 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFRS: Resource-efficient Federated Recommender System for Dynamic and Diversified User Preferences
Jul 28, 2022
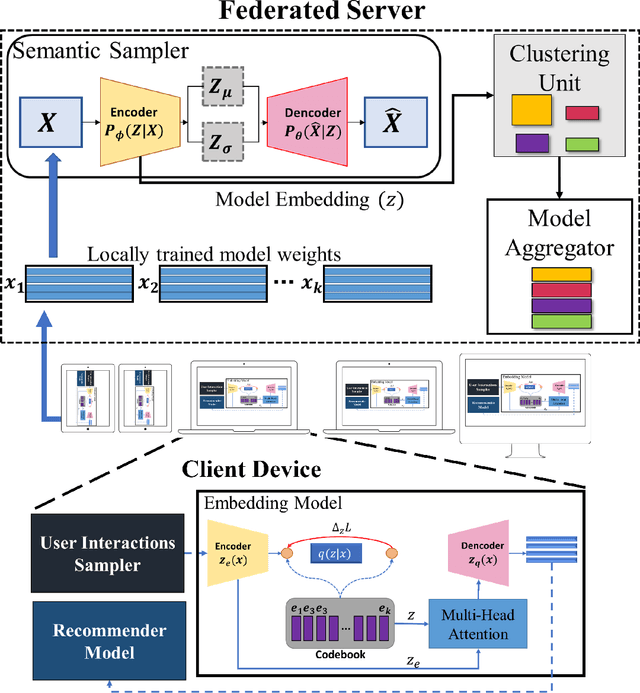
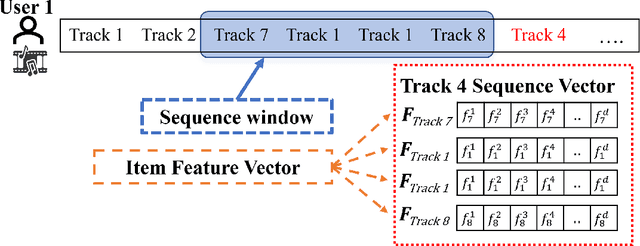

Owing to its nature of scalability and privacy by design, federated learning (FL) has received increasing interest in decentralized deep learning. FL has also facilitated recent research on upscaling and privatizing personalized recommendation services, using on-device data to learn recommender models locally. These models are then aggregated globally to obtain a more performant model, while maintaining data privacy. Typically, federated recommender systems (FRSs) do not consider the lack of resources and data availability at the end-devices. In addition, they assume that the interaction data between users and items is i.i.d. and stationary across end-devices, and that all local recommender models can be directly averaged without considering the user's behavioral diversity. However, in real scenarios, recommendations have to be made on end-devices with sparse interaction data and limited resources. Furthermore, users' preferences are heterogeneous and they frequently visit new items. This makes their personal preferences highly skewed, and the straightforwardly aggregated model is thus ill-posed for such non-i.i.d. data. In this paper, we propose Resource Efficient Federated Recommender System (ReFRS) to enable decentralized recommendation with dynamic and diversified user preferences. On the device side, ReFRS consists of a lightweight self-supervised local model built upon the variational autoencoder for learning a user's temporal preference from a sequence of interacted items. On the server side, ReFRS utilizes a semantic sampler to adaptively perform model aggregation within each identified user cluster. The clustering module operates in an asynchronous and dynamic manner to support efficient global model update and cope with shifting user interests. As a result, ReFRS achieves superior performance in terms of both accuracy and scalability, as demonstrated by comparative experiments.
DeHIN: A Decentralized Framework for Embedding Large-scale Heterogeneous Information Networks
Jan 08, 2022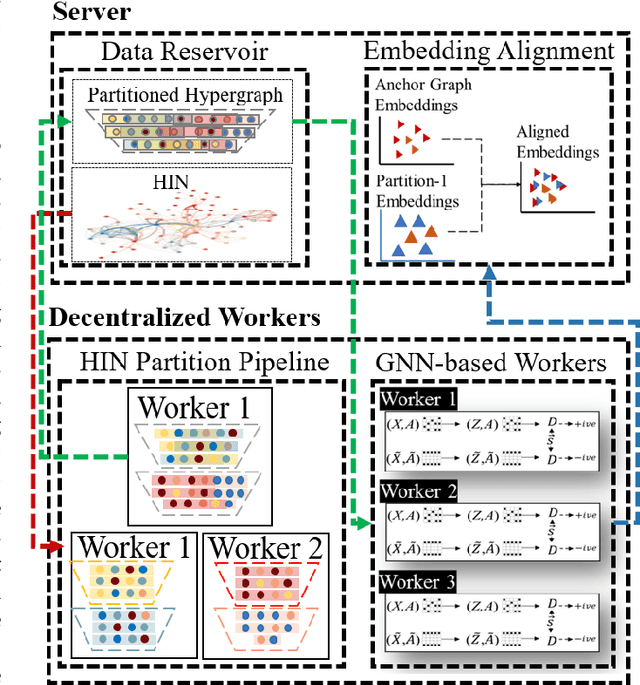


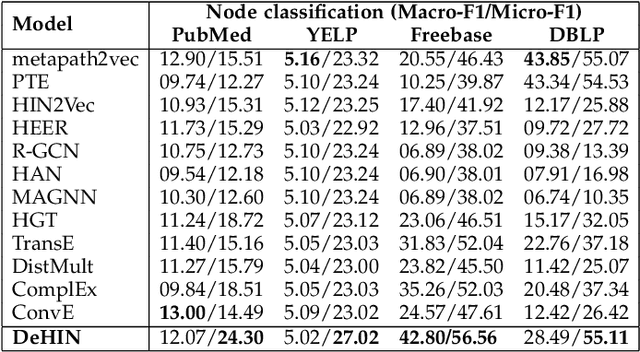
Modeling heterogeneity by extraction and exploitation of high-order information from heterogeneous information networks (HINs) has been attracting immense research attention in recent times. Such heterogeneous network embedding (HNE) methods effectively harness the heterogeneity of small-scale HINs. However, in the real world, the size of HINs grow exponentially with the continuous introduction of new nodes and different types of links, making it a billion-scale network. Learning node embeddings on such HINs creates a performance bottleneck for existing HNE methods that are commonly centralized, i.e., complete data and the model are both on a single machine. To address large-scale HNE tasks with strong efficiency and effectiveness guarantee, we present \textit{Decentralized Embedding Framework for Heterogeneous Information Network} (DeHIN) in this paper. In DeHIN, we generate a distributed parallel pipeline that utilizes hypergraphs in order to infuse parallelization into the HNE task. DeHIN presents a context preserving partition mechanism that innovatively formulates a large HIN as a hypergraph, whose hyperedges connect semantically similar nodes. Our framework then adopts a decentralized strategy to efficiently partition HINs by adopting a tree-like pipeline. Then, each resulting subnetwork is assigned to a distributed worker, which employs the deep information maximization theorem to locally learn node embeddings from the partition it receives. We further devise a novel embedding alignment scheme to precisely project independently learned node embeddings from all subnetworks onto a common vector space, thus allowing for downstream tasks like link prediction and node classification.