 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgriChain Visually Grounded Expert Verified Reasoning for Interpretable Agricultural Vision Language Models
Apr 09, 2026Accurate and interpretable plant disease diagnosis remains a major challenge for vision-language models (VLMs) in real-world agriculture. We introduce AgriChain, a dataset of approximately 11,000 expert-curated leaf images spanning diverse crops and pathologies, each paired with (i) a disease label, (ii) a calibrated confidence score (High/Medium/Low), and (iii) an expert-verified chain-of-thought (CoT) rationale. Draft explanations were first generated by GPT-4o and then verified by a professional agricultural engineer using standardized descriptors (e.g., lesion color, margin, and distribution). We fine-tune Qwen2.5-VL-3B on AgriChain, resulting in a specialized model termed AgriChain-VL3B, to jointly predict diseases and generate visually grounded reasoning. On a 1,000-image test set, our CoT-supervised model achieves 73.1% top-1 accuracy (macro F1 = 0.466; weighted F1 = 0.655), outperforming strong baselines including Gemini 1.5 Flash, Gemini 2.5 Pro, and GPT-4o Mini. The generated explanations align closely with expert reasoning, consistently referencing key visual cues. These findings demonstrate that expert-verified reasoning supervision significantly enhances both accuracy and interpretability, bridging the gap between generic multimodal models and human expertise, and advancing trustworthy, globally deployable AI for sustainable agriculture. The dataset and code are publicly available at: https://github.com/hazzanabeel12-netizen/agrichain
* 9 pages
MediX-R1: Open Ended Medical Reinforcement Learning
Feb 26, 2026We introduce MediX-R1, an open-ended Reinforcement Learning (RL) framework for medical multimodal large language models (MLLMs) that enables clinically grounded, free-form answers beyond multiple-choice formats. MediX-R1 fine-tunes a baseline vision-language backbone with Group Based RL and a composite reward tailored for medical reasoning: an LLM-based accuracy reward that judges semantic correctness with a strict YES/NO decision, a medical embedding-based semantic reward to capture paraphrases and terminology variants, and lightweight format and modality rewards that enforce interpretable reasoning and modality recognition. This multi-signal design provides stable, informative feedback for open-ended outputs where traditional verifiable or MCQ-only rewards fall short. To measure progress, we propose a unified evaluation framework for both text-only and image+text tasks that uses a Reference-based LLM-as-judge in place of brittle string-overlap metrics, capturing semantic correctness, reasoning, and contextual alignment. Despite using only $\sim51$K instruction examples, MediX-R1 achieves excellent results across standard medical LLM (text-only) and VLM (image + text) benchmarks, outperforming strong open-source baselines and delivering particularly large gains on open-ended clinical tasks. Our results demonstrate that open-ended RL with comprehensive reward signals and LLM-based evaluation is a practical path toward reliable medical reasoning in multimodal models. Our trained models, curated datasets and source code are available at https://medix.cvmbzuai.com
Thinking Beyond Labels: Vocabulary-Free Fine-Grained Recognition using Reasoning-Augmented LMMs
Dec 21, 2025Vocabulary-free fine-grained image recognition aims to distinguish visually similar categories within a meta-class without a fixed, human-defined label set. Existing solutions for this problem are limited by either the usage of a large and rigid list of vocabularies or by the dependency on complex pipelines with fragile heuristics where errors propagate across stages. Meanwhile, the ability of recent large multi-modal models (LMMs) equipped with explicit or implicit reasoning to comprehend visual-language data, decompose problems, retrieve latent knowledge, and self-correct suggests a more principled and effective alternative. Building on these capabilities, we propose FiNDR (Fine-grained Name Discovery via Reasoning), the first reasoning-augmented LMM-based framework for vocabulary-free fine-grained recognition. The system operates in three automated steps: (i) a reasoning-enabled LMM generates descriptive candidate labels for each image; (ii) a vision-language model filters and ranks these candidates to form a coherent class set; and (iii) the verified names instantiate a lightweight multi-modal classifier used at inference time. Extensive experiments on popular fine-grained classification benchmarks demonstrate state-of-the-art performance under the vocabulary-free setting, with a significant relative margin of up to 18.8% over previous approaches. Remarkably, the proposed method surpasses zero-shot baselines that exploit pre-defined ground-truth names, challenging the assumption that human-curated vocabularies define an upper bound. Additionally, we show that carefully curated prompts enable open-source LMMs to match proprietary counterparts. These findings establish reasoning-augmented LMMs as an effective foundation for scalable, fully automated, open-world fine-grained visual recognition. The source code is available on github.com/demidovd98/FiNDR.
