 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\text{M}^{2}$LLM: Multi-view Molecular Representation Learning with Large Language Models
Aug 12, 2025Accurate molecular property prediction is a critical challenge with wide-ranging applications in chemistry, materials science, and drug discovery. Molecular representation methods, including fingerprints and graph neural networks (GNNs), achieve state-of-the-art results by effectively deriving features from molecular structures. However, these methods often overlook decades of accumulated semantic and contextual knowledge. Recent advancements in large language models (LLMs) demonstrate remarkable reasoning abilities and prior knowledge across scientific domains, leading us to hypothesize that LLMs can generate rich molecular representations when guided to reason in multiple perspectives. To address these gaps, we propose $\text{M}^{2}$LLM, a multi-view framework that integrates three perspectives: the molecular structure view, the molecular task view, and the molecular rules view. These views are fused dynamically to adapt to task requirements, and experiments demonstrate that $\text{M}^{2}$LLM achieves state-of-the-art performance on multiple benchmarks across classification and regression tasks. Moreover, we demonstrate that representation derived from LLM achieves exceptional performance by leveraging two core functionalities: the generation of molecular embeddings through their encoding capabilities and the curation of molecular features through advanced reasoning processes.
Large Language Models for Scientific Synthesis, Inference and Explanation
Oct 12, 2023Large language models are a form of artificial intelligence systems whose primary knowledge consists of the statistical patterns, semantic relationships, and syntactical structures of language1. Despite their limited forms of "knowledge", these systems are adept at numerous complex tasks including creative writing, storytelling, translation, question-answering, summarization, and computer code generation. However, they have yet to demonstrate advanced applications in natural science. Here we show how large language models can perform scientific synthesis, inference, and explanation. We present a method for using general-purpose large language models to make inferences from scientific datasets of the form usually associated with special-purpose machine learning algorithms. We show that the large language model can augment this "knowledge" by synthesizing from the scientific literature. When a conventional machine learning system is augmented with this synthesized and inferred knowledge it can outperform the current state of the art across a range of benchmark tasks for predicting molecular properties. This approach has the further advantage that the large language model can explain the machine learning system's predictions. We anticipate that our framework will open new avenues for AI to accelerate the pace of scientific discovery.
ChatRule: Mining Logical Rules with Large Language Models for Knowledge Graph Reasoning
Sep 13, 2023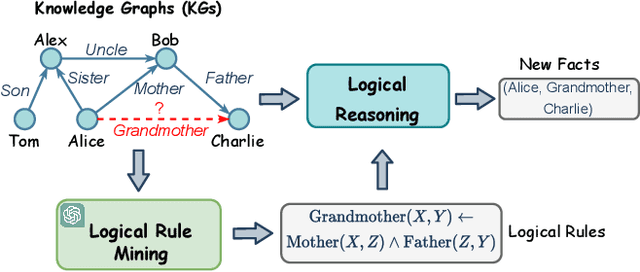

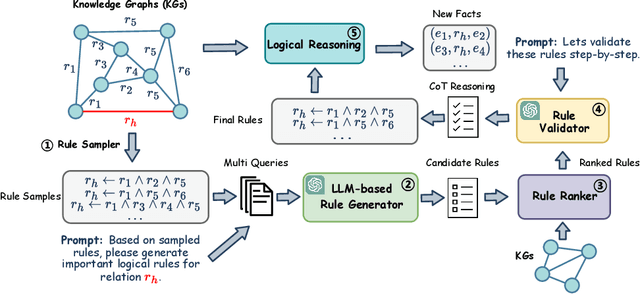

Logical rules are essential for uncovering the logical connections between relations, which could improve the reasoning performance and provide interpretable results on knowledge graphs (KGs). Although there have been many efforts to mine meaningful logical rules over KGs, existing methods suffer from the computationally intensive searches over the rule space and a lack of scalability for large-scale KGs. Besides, they often ignore the semantics of relations which is crucial for uncovering logical connections. Recently, large language models (LLMs) have shown impressive performance in the field of natural language processing and various applications, owing to their emergent ability and generalizability. In this paper, we propose a novel framework, ChatRule, unleashing the power of large language models for mining logical rules over knowledge graphs. Specifically, the framework is initiated with an LLM-based rule generator, leveraging both the semantic and structural information of KGs to prompt LLMs to generate logical rules. To refine the generated rules, a rule ranking module estimates the rule quality by incorporating facts from existing KGs. Last, a rule validator harnesses the reasoning ability of LLMs to validate the logical correctness of ranked rules through chain-of-thought reasoning. ChatRule is evaluated on four large-scale KGs, w.r.t. different rule quality metrics and downstream tasks, showing the effectiveness and scalability of our method.
