 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage2Struct: Benchmarking Structure Extraction for Vision-Language Models
Oct 29, 2024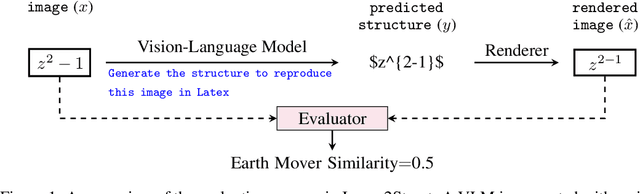

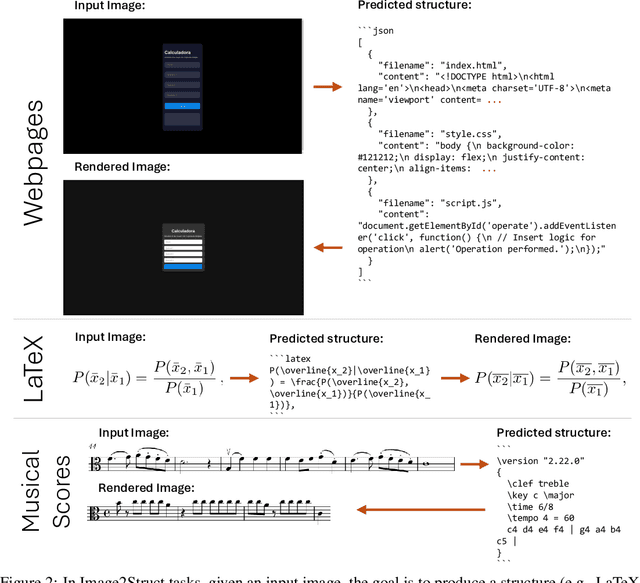
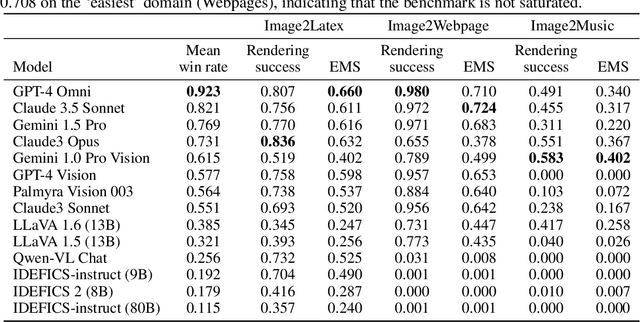
We introduce Image2Struct, a benchmark to evaluate vision-language models (VLMs) on extracting structure from images. Our benchmark 1) captures real-world use cases, 2) is fully automatic and does not require human judgment, and 3) is based on a renewable stream of fresh data. In Image2Struct, VLMs are prompted to generate the underlying structure (e.g., LaTeX code or HTML) from an input image (e.g., webpage screenshot). The structure is then rendered to produce an output image (e.g., rendered webpage), which is compared against the input image to produce a similarity score. This round-trip evaluation allows us to quantitatively evaluate VLMs on tasks with multiple valid structures. We create a pipeline that downloads fresh data from active online communities upon execution and evaluates the VLMs without human intervention. We introduce three domains (Webpages, LaTeX, and Musical Scores) and use five image metrics (pixel similarity, cosine similarity between the Inception vectors, learned perceptual image patch similarity, structural similarity index measure, and earth mover similarity) that allow efficient and automatic comparison between pairs of images. We evaluate Image2Struct on 14 prominent VLMs and find that scores vary widely, indicating that Image2Struct can differentiate between the performances of different VLMs. Additionally, the best score varies considerably across domains (e.g., 0.402 on sheet music vs. 0.830 on LaTeX equations), indicating that Image2Struct contains tasks of varying difficulty. For transparency, we release the full results at https://crfm.stanford.edu/helm/image2struct/v1.0.1/.
VHELM: A Holistic Evaluation of Vision Language Models
Oct 09, 2024



Current benchmarks for assessing vision-language models (VLMs) often focus on their perception or problem-solving capabilities and neglect other critical aspects such as fairness, multilinguality, or toxicity. Furthermore, they differ in their evaluation procedures and the scope of the evaluation, making it difficult to compare models. To address these issues, we extend the HELM framework to VLMs to present the Holistic Evaluation of Vision Language Models (VHELM). VHELM aggregates various datasets to cover one or more of the 9 aspects: visual perception, knowledge, reasoning, bias, fairness, multilinguality, robustness, toxicity, and safety. In doing so, we produce a comprehensive, multi-dimensional view of the capabilities of the VLMs across these important factors. In addition, we standardize the standard inference parameters, methods of prompting, and evaluation metrics to enable fair comparisons across models. Our framework is designed to be lightweight and automatic so that evaluation runs are cheap and fast. Our initial run evaluates 22 VLMs on 21 existing datasets to provide a holistic snapshot of the models. We uncover new key findings, such as the fact that efficiency-focused models (e.g., Claude 3 Haiku or Gemini 1.5 Flash) perform significantly worse than their full models (e.g., Claude 3 Opus or Gemini 1.5 Pro) on the bias benchmark but not when evaluated on the other aspects. For transparency, we release the raw model generations and complete results on our website (https://crfm.stanford.edu/helm/vhelm/v2.0.1). VHELM is intended to be a living benchmark, and we hope to continue adding new datasets and models over time.
Learning production functions for supply chains with graph neural networks
Jul 26, 2024The global economy relies on the flow of goods over supply chain networks, with nodes as firms and edges as transactions between firms. While we may observe these external transactions, they are governed by unseen production functions, which determine how firms internally transform the input products they receive into output products that they sell. In this setting, it can be extremely valuable to infer these production functions, to better understand and improve supply chains, and to forecast future transactions more accurately. However, existing graph neural networks (GNNs) cannot capture these hidden relationships between nodes' inputs and outputs. Here, we introduce a new class of models for this setting, by combining temporal GNNs with a novel inventory module, which learns production functions via attention weights and a special loss function. We evaluate our models extensively on real supply chains data, along with data generated from our new open-source simulator, SupplySim. Our models successfully infer production functions, with a 6-50% improvement over baselines, and forecast future transactions on real and synthetic data, outperforming baselines by 11-62%.