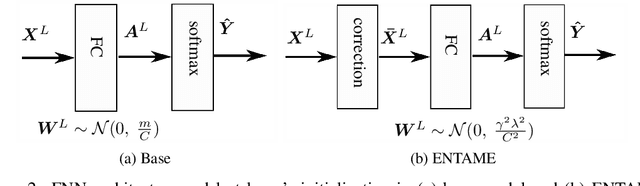
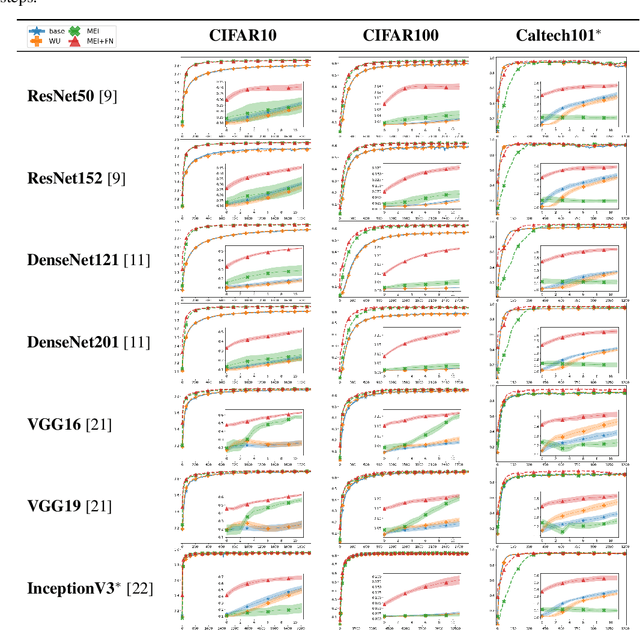
Transferring knowledge from one neural network to another has been shown to be helpful for learning tasks with few training examples. Prevailing fine-tuning methods could potentially contaminate pre-trained features by comparably high energy random noise. This noise is mainly delivered from a careless replacement of task-specific parameters. We analyze theoretically such knowledge contamination for classification tasks and propose a practical and easy to apply method to trap and minimize the contaminant. In our approach, the entropy of the output estimates gets maximized initially and the first back-propagated error is stalled at the output of the last layer. Our proposed method not only outperforms the traditional fine-tuning, but also significantly speeds up the convergence of the learner. It is robust to randomness and independent of the choice of architecture. Overall, our experiments show that the power of transfer learning has been substantially underestimated so far.