 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearchEVO: An End-to-End Framework for Automated Scientific Discovery and Documentation
Apr 07, 2026An important recurring pattern in scientific breakthroughs is a two-stage process: an initial phase of undirected experimentation that yields an unexpected finding, followed by a retrospective phase that explains why the finding works and situates it within existing theory. We present ResearchEVO, an end-to-end framework that computationally instantiates this discover-then-explain paradigm. The Evolution Phase employs LLM-guided bi-dimensional co-evolution -- simultaneously optimizing both algorithmic logic and overall architecture -- to search the space of code implementations purely by fitness, without requiring any understanding of the solutions it produces. The Writing Phase then takes the best-performing algorithm and autonomously generates a complete, publication-ready research paper through sentence-level retrieval-augmented generation with explicit anti-hallucination verification and automated experiment design. To our knowledge, ResearchEVO is the first system to cover this full pipeline end to end: no prior work jointly performs principled algorithm evolution and literature-grounded scientific documentation. We validate the framework on two cross-disciplinary scientific problems -- Quantum Error Correction using real Google quantum hardware data, and Physics-Informed Neural Networks -- where the Evolution Phase discovered human-interpretable algorithmic mechanisms that had not been previously proposed in the respective domain literatures. In both cases, the Writing Phase autonomously produced compilable LaTeX manuscripts that correctly grounded these blind discoveries in existing theory via RAG, with zero fabricated citations.
Logos: An evolvable reasoning engine for rational molecular design
Mar 10, 2026The discovery and design of functional molecules remain central challenges across chemistry,biology, and materials science. While recent advances in machine learning have accelerated molecular property prediction and candidate generation, existing models tend to excel either in physical fidelity without transparent reasoning, or in flexible reasoning without guarantees of chemical validity. This imbalance limits the reliability of artificial intelligence systems in real scientific design workflows.Here we present Logos, a compact molecular reasoning model that integrates multi-step logical reasoning with strict chemical consistency. Logos is trained using a staged strategy that first exposes the model to explicit reasoning examples linking molecular descriptions to structural decisions, and then progressively aligns these reasoning patterns with molecular representations. In a final training phase, chemical rules and invariants are incorporated directly into the optimization objective, guiding the model toward chemically valid outputs. Across multiple benchmark datasets, Logos achieves strong performance in both structural accuracy and chemical validity, matching or surpassing substantially larger general-purpose language models while operating with a fraction of their parameters. Beyond benchmark evaluation, the model exhibits stable behaviour in molecular optimization tasks involving multiple, potentially conflicting constraints. By explicitly exposing intermediate reasoning steps, Logos enables human inspection and assessment of the design logic underlying each generated structure. These results indicate that jointly optimizing for reasoning structure and physical consistency offers a practical pathway toward reliable and interpretable AI systems for molecular science, supporting closer integration of artificial intelligence into scientific discovery processes.
