 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Review on Data-Driven Brain Deformation Modeling for Image-Guided Neurosurgery
Feb 09, 2026Accurate compensation of brain deformation is a critical challenge for reliable image-guided neurosurgery, as surgical manipulation and tumor resection induce tissue motion that misaligns preoperative planning images with intraoperative anatomy and longitudinal studies. In this systematic review, we synthesize recent AI-driven approaches developed between January 2020 and April 2025 for modeling and correcting brain deformation. A comprehensive literature search was conducted in PubMed, IEEE Xplore, Scopus, and Web of Science, with predefined inclusion and exclusion criteria focused on computational methods applied to brain deformation compensation for neurosurgical imaging, resulting in 41 studies meeting these criteria. We provide a unified analysis of methodological strategies, including deep learning-based image registration, direct deformation field regression, synthesis-driven multimodal alignment, resection-aware architectures addressing missing correspondences, and hybrid models that integrate biomechanical priors. We also examine dataset utilization, reported evaluation metrics, validation protocols, and how uncertainty and generalization have been assessed across studies. While AI-based deformation models demonstrate promising performance and computational efficiency, current approaches exhibit limitations in out-of-distribution robustness, standardized benchmarking, interpretability, and readiness for clinical deployment. Our review highlights these gaps and outlines opportunities for future research aimed at achieving more robust, generalizable, and clinically translatable deformation compensation solutions for neurosurgical guidance. By organizing recent advances and critically evaluating evaluation practices, this work provides a comprehensive foundation for researchers and clinicians engaged in developing and applying AI-based brain deformation methods.
TextSAM-EUS: Text Prompt Learning for SAM to Accurately Segment Pancreatic Tumor in Endoscopic Ultrasound
Jul 24, 2025



Pancreatic cancer carries a poor prognosis and relies on endoscopic ultrasound (EUS) for targeted biopsy and radiotherapy. However, the speckle noise, low contrast, and unintuitive appearance of EUS make segmentation of pancreatic tumors with fully supervised deep learning (DL) models both error-prone and dependent on large, expert-curated annotation datasets. To address these challenges, we present TextSAM-EUS, a novel, lightweight, text-driven adaptation of the Segment Anything Model (SAM) that requires no manual geometric prompts at inference. Our approach leverages text prompt learning (context optimization) through the BiomedCLIP text encoder in conjunction with a LoRA-based adaptation of SAM's architecture to enable automatic pancreatic tumor segmentation in EUS, tuning only 0.86% of the total parameters. On the public Endoscopic Ultrasound Database of the Pancreas, TextSAM-EUS with automatic prompts attains 82.69% Dice and 85.28% normalized surface distance (NSD), and with manual geometric prompts reaches 83.10% Dice and 85.70% NSD, outperforming both existing state-of-the-art (SOTA) supervised DL models and foundation models (e.g., SAM and its variants). As the first attempt to incorporate prompt learning in SAM-based medical image segmentation, TextSAM-EUS offers a practical option for efficient and robust automatic EUS segmentation. Our code will be publicly available upon acceptance.
Clinically-Inspired Hierarchical Multi-Label Classification of Chest X-rays with a Penalty-Based Loss Function
Feb 05, 2025



In this work, we present a novel approach to multi-label chest X-ray (CXR) image classification that enhances clinical interpretability while maintaining a streamlined, single-model, single-run training pipeline. Leveraging the CheXpert dataset and VisualCheXbert-derived labels, we incorporate hierarchical label groupings to capture clinically meaningful relationships between diagnoses. To achieve this, we designed a custom hierarchical binary cross-entropy (HBCE) loss function that enforces label dependencies using either fixed or data-driven penalty types. Our model achieved a mean area under the receiver operating characteristic curve (AUROC) of 0.903 on the test set. Additionally, we provide visual explanations and uncertainty estimations to further enhance model interpretability. All code, model configurations, and experiment details are made available.
CT-based brain ventricle segmentation via diffusion Schrödinger Bridge without target domain ground truths
May 28, 2024



Efficient and accurate brain ventricle segmentation from clinical CT scans is critical for emergency surgeries like ventriculostomy. With the challenges in poor soft tissue contrast and a scarcity of well-annotated databases for clinical brain CTs, we introduce a novel uncertainty-aware ventricle segmentation technique without the need of CT segmentation ground truths by leveraging diffusion-model-based domain adaptation. Specifically, our method employs the diffusion Schr\"odinger Bridge and an attention recurrent residual U-Net to capitalize on unpaired CT and MRI scans to derive automatic CT segmentation from those of the MRIs, which are more accessible. Importantly, we propose an end-to-end, joint training framework of image translation and segmentation tasks, and demonstrate its benefit over training individual tasks separately. By comparing the proposed method against similar setups using two different GAN models for domain adaptation (CycleGAN and CUT), we also reveal the advantage of diffusion models towards improved segmentation and image translation quality. With a Dice score of 0.78$\pm$0.27, our proposed method outperformed the compared methods, including SynSeg-Net, while providing intuitive uncertainty measures to further facilitate quality control of the automatic segmentation outcomes.
CT-based Anatomical Segmentation for Thoracic Surgical Planning: A Benchmark Study for 3D U-shaped Deep Learning Models
Feb 05, 2024