MATRIX: Multimodal Agent Tuning for Robust Tool-Use Reasoning
Oct 09, 2025Vision language models (VLMs) are increasingly deployed as controllers with access to external tools for complex reasoning and decision-making, yet their effectiveness remains limited by the scarcity of high-quality multimodal trajectories and the cost of manual annotation. We address this challenge with a vision-centric agent tuning framework that automatically synthesizes multimodal trajectories, generates step-wise preference pairs, and trains a VLM controller for robust tool-use reasoning. Our pipeline first constructs M-TRACE, a large-scale dataset of 28.5K multimodal tasks with 177K verified trajectories, enabling imitation-based trajectory tuning. Building on this, we develop MATRIX Agent, a controller finetuned on M-TRACE for step-wise tool reasoning. To achieve finer alignment, we further introduce Pref-X, a set of 11K automatically generated preference pairs, and optimize MATRIX on it via step-wise preference learning. Across three benchmarks, Agent-X, GTA, and GAIA, MATRIX consistently surpasses both open- and closed-source VLMs, demonstrating scalable and effective multimodal tool use. Our data and code is avaliable at https://github.com/mbzuai-oryx/MATRIX.
How Good are Foundation Models in Step-by-Step Embodied Reasoning?
Sep 18, 2025
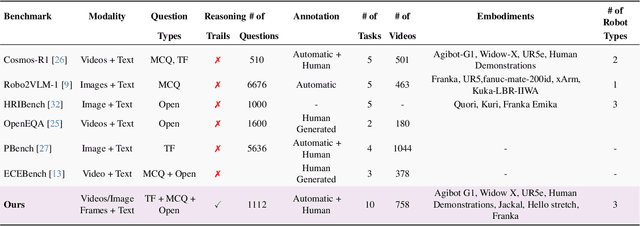
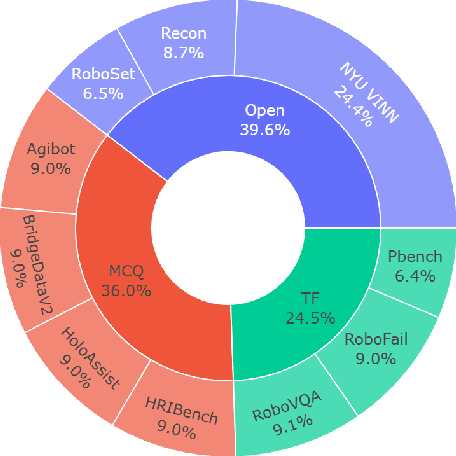

Embodied agents operating in the physical world must make decisions that are not only effective but also safe, spatially coherent, and grounded in context. While recent advances in large multimodal models (LMMs) have shown promising capabilities in visual understanding and language generation, their ability to perform structured reasoning for real-world embodied tasks remains underexplored. In this work, we aim to understand how well foundation models can perform step-by-step reasoning in embodied environments. To this end, we propose the Foundation Model Embodied Reasoning (FoMER) benchmark, designed to evaluate the reasoning capabilities of LMMs in complex embodied decision-making scenarios. Our benchmark spans a diverse set of tasks that require agents to interpret multimodal observations, reason about physical constraints and safety, and generate valid next actions in natural language. We present (i) a large-scale, curated suite of embodied reasoning tasks, (ii) a novel evaluation framework that disentangles perceptual grounding from action reasoning, and (iii) empirical analysis of several leading LMMs under this setting. Our benchmark includes over 1.1k samples with detailed step-by-step reasoning across 10 tasks and 8 embodiments, covering three different robot types. Our results highlight both the potential and current limitations of LMMs in embodied reasoning, pointing towards key challenges and opportunities for future research in robot intelligence. Our data and code will be made publicly available.