Machine learning enhanced atom probe tomography analysis: a snapshot review
Apr 19, 2025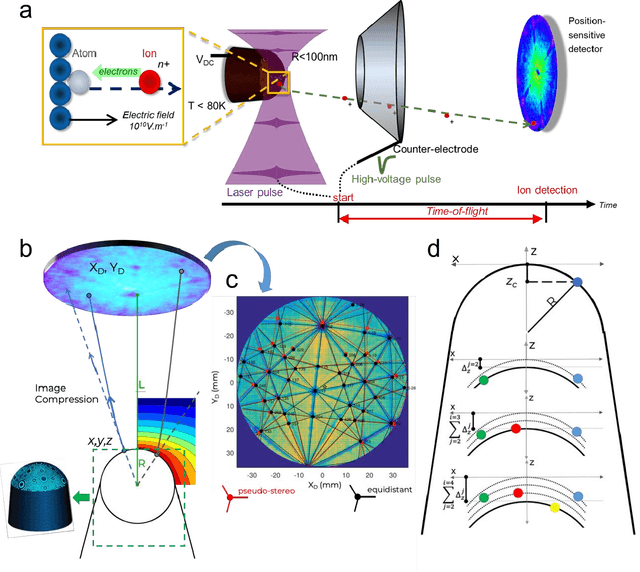
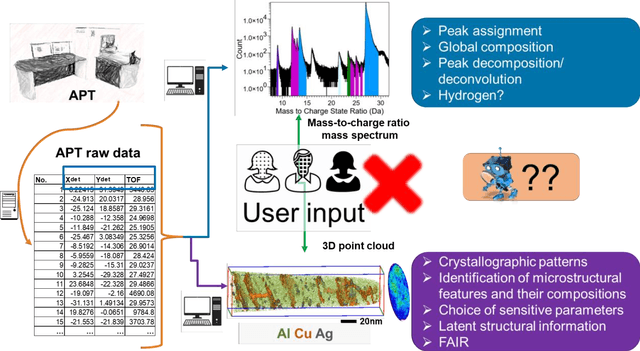
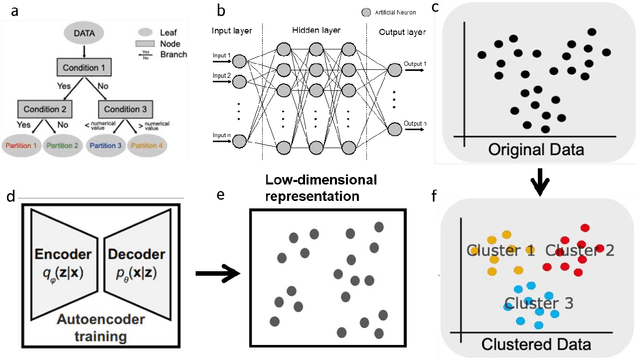
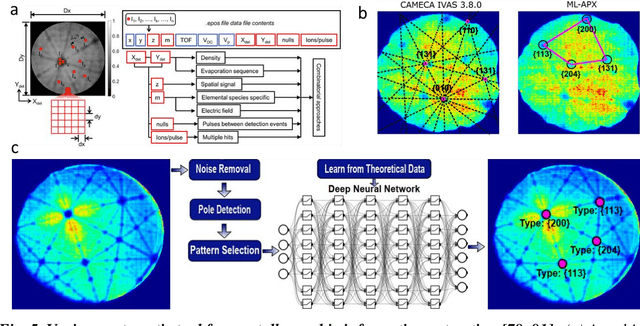
Atom probe tomography (APT) is a burgeoning characterization technique that provides compositional mapping of materials in three-dimensions at near-atomic scale. Since its significant expansion in the past 30 years, we estimate that one million APT datasets have been collected, each containing millions to billions of individual ions. Their analysis and the extraction of microstructural information has largely relied upon individual users whose varied level of expertise causes clear and documented bias. Current practices hinder efficient data processing, and make challenging standardization and the deployment of data analysis workflows that would be compliant with FAIR data principles. Over the past decade, building upon the long-standing expertise of the APT community in the development of advanced data processing or data mining techniques, there has been a surge of novel machine learning (ML) approaches aiming for user-independence, and that are efficient, reproducible, and robust from a statistics perspective. Here, we provide a snapshot review of this rapidly evolving field. We begin with a brief introduction to APT and the nature of the APT data. This is followed by an overview of relevant ML algorithms and a comprehensive review of their applications to APT. We also discuss how ML can enable discoveries beyond human capability, offering new insights into the mechanisms within materials. Finally, we provide guidance for future directions in this domain.
From Understanding to Excelling: Template-Free Algorithm Design through Structural-Functional Co-Evolution
Mar 13, 2025Large language models (LLMs) have greatly accelerated the automation of algorithm generation and optimization. However, current methods such as EoH and FunSearch mainly rely on predefined templates and expert-specified functions that focus solely on the local evolution of key functionalities. Consequently, they fail to fully leverage the synergistic benefits of the overall architecture and the potential of global optimization. In this paper, we introduce an end-to-end algorithm generation and optimization framework based on LLMs. Our approach utilizes the deep semantic understanding of LLMs to convert natural language requirements or human-authored papers into code solutions, and employs a two-dimensional co-evolution strategy to optimize both functional and structural aspects. This closed-loop process spans problem analysis, code generation, and global optimization, automatically identifying key algorithm modules for multi-level joint optimization and continually enhancing performance and design innovation. Extensive experiments demonstrate that our method outperforms traditional local optimization approaches in both performance and innovation, while also exhibiting strong adaptability to unknown environments and breakthrough potential in structural design. By building on human research, our framework generates and optimizes novel algorithms that surpass those designed by human experts, broadening the applicability of LLMs for algorithm design and providing a novel solution pathway for automated algorithm development.