How Far are We from Robust Long Abstractive Summarization?
Oct 30, 2022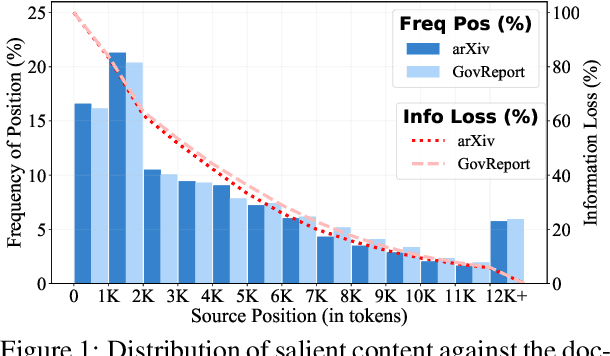
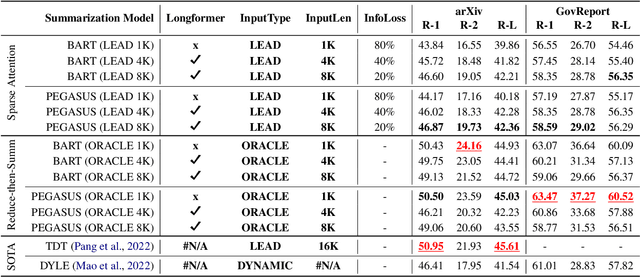
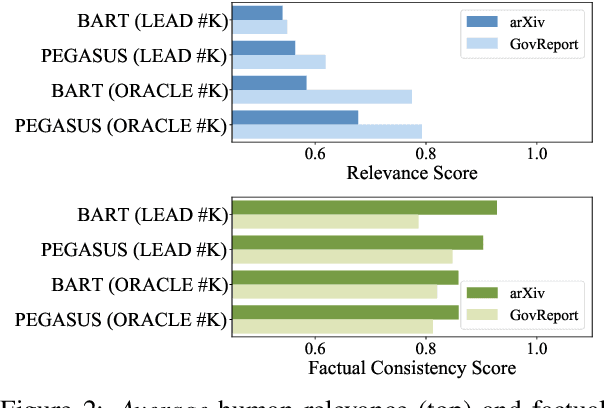
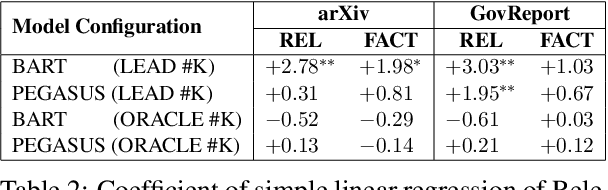
Abstractive summarization has made tremendous progress in recent years. In this work, we perform fine-grained human annotations to evaluate long document abstractive summarization systems (i.e., models and metrics) with the aim of implementing them to generate reliable summaries. For long document abstractive models, we show that the constant strive for state-of-the-art ROUGE results can lead us to generate more relevant summaries but not factual ones. For long document evaluation metrics, human evaluation results show that ROUGE remains the best at evaluating the relevancy of a summary. It also reveals important limitations of factuality metrics in detecting different types of factual errors and the reasons behind the effectiveness of BARTScore. We then suggest promising directions in the endeavor of developing factual consistency metrics. Finally, we release our annotated long document dataset with the hope that it can contribute to the development of metrics across a broader range of summarization settings.