BiMediX2: Bio-Medical EXpert LMM for Diverse Medical Modalities
Dec 10, 2024



This paper introduces BiMediX2, a bilingual (Arabic-English) Bio-Medical EXpert Large Multimodal Model (LMM) with a unified architecture that integrates text and visual modalities, enabling advanced image understanding and medical applications. BiMediX2 leverages the Llama3.1 architecture and integrates text and visual capabilities to facilitate seamless interactions in both English and Arabic, supporting text-based inputs and multi-turn conversations involving medical images. The model is trained on an extensive bilingual healthcare dataset consisting of 1.6M samples of diverse medical interactions for both text and image modalities, mixed in Arabic and English. We also propose the first bilingual GPT-4o based medical LMM benchmark named BiMed-MBench. BiMediX2 is benchmarked on both text-based and image-based tasks, achieving state-of-the-art performance across several medical benchmarks. It outperforms recent state-of-the-art models in medical LLM evaluation benchmarks. Our model also sets a new benchmark in multimodal medical evaluations with over 9% improvement in English and over 20% in Arabic evaluations. Additionally, it surpasses GPT-4 by around 9% in UPHILL factual accuracy evaluations and excels in various medical Visual Question Answering, Report Generation, and Report Summarization tasks. The project page including source code and the trained model, is available at https://github.com/mbzuai-oryx/BiMediX2.
CONDA: Condensed Deep Association Learning for Co-Salient Object Detection
Sep 04, 2024
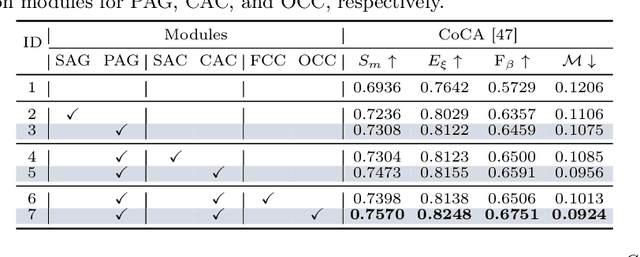
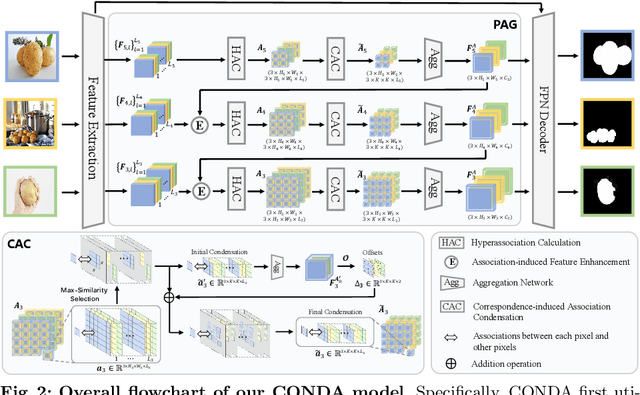
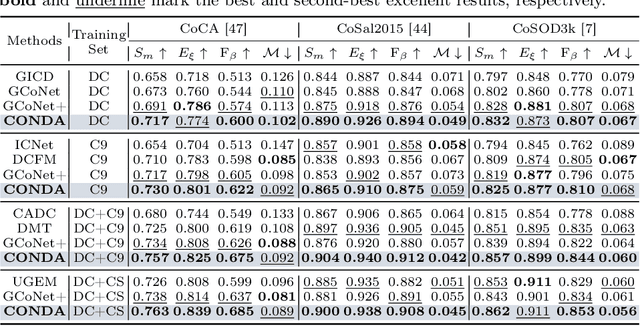
Inter-image association modeling is crucial for co-salient object detection. Despite satisfactory performance, previous methods still have limitations on sufficient inter-image association modeling. Because most of them focus on image feature optimization under the guidance of heuristically calculated raw inter-image associations. They directly rely on raw associations which are not reliable in complex scenarios, and their image feature optimization approach is not explicit for inter-image association modeling. To alleviate these limitations, this paper proposes a deep association learning strategy that deploys deep networks on raw associations to explicitly transform them into deep association features. Specifically, we first create hyperassociations to collect dense pixel-pair-wise raw associations and then deploys deep aggregation networks on them. We design a progressive association generation module for this purpose with additional enhancement of the hyperassociation calculation. More importantly, we propose a correspondence-induced association condensation module that introduces a pretext task, i.e. semantic correspondence estimation, to condense the hyperassociations for computational burden reduction and noise elimination. We also design an object-aware cycle consistency loss for high-quality correspondence estimations. Experimental results in three benchmark datasets demonstrate the remarkable effectiveness of our proposed method with various training settings.
