 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacilitate Collaboration between Large Language Model and Task-specific Model for Time Series Anomaly Detection
Jan 10, 2025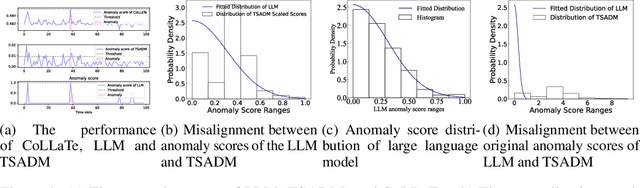
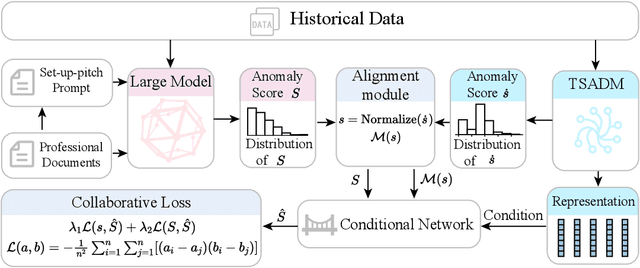
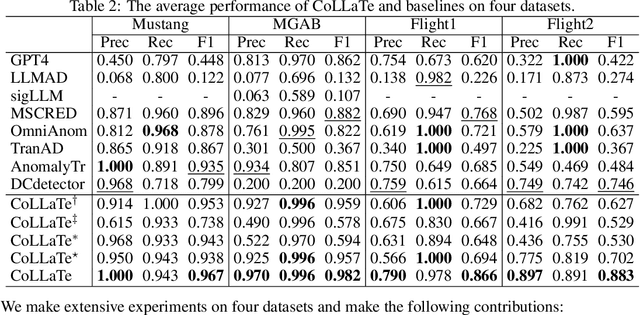
In anomaly detection, methods based on large language models (LLMs) can incorporate expert knowledge, while task-specific smaller models excel at extracting normal patterns and detecting value fluctuations. Inspired by the human nervous system, where the brain stores expert knowledge and the peripheral nervous system and spinal cord handle specific tasks like withdrawal and knee-jerk reflexes, we propose CoLLaTe, a framework designed to facilitate collaboration between LLMs and task-specific models, leveraging the strengths of both. In this work, we first formulate the collaboration process and identify two key challenges in the collaboration between LLMs and task-specific models: (1) the misalignment between the expression domains of LLMs and smaller models, and (2) error accumulation arising from the predictions of both models. To address these challenges, we introduce two key components in CoLLaTe: the alignment module and the collaborative loss function. Through theoretical analysis and experimental validation, we demonstrate that these components effectively mitigate the identified challenges and achieve better performance than LLM based methods and task-specific smaller model.
A Dynamic Boosted Ensemble Learning Method Based on Random Forest
Apr 24, 2018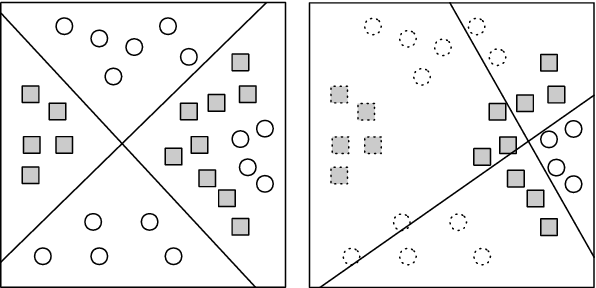
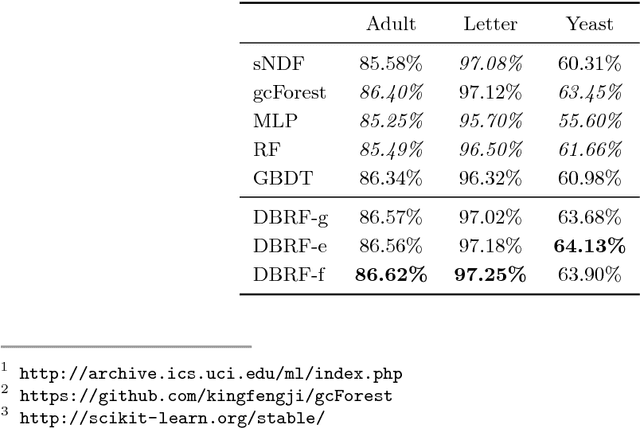
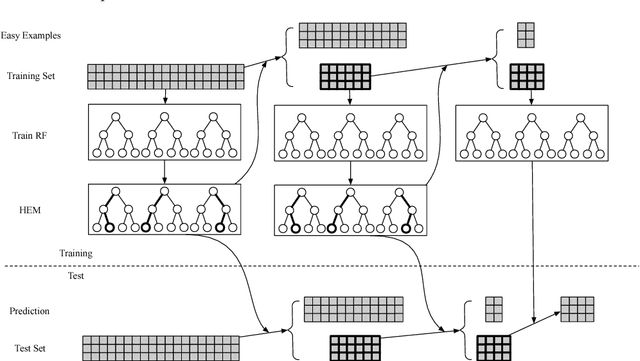
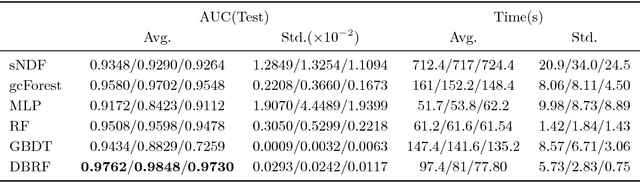
We propose a dynamic boosted ensemble learning method based on random forest (DBRF), a novel ensemble algorithm that incorporates the notion of hard example mining into Random Forest (RF) and thus combines the high accuracy of Boosting algorithm with the strong generalization of Bagging algorithm. Specifically, we propose to measure the quality of each leaf node of every decision tree in the random forest to determine hard examples. By iteratively training and then removing easy examples from training data, we evolve the random forest to focus on hard examples dynamically so as to learn decision boundaries better. Data can be cascaded through these random forests learned in each iteration in sequence to generate predictions, thus making RF deep. We also propose to use evolution mechanism and smart iteration mechanism to improve the performance of the model. DBRF outperforms RF on three UCI datasets and achieved state-of-the-art results compared to other deep models. Moreover, we show that DBRF is also a new way of sampling and can be very useful when learning from imbalanced data.