Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionPCM: Real-Time Motion Synthesis with Phased Consistency Model
Paper and Code
Jan 31, 2025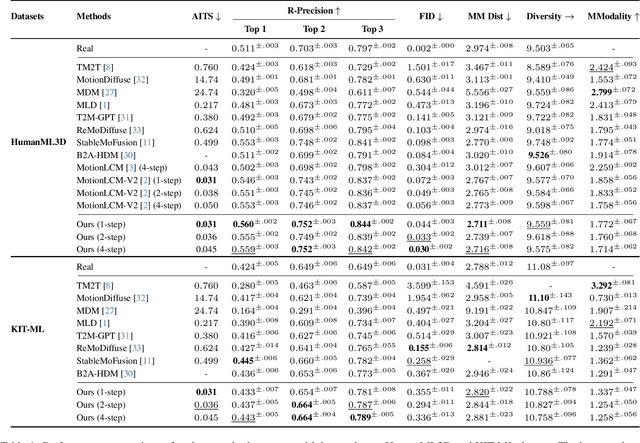
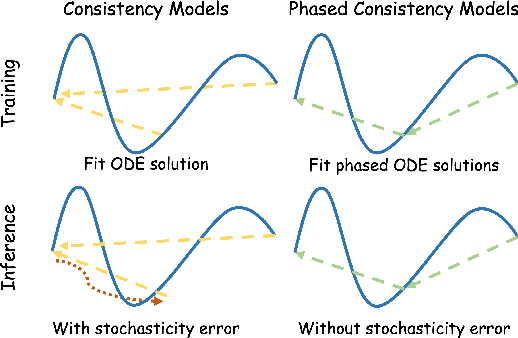

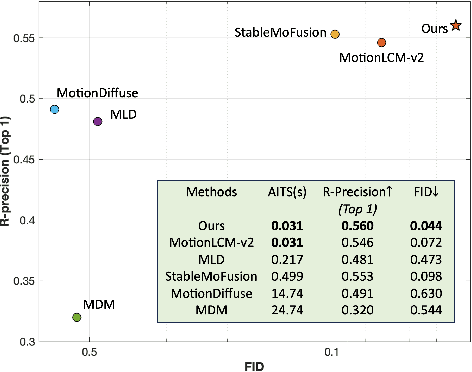
Diffusion models have become a popular choice for human motion synthesis due to their powerful generative capabilities. However, their high computational complexity and large sampling steps pose challenges for real-time applications. Fortunately, the Consistency Model (CM) provides a solution to greatly reduce the number of sampling steps from hundreds to a few, typically fewer than four, significantly accelerating the synthesis of diffusion models. However, its application to text-conditioned human motion synthesis in latent space remains challenging. In this paper, we introduce \textbf{MotionPCM}, a phased consistency model-based approach designed to improve the quality and efficiency of real-time motion synthesis in latent space.
View paper on