* There is an error. In Sec 4.1, the number of images in some dataset is incorrect and needs to be revised
Surface-biased Multi-Level Context 3D Object Detection
Feb 13, 2023



Object detection in 3D point clouds is a crucial task in a range of computer vision applications including robotics, autonomous cars, and augmented reality. This work addresses the object detection task in 3D point clouds using a highly efficient, surface-biased, feature extraction method (wang2022rbgnet), that also captures contextual cues on multiple levels. We propose a 3D object detector that extracts accurate feature representations of object candidates and leverages self-attention on point patches, object candidates, and on the global scene in 3D scene. Self-attention is proven to be effective in encoding correlation information in 3D point clouds by (xie2020mlcvnet). While other 3D detectors focus on enhancing point cloud feature extraction by selectively obtaining more meaningful local features (wang2022rbgnet) where contextual information is overlooked. To this end, the proposed architecture uses ray-based surface-biased feature extraction and multi-level context encoding to outperform the state-of-the-art 3D object detector. In this work, 3D detection experiments are performed on scenes from the ScanNet dataset whereby the self-attention modules are introduced one after the other to isolate the effect of self-attention at each level.
On the Robustness of 3D Object Detectors
Jul 20, 2022


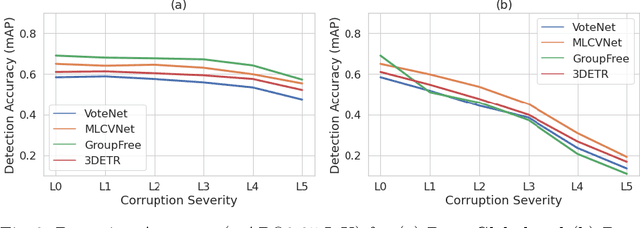
In recent years, significant progress has been achieved for 3D object detection on point clouds thanks to the advances in 3D data collection and deep learning techniques. Nevertheless, 3D scenes exhibit a lot of variations and are prone to sensor inaccuracies as well as information loss during pre-processing. Thus, it is crucial to design techniques that are robust against these variations. This requires a detailed analysis and understanding of the effect of such variations. This work aims to analyze and benchmark popular point-based 3D object detectors against several data corruptions. To the best of our knowledge, we are the first to investigate the robustness of point-based 3D object detectors. To this end, we design and evaluate corruptions that involve data addition, reduction, and alteration. We further study the robustness of different modules against local and global variations. Our experimental results reveal several intriguing findings. For instance, we show that methods that integrate Transformers at a patch or object level lead to increased robustness, compared to using Transformers at the point level.