 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecision-Weighted Federated Learning
Jul 20, 2021
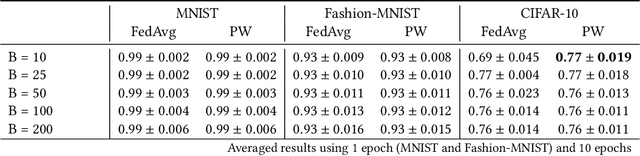

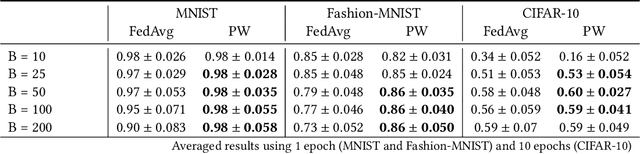
Federated Learning using the Federated Averaging algorithm has shown great advantages for large-scale applications that rely on collaborative learning, especially when the training data is either unbalanced or inaccessible due to privacy constraints. We hypothesize that Federated Averaging underestimates the full extent of heterogeneity of data when the aggregation is performed. We propose Precision-weighted Federated Learning a novel algorithm that takes into account the variance of the stochastic gradients when computing the weighted average of the parameters of models trained in a Federated Learning setting. With Precision-weighted Federated Learning, we provide an alternate averaging scheme that leverages the heterogeneity of the data when it has a large diversity of features in its composition. Our method was evaluated using standard image classification datasets with two different data partitioning strategies (IID/non-IID) to measure the performance and speed of our method in resource-constrained environments, such as mobile and IoT devices. We obtained a good balance between computational efficiency and convergence rates with Precision-weighted Federated Learning. Our performance evaluations show 9% better predictions with MNIST, 18% with Fashion-MNIST, and 5% with CIFAR-10 in the non-IID setting. Further reliability evaluations ratify the stability in our method by reaching a 99% reliability index with IID partitions and 96% with non-IID partitions. In addition, we obtained a 20x speedup on Fashion-MNIST with only 10 clients and up to 37x with 100 clients participating in the aggregation concurrently per communication round. The results indicate that Precision-weighted Federated Learning is an effective and faster alternative approach for aggregating private data, especially in domains where data is highly heterogeneous.