 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Structural Safety Generalization Problem
Apr 13, 2025LLM jailbreaks are a widespread safety challenge. Given this problem has not yet been tractable, we suggest targeting a key failure mechanism: the failure of safety to generalize across semantically equivalent inputs. We further focus the target by requiring desirable tractability properties of attacks to study: explainability, transferability between models, and transferability between goals. We perform red-teaming within this framework by uncovering new vulnerabilities to multi-turn, multi-image, and translation-based attacks. These attacks are semantically equivalent by our design to their single-turn, single-image, or untranslated counterparts, enabling systematic comparisons; we show that the different structures yield different safety outcomes. We then demonstrate the potential for this framework to enable new defenses by proposing a Structure Rewriting Guardrail, which converts an input to a structure more conducive to safety assessment. This guardrail significantly improves refusal of harmful inputs, without over-refusing benign ones. Thus, by framing this intermediate challenge - more tractable than universal defenses but essential for long-term safety - we highlight a critical milestone for AI safety research.
Emerging Vulnerabilities in Frontier Models: Multi-Turn Jailbreak Attacks
Aug 29, 2024

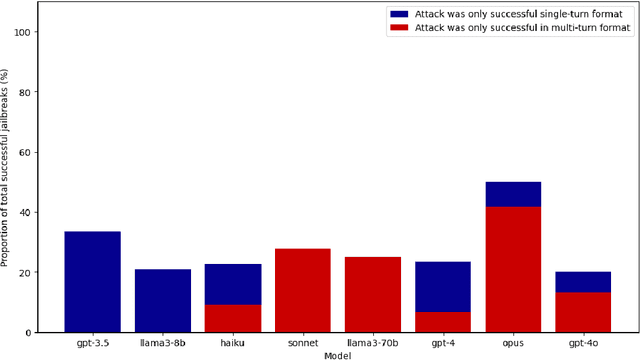

Large language models (LLMs) are improving at an exceptional rate. However, these models are still susceptible to jailbreak attacks, which are becoming increasingly dangerous as models become increasingly powerful. In this work, we introduce a dataset of jailbreaks where each example can be input in both a single or a multi-turn format. We show that while equivalent in content, they are not equivalent in jailbreak success: defending against one structure does not guarantee defense against the other. Similarly, LLM-based filter guardrails also perform differently depending on not just the input content but the input structure. Thus, vulnerabilities of frontier models should be studied in both single and multi-turn settings; this dataset provides a tool to do so.