MotionPCM: Real-Time Motion Synthesis with Phased Consistency Model
Jan 31, 2025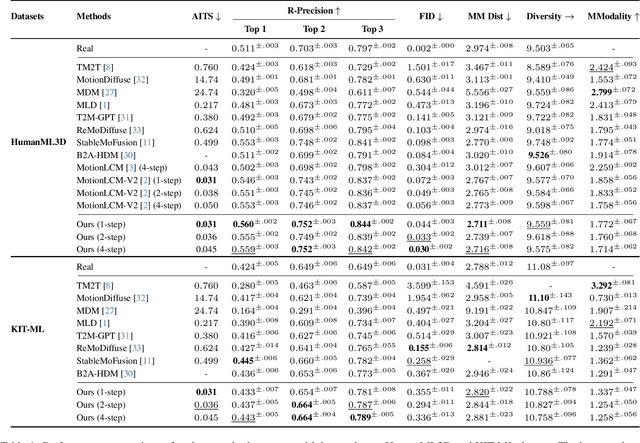
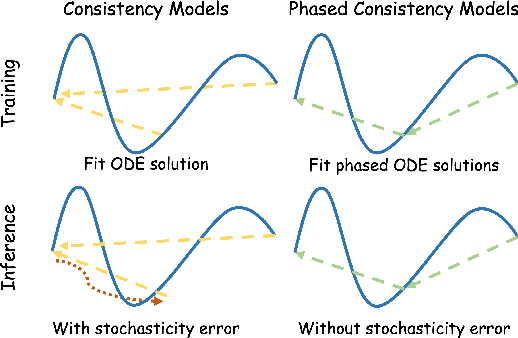

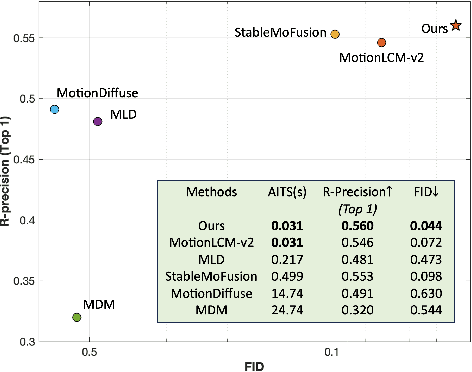
Diffusion models have become a popular choice for human motion synthesis due to their powerful generative capabilities. However, their high computational complexity and large sampling steps pose challenges for real-time applications. Fortunately, the Consistency Model (CM) provides a solution to greatly reduce the number of sampling steps from hundreds to a few, typically fewer than four, significantly accelerating the synthesis of diffusion models. However, its application to text-conditioned human motion synthesis in latent space remains challenging. In this paper, we introduce \textbf{MotionPCM}, a phased consistency model-based approach designed to improve the quality and efficiency of real-time motion synthesis in latent space.
Derivative-free tree optimization for complex systems
Apr 05, 2024



A tremendous range of design tasks in materials, physics, and biology can be formulated as finding the optimum of an objective function depending on many parameters without knowing its closed-form expression or the derivative. Traditional derivative-free optimization techniques often rely on strong assumptions about objective functions, thereby failing at optimizing non-convex systems beyond 100 dimensions. Here, we present a tree search method for derivative-free optimization that enables accelerated optimal design of high-dimensional complex systems. Specifically, we introduce stochastic tree expansion, dynamic upper confidence bound, and short-range backpropagation mechanism to evade local optimum, iteratively approximating the global optimum using machine learning models. This development effectively confronts the dimensionally challenging problems, achieving convergence to global optima across various benchmark functions up to 2,000 dimensions, surpassing the existing methods by 10- to 20-fold. Our method demonstrates wide applicability to a wide range of real-world complex systems spanning materials, physics, and biology, considerably outperforming state-of-the-art algorithms. This enables efficient autonomous knowledge discovery and facilitates self-driving virtual laboratories. Although we focus on problems within the realm of natural science, the advancements in optimization techniques achieved herein are applicable to a broader spectrum of challenges across all quantitative disciplines.
