 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Subtle to Significant: Prompt-Driven Self-Improving Optimization in Test-Time Graph OOD Detection
Feb 19, 2026Graph Out-of-Distribution (OOD) detection aims to identify whether a test graph deviates from the distribution of graphs observed during training, which is critical for ensuring the reliability of Graph Neural Networks (GNNs) when deployed in open-world scenarios. Recent advances in graph OOD detection have focused on test-time training techniques that facilitate OOD detection without accessing potential supervisory information (e.g., training data). However, most of these methods employ a one-pass inference paradigm, which prevents them from progressively correcting erroneous predictions to amplify OOD signals. To this end, we propose a \textbf{S}elf-\textbf{I}mproving \textbf{G}raph \textbf{O}ut-\textbf{o}f-\textbf{D}istribution detector (SIGOOD), which is an unsupervised framework that integrates continuous self-learning with test-time training for effective graph OOD detection. Specifically, SIGOOD generates a prompt to construct a prompt-enhanced graph that amplifies potential OOD signals. To optimize prompts, SIGOOD introduces an Energy Preference Optimization (EPO) loss, which leverages energy variations between the original test graph and the prompt-enhanced graph. By iteratively optimizing the prompt by involving it into the detection model in a self-improving loop, the resulting optimal prompt-enhanced graph is ultimately used for OOD detection. Comprehensive evaluations on 21 real-world datasets confirm the effectiveness and outperformance of our SIGOOD method. The code is at https://github.com/Ee1s/SIGOOD.
GOODAT: Towards Test-time Graph Out-of-Distribution Detection
Jan 10, 2024Graph neural networks (GNNs) have found widespread application in modeling graph data across diverse domains. While GNNs excel in scenarios where the testing data shares the distribution of their training counterparts (in distribution, ID), they often exhibit incorrect predictions when confronted with samples from an unfamiliar distribution (out-of-distribution, OOD). To identify and reject OOD samples with GNNs, recent studies have explored graph OOD detection, often focusing on training a specific model or modifying the data on top of a well-trained GNN. Despite their effectiveness, these methods come with heavy training resources and costs, as they need to optimize the GNN-based models on training data. Moreover, their reliance on modifying the original GNNs and accessing training data further restricts their universality. To this end, this paper introduces a method to detect Graph Out-of-Distribution At Test-time (namely GOODAT), a data-centric, unsupervised, and plug-and-play solution that operates independently of training data and modifications of GNN architecture. With a lightweight graph masker, GOODAT can learn informative subgraphs from test samples, enabling the capture of distinct graph patterns between OOD and ID samples. To optimize the graph masker, we meticulously design three unsupervised objective functions based on the graph information bottleneck principle, motivating the masker to capture compact yet informative subgraphs for OOD detection. Comprehensive evaluations confirm that our GOODAT method outperforms state-of-the-art benchmarks across a variety of real-world datasets. The code is available at Github: https://github.com/Ee1s/GOODAT
A Survey on Fairness-aware Recommender Systems
Jun 01, 2023



As information filtering services, recommender systems have extremely enriched our daily life by providing personalized suggestions and facilitating people in decision-making, which makes them vital and indispensable to human society in the information era. However, as people become more dependent on them, recent studies show that recommender systems potentially own unintentional impacts on society and individuals because of their unfairness (e.g., gender discrimination in job recommendations). To develop trustworthy services, it is crucial to devise fairness-aware recommender systems that can mitigate these bias issues. In this survey, we summarise existing methodologies and practices of fairness in recommender systems. Firstly, we present concepts of fairness in different recommendation scenarios, comprehensively categorize current advances, and introduce typical methods to promote fairness in different stages of recommender systems. Next, after introducing datasets and evaluation metrics applied to assess the fairness of recommender systems, we will delve into the significant influence that fairness-aware recommender systems exert on real-world industrial applications. Subsequently, we highlight the connection between fairness and other principles of trustworthy recommender systems, aiming to consider trustworthiness principles holistically while advocating for fairness. Finally, we summarize this review, spotlighting promising opportunities in comprehending concepts, frameworks, the balance between accuracy and fairness, and the ties with trustworthiness, with the ultimate goal of fostering the development of fairness-aware recommender systems.
Dual Intent Enhanced Graph Neural Network for Session-based New Item Recommendation
May 10, 2023Recommender systems are essential to various fields, e.g., e-commerce, e-learning, and streaming media. At present, graph neural networks (GNNs) for session-based recommendations normally can only recommend items existing in users' historical sessions. As a result, these GNNs have difficulty recommending items that users have never interacted with (new items), which leads to a phenomenon of information cocoon. Therefore, it is necessary to recommend new items to users. As there is no interaction between new items and users, we cannot include new items when building session graphs for GNN session-based recommender systems. Thus, it is challenging to recommend new items for users when using GNN-based methods. We regard this challenge as '\textbf{G}NN \textbf{S}ession-based \textbf{N}ew \textbf{I}tem \textbf{R}ecommendation (GSNIR)'. To solve this problem, we propose a dual-intent enhanced graph neural network for it. Due to the fact that new items are not tied to historical sessions, the users' intent is difficult to predict. We design a dual-intent network to learn user intent from an attention mechanism and the distribution of historical data respectively, which can simulate users' decision-making process in interacting with a new item. To solve the challenge that new items cannot be learned by GNNs, inspired by zero-shot learning (ZSL), we infer the new item representation in GNN space by using their attributes. By outputting new item probabilities, which contain recommendation scores of the corresponding items, the new items with higher scores are recommended to users. Experiments on two representative real-world datasets show the superiority of our proposed method. The case study from the real-world verifies interpretability benefits brought by the dual-intent module and the new item reasoning module. The code is available at Github: https://github.com/Ee1s/NirGNN
CGMN: A Contrastive Graph Matching Network for Self-Supervised Graph Similarity Learning
May 30, 2022
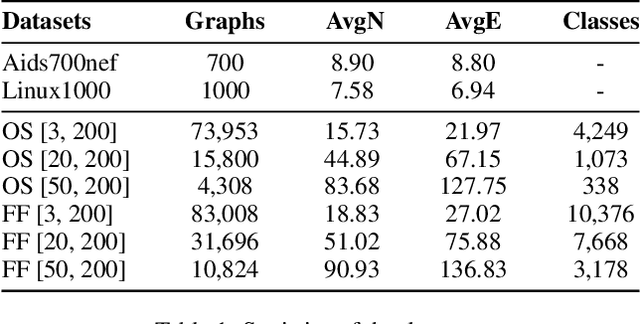


Graph similarity learning refers to calculating the similarity score between two graphs, which is required in many realistic applications, such as visual tracking, graph classification, and collaborative filtering. As most of the existing graph neural networks yield effective graph representations of a single graph, little effort has been made for jointly learning two graph representations and calculating their similarity score. In addition, existing unsupervised graph similarity learning methods are mainly clustering-based, which ignores the valuable information embodied in graph pairs. To this end, we propose a contrastive graph matching network (CGMN) for self-supervised graph similarity learning in order to calculate the similarity between any two input graph objects. Specifically, we generate two augmented views for each graph in a pair respectively. Then, we employ two strategies, namely cross-view interaction and cross-graph interaction, for effective node representation learning. The former is resorted to strengthen the consistency of node representations in two views. The latter is utilized to identify node differences between different graphs. Finally, we transform node representations into graph-level representations via pooling operations for graph similarity computation. We have evaluated CGMN on eight real-world datasets, and the experiment results show that the proposed new approach is superior to the state-of-the-art methods in graph similarity learning downstream tasks.