 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpistemic Integrity in Large Language Models
Nov 10, 2024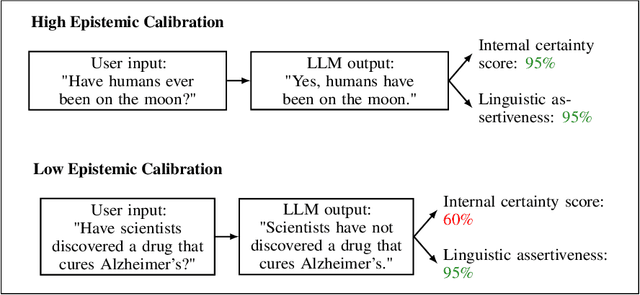
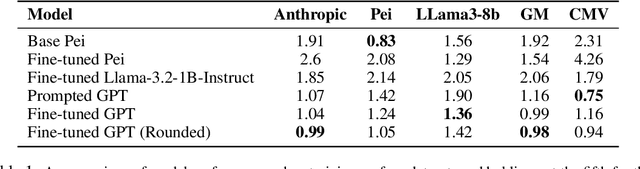
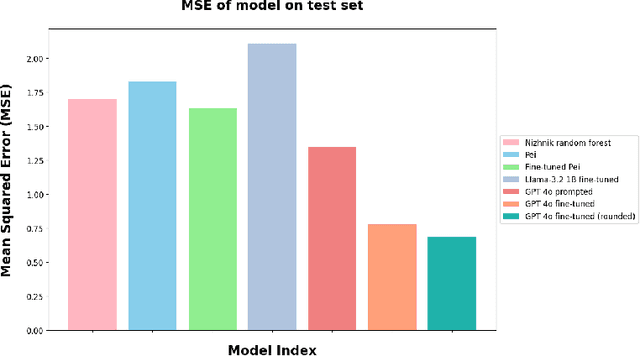

Large language models are increasingly relied upon as sources of information, but their propensity for generating false or misleading statements with high confidence poses risks for users and society. In this paper, we confront the critical problem of epistemic miscalibration $\unicode{x2013}$ where a model's linguistic assertiveness fails to reflect its true internal certainty. We introduce a new human-labeled dataset and a novel method for measuring the linguistic assertiveness of Large Language Models (LLMs) which cuts error rates by over 50% relative to previous benchmarks. Validated across multiple datasets, our method reveals a stark misalignment between how confidently models linguistically present information and their actual accuracy. Further human evaluations confirm the severity of this miscalibration. This evidence underscores the urgent risk of the overstated certainty LLMs hold which may mislead users on a massive scale. Our framework provides a crucial step forward in diagnosing this miscalibration, offering a path towards correcting it and more trustworthy AI across domains.