Traffic4cast at NeurIPS 2022 -- Predict Dynamics along Graph Edges from Sparse Node Data: Whole City Traffic and ETA from Stationary Vehicle Detectors
Mar 14, 2023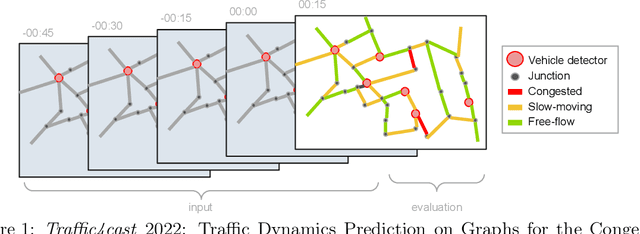
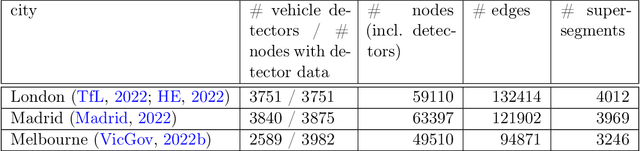
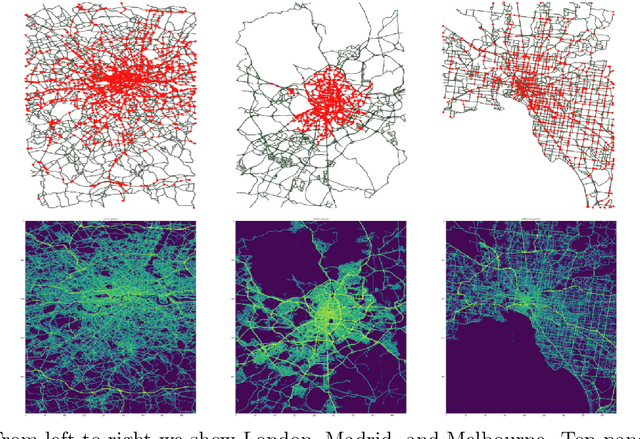
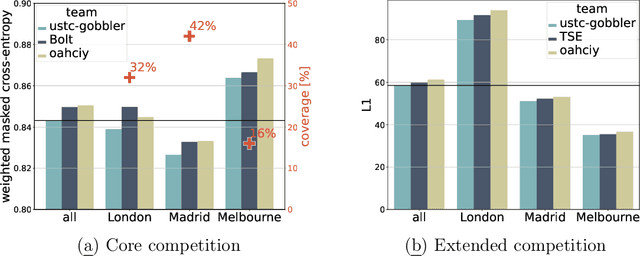
The global trends of urbanization and increased personal mobility force us to rethink the way we live and use urban space. The Traffic4cast competition series tackles this problem in a data-driven way, advancing the latest methods in machine learning for modeling complex spatial systems over time. In this edition, our dynamic road graph data combine information from road maps, $10^{12}$ probe data points, and stationary vehicle detectors in three cities over the span of two years. While stationary vehicle detectors are the most accurate way to capture traffic volume, they are only available in few locations. Traffic4cast 2022 explores models that have the ability to generalize loosely related temporal vertex data on just a few nodes to predict dynamic future traffic states on the edges of the entire road graph. In the core challenge, participants are invited to predict the likelihoods of three congestion classes derived from the speed levels in the GPS data for the entire road graph in three cities 15 min into the future. We only provide vehicle count data from spatially sparse stationary vehicle detectors in these three cities as model input for this task. The data are aggregated in 15 min time bins for one hour prior to the prediction time. For the extended challenge, participants are tasked to predict the average travel times on super-segments 15 min into the future - super-segments are longer sequences of road segments in the graph. The competition results provide an important advance in the prediction of complex city-wide traffic states just from publicly available sparse vehicle data and without the need for large amounts of real-time floating vehicle data.