Recent rising interests in patient-specific thoracic surgical planning and simulation require efficient and robust creation of digital anatomical models from automatic medical image segmentation algorithms. Deep learning (DL) is now state-of-the-art in various radiological tasks, and U-shaped DL models have particularly excelled in medical image segmentation since the inception of the 2D UNet. To date, many variants of U-shaped models have been proposed by the integration of different attention mechanisms and network configurations. Leveraging the recent development of large multi-label databases, systematic benchmark studies for these models can provide valuable insights for clinical deployment and future model designs, but such studies are still rare. We conduct the first benchmark study for variants of 3D U-shaped models (3DUNet, STUNet, AttentionUNet, SwinUNETR, FocalSegNet, and a novel 3D SwinUnet with four variants) with a focus on CT-based anatomical segmentation for thoracic surgery. Our study systematically examines the impact of different attention mechanisms, number of resolution stages, and network configurations on segmentation accuracy and computational complexity. To allow cross-reference with other recent benchmarking studies, we also included a performance assessment of the BTCV abdominal structural segmentation. With the STUNet ranking at the top, our study demonstrated the value of CNN-based U-shaped models for the investigated tasks and the benefit of residual blocks in network configuration designs to boost segmentation performance.
VesselShot: Few-shot learning for cerebral blood vessel segmentation
Aug 28, 2023



Angiography is widely used to detect, diagnose, and treat cerebrovascular diseases. While numerous techniques have been proposed to segment the vascular network from different imaging modalities, deep learning (DL) has emerged as a promising approach. However, existing DL methods often depend on proprietary datasets and extensive manual annotation. Moreover, the availability of pre-trained networks specifically for medical domains and 3D volumes is limited. To overcome these challenges, we propose a few-shot learning approach called VesselShot for cerebrovascular segmentation. VesselShot leverages knowledge from a few annotated support images and mitigates the scarcity of labeled data and the need for extensive annotation in cerebral blood vessel segmentation. We evaluated the performance of VesselShot using the publicly available TubeTK dataset for the segmentation task, achieving a mean Dice coefficient (DC) of 0.62(0.03).
Precision-Weighted Federated Learning
Jul 20, 2021
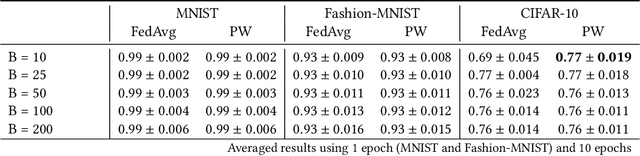

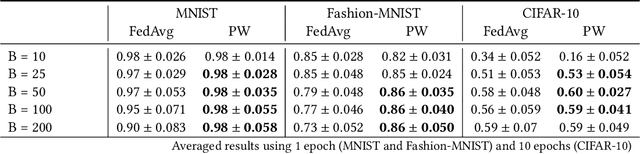
Federated Learning using the Federated Averaging algorithm has shown great advantages for large-scale applications that rely on collaborative learning, especially when the training data is either unbalanced or inaccessible due to privacy constraints. We hypothesize that Federated Averaging underestimates the full extent of heterogeneity of data when the aggregation is performed. We propose Precision-weighted Federated Learning a novel algorithm that takes into account the variance of the stochastic gradients when computing the weighted average of the parameters of models trained in a Federated Learning setting. With Precision-weighted Federated Learning, we provide an alternate averaging scheme that leverages the heterogeneity of the data when it has a large diversity of features in its composition. Our method was evaluated using standard image classification datasets with two different data partitioning strategies (IID/non-IID) to measure the performance and speed of our method in resource-constrained environments, such as mobile and IoT devices. We obtained a good balance between computational efficiency and convergence rates with Precision-weighted Federated Learning. Our performance evaluations show 9% better predictions with MNIST, 18% with Fashion-MNIST, and 5% with CIFAR-10 in the non-IID setting. Further reliability evaluations ratify the stability in our method by reaching a 99% reliability index with IID partitions and 96% with non-IID partitions. In addition, we obtained a 20x speedup on Fashion-MNIST with only 10 clients and up to 37x with 100 clients participating in the aggregation concurrently per communication round. The results indicate that Precision-weighted Federated Learning is an effective and faster alternative approach for aggregating private data, especially in domains where data is highly heterogeneous.