An Empirical Survey on Long Document Summarization: Datasets, Models and Metrics
Jul 03, 2022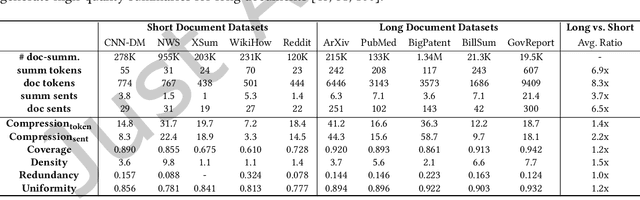
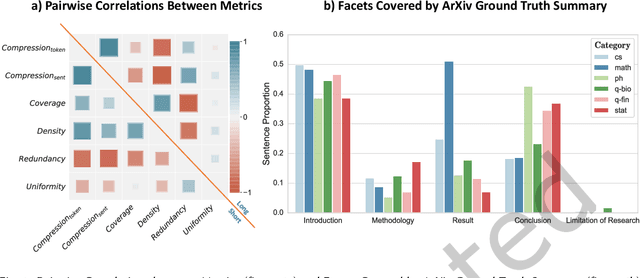
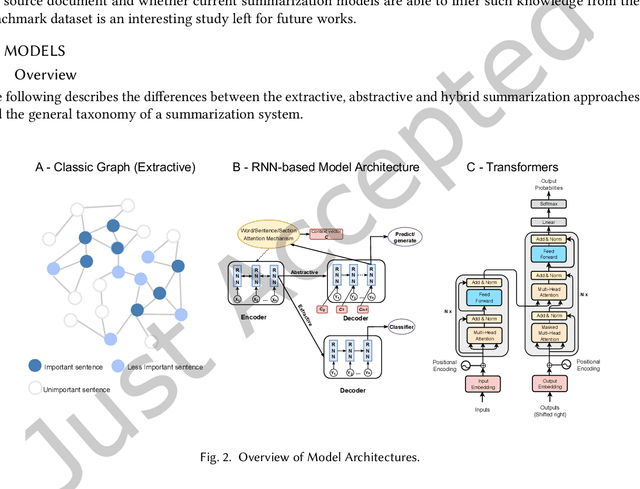
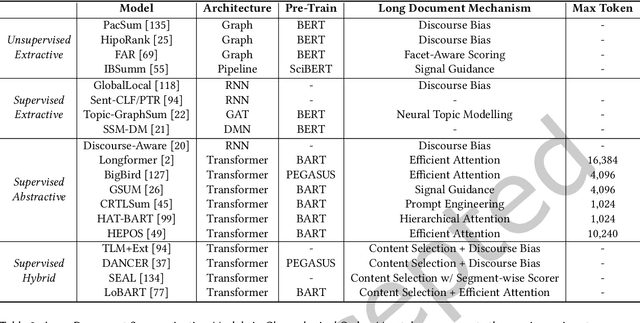
Long documents such as academic articles and business reports have been the standard format to detail out important issues and complicated subjects that require extra attention. An automatic summarization system that can effectively condense long documents into short and concise texts to encapsulate the most important information would thus be significant in aiding the reader's comprehension. Recently, with the advent of neural architectures, significant research efforts have been made to advance automatic text summarization systems, and numerous studies on the challenges of extending these systems to the long document domain have emerged. In this survey, we provide a comprehensive overview of the research on long document summarization and a systematic evaluation across the three principal components of its research setting: benchmark datasets, summarization models, and evaluation metrics. For each component, we organize the literature within the context of long document summarization and conduct an empirical analysis to broaden the perspective on current research progress. The empirical analysis includes a study on the intrinsic characteristics of benchmark datasets, a multi-dimensional analysis of summarization models, and a review of the summarization evaluation metrics. Based on the overall findings, we conclude by proposing possible directions for future exploration in this rapidly growing field.