Predicting the protein-ligand affinity from molecular dynamics trajectories
Aug 19, 2022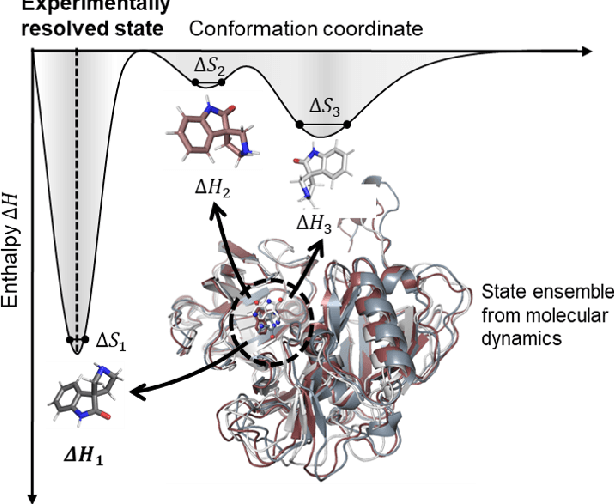
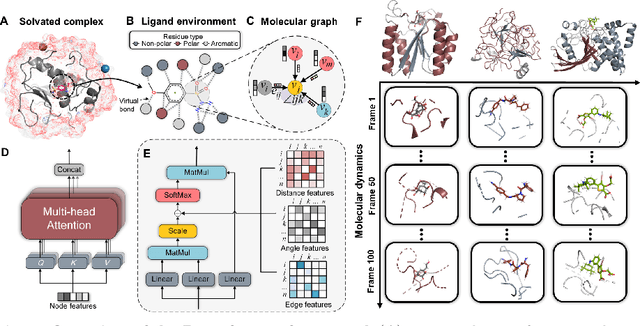
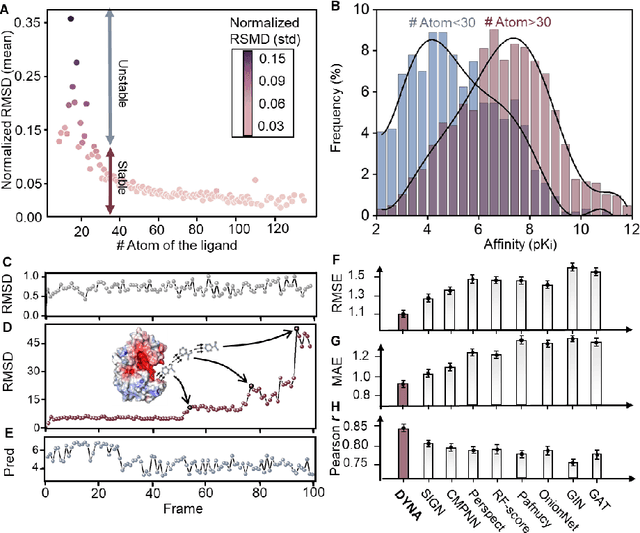
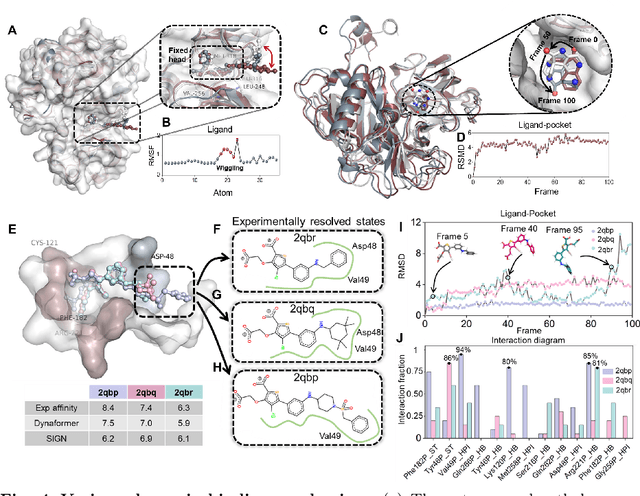
The accurate protein-ligand binding affinity prediction is essential in drug design and many other molecular recognition problems. Despite many advances in affinity prediction based on machine learning techniques, they are still limited since the protein-ligand binding is determined by the dynamics of atoms and molecules. To this end, we curated an MD dataset containing 3,218 dynamic protein-ligand complexes and further developed Dynaformer, a graph-based deep learning framework. Dynaformer can fully capture the dynamic binding rules by considering various geometric characteristics of the interaction. Our method shows superior performance over the methods hitherto reported. Moreover, we performed virtual screening on heat shock protein 90 (HSP90) by integrating our model with structure-based docking. We benchmarked our performance against other baselines, demonstrating that our method can identify the molecule with the highest experimental potency. We anticipate that large-scale MD dataset and machine learning models will form a new synergy, providing a new route towards accelerated drug discovery and optimization.
