 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Structural Safety Generalization Problem
Apr 13, 2025LLM jailbreaks are a widespread safety challenge. Given this problem has not yet been tractable, we suggest targeting a key failure mechanism: the failure of safety to generalize across semantically equivalent inputs. We further focus the target by requiring desirable tractability properties of attacks to study: explainability, transferability between models, and transferability between goals. We perform red-teaming within this framework by uncovering new vulnerabilities to multi-turn, multi-image, and translation-based attacks. These attacks are semantically equivalent by our design to their single-turn, single-image, or untranslated counterparts, enabling systematic comparisons; we show that the different structures yield different safety outcomes. We then demonstrate the potential for this framework to enable new defenses by proposing a Structure Rewriting Guardrail, which converts an input to a structure more conducive to safety assessment. This guardrail significantly improves refusal of harmful inputs, without over-refusing benign ones. Thus, by framing this intermediate challenge - more tractable than universal defenses but essential for long-term safety - we highlight a critical milestone for AI safety research.
BiMediX2: Bio-Medical EXpert LMM for Diverse Medical Modalities
Dec 10, 2024



This paper introduces BiMediX2, a bilingual (Arabic-English) Bio-Medical EXpert Large Multimodal Model (LMM) with a unified architecture that integrates text and visual modalities, enabling advanced image understanding and medical applications. BiMediX2 leverages the Llama3.1 architecture and integrates text and visual capabilities to facilitate seamless interactions in both English and Arabic, supporting text-based inputs and multi-turn conversations involving medical images. The model is trained on an extensive bilingual healthcare dataset consisting of 1.6M samples of diverse medical interactions for both text and image modalities, mixed in Arabic and English. We also propose the first bilingual GPT-4o based medical LMM benchmark named BiMed-MBench. BiMediX2 is benchmarked on both text-based and image-based tasks, achieving state-of-the-art performance across several medical benchmarks. It outperforms recent state-of-the-art models in medical LLM evaluation benchmarks. Our model also sets a new benchmark in multimodal medical evaluations with over 9% improvement in English and over 20% in Arabic evaluations. Additionally, it surpasses GPT-4 by around 9% in UPHILL factual accuracy evaluations and excels in various medical Visual Question Answering, Report Generation, and Report Summarization tasks. The project page including source code and the trained model, is available at https://github.com/mbzuai-oryx/BiMediX2.
Emerging Vulnerabilities in Frontier Models: Multi-Turn Jailbreak Attacks
Aug 29, 2024

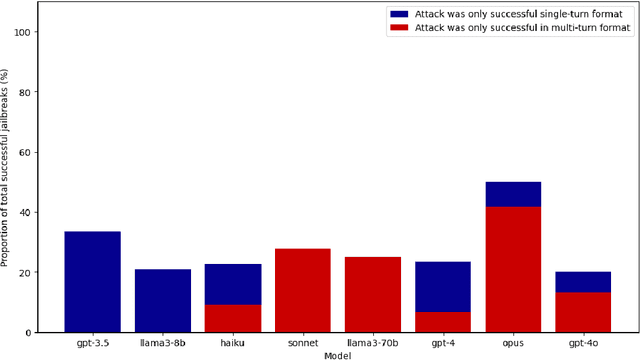

Large language models (LLMs) are improving at an exceptional rate. However, these models are still susceptible to jailbreak attacks, which are becoming increasingly dangerous as models become increasingly powerful. In this work, we introduce a dataset of jailbreaks where each example can be input in both a single or a multi-turn format. We show that while equivalent in content, they are not equivalent in jailbreak success: defending against one structure does not guarantee defense against the other. Similarly, LLM-based filter guardrails also perform differently depending on not just the input content but the input structure. Thus, vulnerabilities of frontier models should be studied in both single and multi-turn settings; this dataset provides a tool to do so.
BiMediX: Bilingual Medical Mixture of Experts LLM
Feb 20, 2024In this paper, we introduce BiMediX, the first bilingual medical mixture of experts LLM designed for seamless interaction in both English and Arabic. Our model facilitates a wide range of medical interactions in English and Arabic, including multi-turn chats to inquire about additional details such as patient symptoms and medical history, multiple-choice question answering, and open-ended question answering. We propose a semi-automated English-to-Arabic translation pipeline with human refinement to ensure high-quality translations. We also introduce a comprehensive evaluation benchmark for Arabic medical LLMs. Furthermore, we introduce BiMed1.3M, an extensive Arabic-English bilingual instruction set covering 1.3 Million diverse medical interactions, resulting in over 632 million healthcare specialized tokens for instruction tuning. Our BiMed1.3M dataset includes 250k synthesized multi-turn doctor-patient chats and maintains a 1:2 Arabic-to-English ratio. Our model outperforms state-of-the-art Med42 and Meditron by average absolute gains of 2.5% and 4.1%, respectively, computed across multiple medical evaluation benchmarks in English, while operating at 8-times faster inference. Moreover, our BiMediX outperforms the generic Arabic-English bilingual LLM, Jais-30B, by average absolute gains of 10% on our Arabic medical benchmark and 15% on bilingual evaluations across multiple datasets. Our project page with source code and trained model is available at https://github.com/mbzuai-oryx/BiMediX .
Handling Data Heterogeneity via Architectural Design for Federated Visual Recognition
Oct 23, 2023



Federated Learning (FL) is a promising research paradigm that enables the collaborative training of machine learning models among various parties without the need for sensitive information exchange. Nonetheless, retaining data in individual clients introduces fundamental challenges to achieving performance on par with centrally trained models. Our study provides an extensive review of federated learning applied to visual recognition. It underscores the critical role of thoughtful architectural design choices in achieving optimal performance, a factor often neglected in the FL literature. Many existing FL solutions are tested on shallow or simple networks, which may not accurately reflect real-world applications. This practice restricts the transferability of research findings to large-scale visual recognition models. Through an in-depth analysis of diverse cutting-edge architectures such as convolutional neural networks, transformers, and MLP-mixers, we experimentally demonstrate that architectural choices can substantially enhance FL systems' performance, particularly when handling heterogeneous data. We study 19 visual recognition models from five different architectural families on four challenging FL datasets. We also re-investigate the inferior performance of convolution-based architectures in the FL setting and analyze the influence of normalization layers on the FL performance. Our findings emphasize the importance of architectural design for computer vision tasks in practical scenarios, effectively narrowing the performance gap between federated and centralized learning. Our source code is available at https://github.com/sarapieri/fed_het.git.