 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Text from Uniform Meaning Representation
Paper and Code
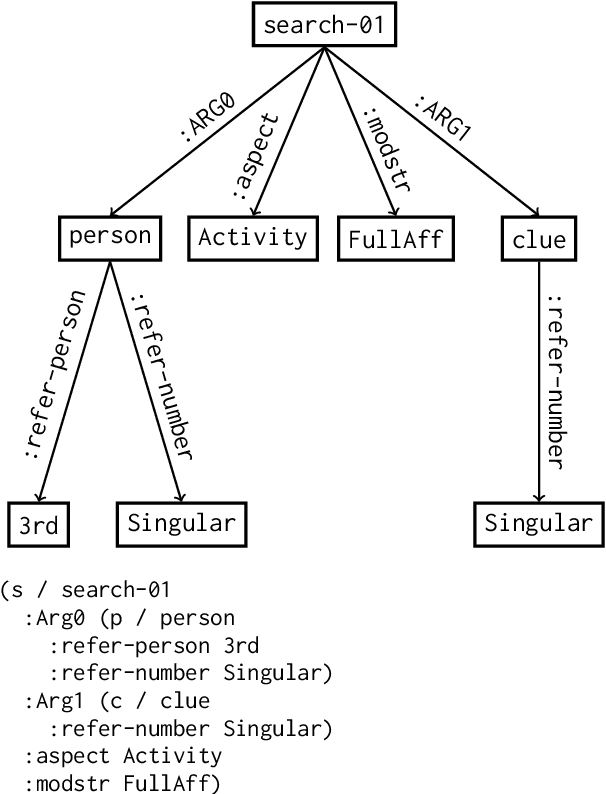
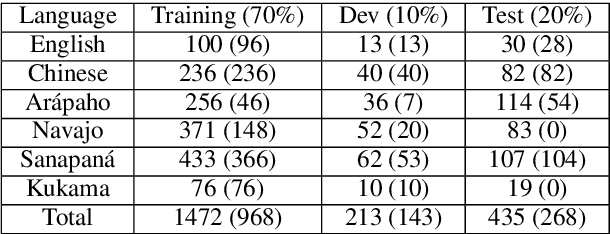

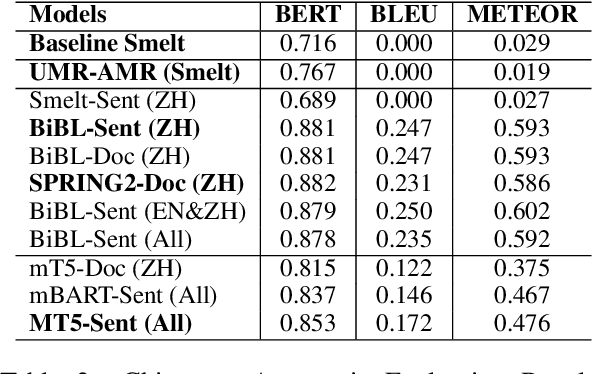
Uniform Meaning Representation (UMR) is a recently developed graph-based semantic representation, which expands on Abstract Meaning Representation (AMR) in a number of ways, in particular through the inclusion of document-level information and multilingual flexibility. In order to effectively adopt and leverage UMR for downstream tasks, efforts must be placed toward developing a UMR technological ecosystem. Though still limited amounts of UMR annotations have been produced to date, in this work, we investigate the first approaches to producing text from multilingual UMR graphs: (1) a pipeline conversion of UMR to AMR, then using AMR-to-text generation models, (2) fine-tuning large language models with UMR data, and (3) fine-tuning existing AMR-to-text generation models with UMR data. Our best performing model achieves a multilingual BERTscore of 0.825 for English and 0.882 for Chinese when compared to the reference, which is a promising indication of the effectiveness of fine-tuning approaches for UMR-to-text generation with even limited amounts of UMR data.