Machine-learning-enhanced time-of-flight mass spectrometry analysis
Oct 02, 2020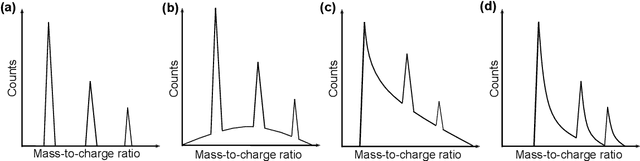



Mass spectrometry is a widespread approach to work out what are the constituents of a material. Atoms and molecules are removed from the material and collected, and subsequently, a critical step is to infer their correct identities based from patterns formed in their mass-to-charge ratios and relative isotopic abundances. However, this identification step still mainly relies on individual user's expertise, making its standardization challenging, and hindering efficient data processing. Here, we introduce an approach that leverages modern machine learning technique to identify peak patterns in time-of-flight mass spectra within microseconds, outperforming human users without loss of accuracy. Our approach is cross-validated on mass spectra generated from different time-of-flight mass spectrometry(ToF-MS) techniques, offering the ToF-MS community an open-source, intelligent mass spectra analysis.
A Dynamic Boosted Ensemble Learning Method Based on Random Forest
Apr 24, 2018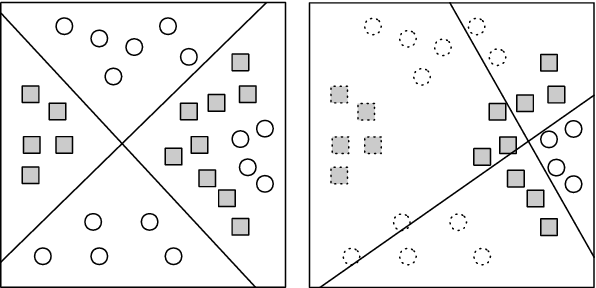
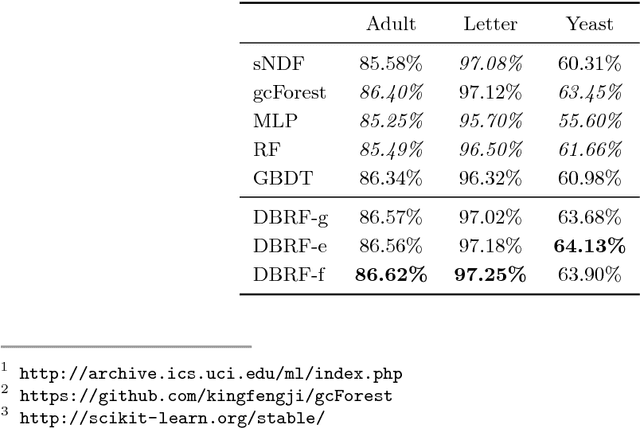
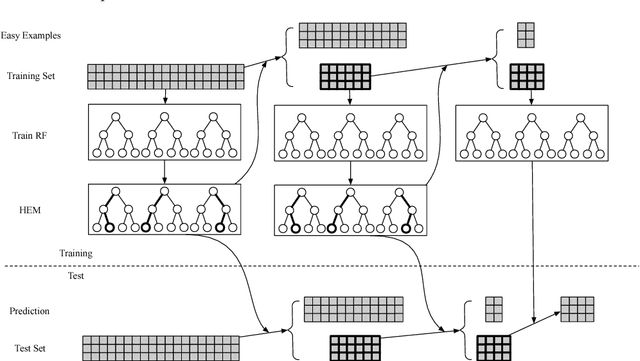
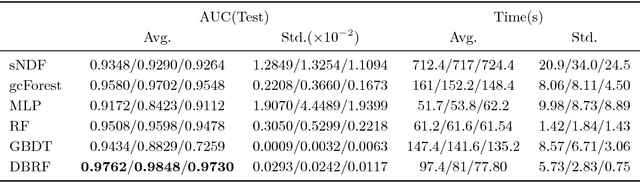
We propose a dynamic boosted ensemble learning method based on random forest (DBRF), a novel ensemble algorithm that incorporates the notion of hard example mining into Random Forest (RF) and thus combines the high accuracy of Boosting algorithm with the strong generalization of Bagging algorithm. Specifically, we propose to measure the quality of each leaf node of every decision tree in the random forest to determine hard examples. By iteratively training and then removing easy examples from training data, we evolve the random forest to focus on hard examples dynamically so as to learn decision boundaries better. Data can be cascaded through these random forests learned in each iteration in sequence to generate predictions, thus making RF deep. We also propose to use evolution mechanism and smart iteration mechanism to improve the performance of the model. DBRF outperforms RF on three UCI datasets and achieved state-of-the-art results compared to other deep models. Moreover, we show that DBRF is also a new way of sampling and can be very useful when learning from imbalanced data.