Leveraging Information Bottleneck for Scientific Document Summarization
Oct 04, 2021
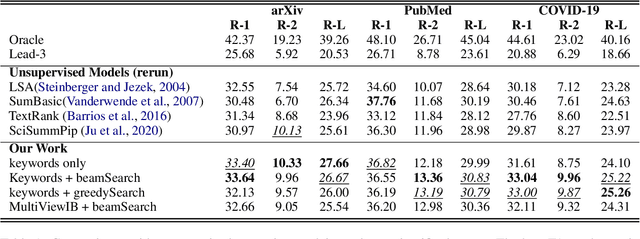
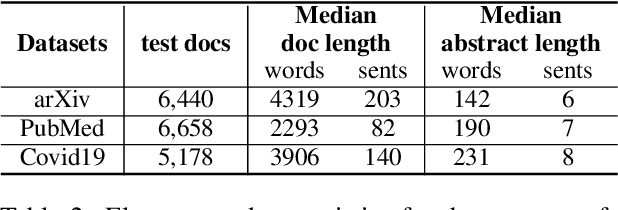
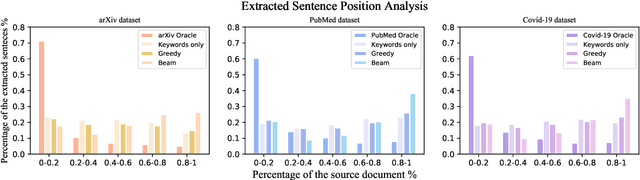
This paper presents an unsupervised extractive approach to summarize scientific long documents based on the Information Bottleneck principle. Inspired by previous work which uses the Information Bottleneck principle for sentence compression, we extend it to document level summarization with two separate steps. In the first step, we use signal(s) as queries to retrieve the key content from the source document. Then, a pre-trained language model conducts further sentence search and edit to return the final extracted summaries. Importantly, our work can be flexibly extended to a multi-view framework by different signals. Automatic evaluation on three scientific document datasets verifies the effectiveness of the proposed framework. The further human evaluation suggests that the extracted summaries cover more content aspects than previous systems.
SciSummPip: An Unsupervised Scientific Paper Summarization Pipeline
Oct 19, 2020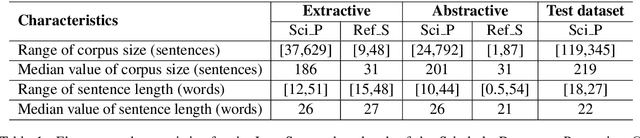
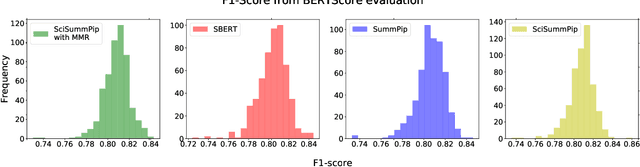
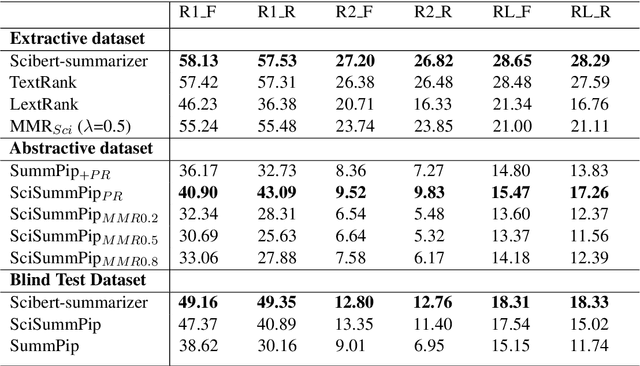

The Scholarly Document Processing (SDP) workshop is to encourage more efforts on natural language understanding of scientific task. It contains three shared tasks and we participate in the LongSumm shared task. In this paper, we describe our text summarization system, SciSummPip, inspired by SummPip (Zhao et al., 2020) that is an unsupervised text summarization system for multi-document in news domain. Our SciSummPip includes a transformer-based language model SciBERT (Beltagy et al., 2019) for contextual sentence representation, content selection with PageRank (Page et al., 1999), sentence graph construction with both deep and linguistic information, sentence graph clustering and within-graph summary generation. Our work differs from previous method in that content selection and a summary length constraint is applied to adapt to the scientific domain. The experiment results on both training dataset and blind test dataset show the effectiveness of our method, and we empirically verify the robustness of modules used in SciSummPip with BERTScore (Zhang et al., 2019a).