Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleBERT: Chinese pretraining by font style information
Paper and Code

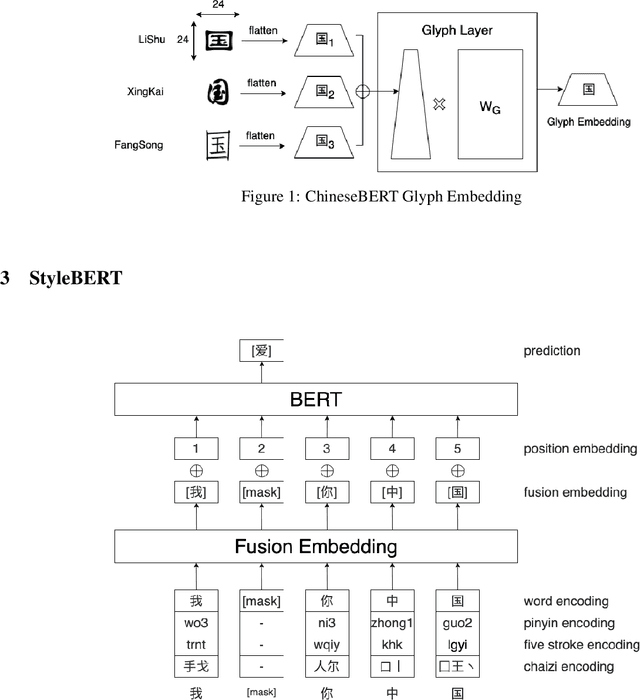

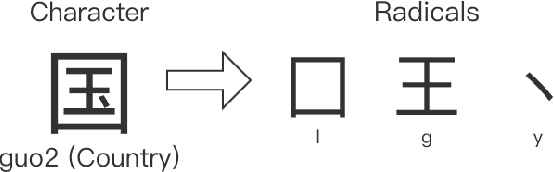
With the success of down streaming task using English pre-trained language model, the pre-trained Chinese language model is also necessary to get a better performance of Chinese NLP task. Unlike the English language, Chinese has its special characters such as glyph information. So in this article, we propose the Chinese pre-trained language model StyleBERT which incorporate the following embedding information to enhance the savvy of language model, such as word, pinyin, five stroke and chaizi. The experiments show that the model achieves well performances on a wide range of Chinese NLP tasks.
View paper on